
The pragmatic decision-maker’s guide to understand and act
January 2024 - 1.1.4
Dear colleagues, dear friends,
There are those adventures that could not succeed without the rigor and dedication of a few. You have been those few. By agreeing to read and reread this manuscript, by sharing your constructive criticism, your informed suggestions and during our enriching discussions, you have largely contributed to its success.
Through your expert eyes, I was able to sharpen every line, polish every word. Your support has been a pillar, a silent and unwavering force. Many thanks for your time, expertise and camaraderie.
It is because this writing is also partly yours that I wanted to mark it with the names of the most tireless contributors. However, in order to preserve your anonymity, I have chosen to only include your initials. Thank you BA, FT, MR, FC, FP, NK, AB, AC, NP, NM, CH, EL, PB, AN and TF.
This book includes numerous references and web links to people, products, companies and organizations. The opinions expressed in this book are those of the author and do not in any way reflect the opinions of the entities mentioned.
The author has no affiliation with any companies mentioned in this book, whether by partnership, sponsorship, or any other arrangement. Any mention of a company or product is strictly informative and should not be construed as promotion in any way.
Transparency seems essential to me in any research and writing work, and I wish my readers to be informed of my lack of affiliation with the organizations cited in my work.
![]()
The constant evolution of technology requires organizations to reinvent themselves. They are forced to respond ever more quickly - and often without increasing resources - to their operational requirements. Strategists are mobilizing to stay ahead of the curve in the face of ever-fiercer competition.
Many organizations have already started their digital transformation to master the complexity of interdependent and fragmented information systems. DevOps is one of the approaches to achieving this goal and working more efficiently.
Appearing in 2007, this cultural and organizational movement allows an organization’s stakeholders to work more effectively to achieve its objectives more quickly.
Thanks to several theorized methods, DevOps constitutes a means of responding to this efficiency challenge. Each aims to improve the relevance and reliability of the services offered by the organization. To enable it to be more agile, DevOps takes full advantage of Cloud technologies: mostly open, proven, standardized, and attractive.
According to the consulting and research company Gartner, more than 85% of organizations will adopt a Cloud strategy by 20251. Atlassian’s survey revealed that 99% of companies believe DevOps positively impacts their organization2.
Several initiatives to create sovereign Cloud platforms are taking shape around the world. This is for example the case of MeghRaj in India (2014), Bundescloud in Germany (2015), JEDI in the United States (2017) , Nimbus in Israel (2020), GAIA-X in Europe (2020), the Riigipilv in Estonia (2020), Outscale, Athea, and S3NS in France (2010, 2017 and 2021), the Government Cloud in Japan (2021), the National Strategic Hub in Italy (2022). At the heart of these infrastructures, there is unanimous agreement on an organizational structure to unify practices and orchestrate these technologies: DevOps.
More widely used in the private sector, the major cloud providers (Amazon Web Services, Google Cloud Platform, Microsoft Azure, Alibaba Cloud) internally practice this organizational, promote it, and provide the technologies to adopt it.
South Korea has historically favored the use of private cloud technologies, especially since its 2015 law that facilitated outsourcing3. Owing to multiple overlapping investments, outdated information systems, and a shortage of cybersecurity experts within the country, South Korea established national data centers in 2007. These centers now accommodate the information systems of 45 government agencies4. In the wake of the COVID-19 crisis, in 2021, the country announced an ambitious digital transformation plan for its administration: the Digital Government Master Plan 2021-20255. This strategic plan introduces a technical framework named eGovFrame designed for the development and management of government information systems. One of its primary objectives is to enhance their interoperability, and it intrinsically incorporates DevOps principles.
In an effort to regain sovereignty, other governments display a clear desire to adopt these technologies and practices, without necessarily describing their initiatives in public. These desires take shape within documents mentioning the Cloud, AI, or data strategy of the countries.
For example, Canada released its “Goal 2020”6 report in 2013 to modernize the manner in which public services operate. It later released the “Cloud Adoption Strategy”7 in 2018.
In the UK, the Ministry of Defence announced in 2022 its intention to become an “AI-ready” organization, in its “Defence Artificial Intelligence Strategy”8. In the way it describes its transformation, it perfectly captures the essence of DevOps.
« We must change into a software-intensive enterprise, organised and motivated to value and harness data, prepared to tolerate increased risk, learn by doing and rapidly reorient to pursue successes and efficiencies. We must be able to develop, test and deploy new algorithms faster than our adversaries. We must be agile and integrated, […] » - UK Ministry of Defence, chapter “Culture, Skills and Policies”, page 17.
As early as 2018, the UK Ministry of Defence launched the NELSON9 program to equip themselves with a big-data platform for the benefit of the Royal Navy. This technical environment, based on Cloud technologies, also incorporates DevOps practices.
Across the Atlantic, the United States had already recognized the need in 2011 to manage information in a unified and agile manner, accessible via a single access point (see chapter “Zero trust”). The Department of Defense (DoD) outlines this vision in its “DoD IT Enterprise Strategy and Roadmap”10.
« Twenty-first century military operations require an agile information environment to achieve an information advantage for personnel and mission partners. […] To meet this challenge, DoD is undertaking a concerted effort to unify its networks into a single information environment that will improve both operational effectiveness and information security posture. »
- United States Department of Defense, chapter “Vision for a more Effective, Efficient and Secure DoD Information Enterprise”, page 4.
It will publish in 2019 his first reference guide for the industrialization of DevSecOps practices11: a methodology emphasizing security (see chapter “DevSecOps”). Aimed at providers, buyers, and managers of modern information systems, this institutional guide describes best practices for the implementation and maintenance of such systems. The stated goal is to deploy software at the “speed of operations”. In the economic environment, the parallel is that of the “speed of stock markets”.
In the private sector, Microsoft historically launched its new products every 3 to 4 years (e.g., Windows, Office). As early as 2014, its CEO Satya NADELLA warned his teams about the risk posed by the long duration of this development cycle. By continuing with the same organization mode, Microsoft would become obsolete. The teams responsible for developing each product worked independently from one another, with their own organizational methods and their own tools. NADELLA reorganized the company based on the DevOps methodology. He would unify the tools and practices of the teams, so they would interact with each other12.
Faced with increasingly aggressive economic13 or military14 competitors, transformation is an imperative necessity to stay in the race and prevail in the next confrontations. For institutions, it is no longer a question of “if” but “when” they will need to embark on a transformation journey, or risk being left behind.
However, the majority of organizations still struggle to pragmatically implement these new practices. The main obstacle is finding the talents capable of implementing the techniques and tools suitable for DevOps operation.
There are numerous studies to refer to on DevOps, which is primarily a topic of cultural transformation for technical and management teams. These studies draw upon the experiences of many players and allow us to avoid common mistakes in a transformation approach.
For instance, Google Cloud’s DORA15 research program (DevOps Research & Assessment) has been conducted since 2014 with over 33,000 professionals in the Cloud sector. Each year, its report on the state of DevOps worldwide is published. Therefore, this field is far from new, and the initial risk is now much more moderate for newcomers. However, the industry continually finds ever-more effective ways to transform, to keep pace with the rapid advancements in the digital sector.
This book aims to demystify both the organizational and technical aspects of DevOps. These concepts are accessible to all and will provide you with an overview of the Cloud’s challenges for a successful transformation. It offers guidance for a first-time DevOps experiment or to refine an ongoing transformation.
We will explore the reasons for the emergence of this methodology, its content, and how to inspire your organization to transform. Every organization has its own needs, its own maturity level, and there is no one-size-fits-all solution. Nevertheless, the industry’s successive experiences have led to the creation of standards that will be presented throughout this book.
The experience of pioneering companies now ensures that efforts invested in DevOps will make your organization more efficient, agile, and sustainable.
According to the renowned American company Atlassian16, the DevOps movement was born between 2007 and 2008. It was a time when software development professionals (those who develop) and system administrators (those who deploy) were each concerned about their poor ability to collaborate. They viewed this situation as a critical dysfunction, stemming from their lack of closeness.
Initially, DevOps focused on how to improve the efficiency of software development and deployment. More than a decade later, this methodology has evolved to address other areas such as security, Cloud infrastructures, and corporate culture. Around 2015, the DevOps methodology was primarily employed by major American tech companies (GAFAM17 and NATU18) or businesses that were already using the agile methodology.
Now widespread, organizations of all sizes use the DevOps methodology worldwide and across various sectors19 (healthcare, finance, transportation, government, heavy industry…).
The term DevOps is attributed to Belgian engineer Patrick DEBOIS. As a consultant in 2007 for the Belgian government, he was tasked with migrating a data center. After spending significant time discussing with developers and system administrators, he observed what renowned engineers Andrew CLAY SHAFER and Lee THOMPSON would later theorize two years afterward as the “wall of confusion”20. This metaphor can be summed up as stakeholders not understanding each other.
The community coined a term for a real phenomenon that hinders communication and collaboration between teams, resulting in inefficiencies and delays. This led to the writing of his book in 2015, “The DevOps Handbook: How to Create Technologically Agile, Reliable, and Secure Organizations”21. In it, DEBOIS describes how organizations can increase profitability, improve their corporate culture, and surpass their goals using DevOps practices.
Google theorizes five pillars of DevOps:
To fully understand how DevOps can benefit your organization, let’s start by defining two of the most important terms in the field: DevOps and SRE.
It bridges the gap between development and production.
“Dev” stands for “development” while “Ops” refers to the administration of IT systems in production.
“DevOps” (Development and Operations) denotes the organizational and cultural movement aimed at streamlining the software development and deployment cycle.
To achieve this goal, engineers practicing DevOps are tasked with facilitating communication and collaboration among stakeholders (developers, system administrators, security teams, project managers, and users).
They identify the most relevant IT practices and tools for an organization and study their implementation. As a team, they ensure the alignment of developments with deployment requirements. Today, these professionals primarily focus on the use of Cloud technologies.
DevOps practices span the entire technical chain, emphasizing automated mechanisms for development (e.g., continuous integration), deployment (e.g., continuous deployment), and maintenance (e.g., monitoring). Both internal teams and clients benefit. The former collaborate more effectively and securely, while the latter receive higher-quality software more promptly.
This role involves the responsibility of aligning all stakeholders on a common working method. Hence, possessing strong communication and teaching skills is vital, especially in transforming organizations.
DevOps engineering aims to make the entire organization aware of system reliability issues. The most experienced engineers can establish practices that meet resilience requirements without affecting development velocity.
The main challenge lies in striking a balance between complexity induced by reliability and security requirements and the need to develop new features.
In the next part of this book, we’ll see that the implementation of DevOps is unique to each organization. To reach these goals, methods and tools adjust according to the organization’s technical maturity level. There’s no “one-size-fits-all” approach, but there are “best practices” to know and follow.
Just as there isn’t a single recipe, there isn’t a unique “DevOps engineer” profession. We’ll touch upon this topic in the chapter “Between SRE and DevOps”.
While the term DevOps is becoming increasingly popular and is starting to appear commonly in job offers, Site Reliability Engineering (SRE) is less well-known, particularly in France.
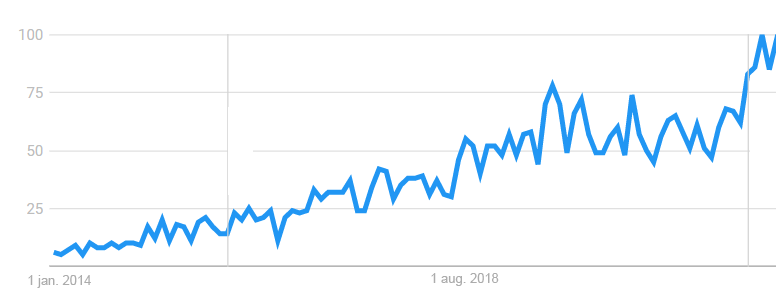
System Reliability Engineering (SRE) is an older discipline than DevOps. It traces back to 2003 when Ben TREYNOR SLOSS, then an engineer at Google, founded a team bearing this name. He is recognized as the founding father of SRE and the earliest practices considered as “DevOps”.
The Site Reliability Engineer is responsible for designing, deploying and maintaining the infrastructure that makes the company’s services available. He ensures the proper functioning of the technical base on which the software is deployed. It ensures their security and guarantees their availability to customers.
The SRE team, therefore, is responsible for your IT infrastructure, typically comprising several environments: development, testing, pre-production (or staging), and production. They aim to answer the question, “what are the things (tools, procedures, machines) that we don’t have, but need to achieve our resilience goal?”
SREs employ software engineering practices to manage their infrastructures. They develop and deploy tools aimed at achieving a resilience objective. In this regard, SRE encompasses many facets of DevOps (see chapter “The 5 pillars of DevOps”), but focuses on the automation of administration, as well as the measurement of system reliability.
Companies primarily hire them to honor their service contract (Service Level Agreement, see chapter “Resilience indicators”). In the private sector, if service availability drops below the value stipulated in the contract (e.g., below 99% monthly availability), the company is obligated to pay penalties.
In simpler terms, companies task SREs with making their infrastructure more resilient, meaning ever more available and stable. SREs seek to answer the following question: “what are the things (tools, procedures, machines) that we don’t have, but need to achieve our resilience goal?”
DevOps practices are an excellent means to reach this goal, which is why SREs often employ them in their daily work.
Definitions vary depending on who you ask. While some leaders like Google and AWS officially define DevOps as a “methodology” and the role of SRE as its “implementation”22, the majority of job listings in the market often still use the title “DevOps Engineer”: a title that is incomplete in the strict sense of the historical definition.
The fact is that both disciplines have evolved and overlap in many areas today: they share the goal of rapidly deploying reliable and efficient software.
However, they don’t focus entirely on the same things. While DevOps leans more towards development efficiency and deployment speed (see CI/CD, automated tests, developer experience, cross-team collaboration…), SRE focuses on system reliability, adopting a more methodical approach (see SLI/SLO/SLA, error budgets, blue/green deployments, postmortems…).
Today, you might find “DevOps Engineers” who don’t do SRE, but the reverse is rare. As DevOps is a philosophy, this term should be used as an adjective. For instance: “DevOps Software Engineer” or “DevOps System Administrator”.
However, let’s see what the market has to say. By observing job listings in the field23, it’s noticeable that those titled “DevOps Engineer” involve a wide range of tasks. They might be:
In reality, all these roles enable the practice of DevOps. However, the presence of each within an organization depends on its maturity and resources (fig.
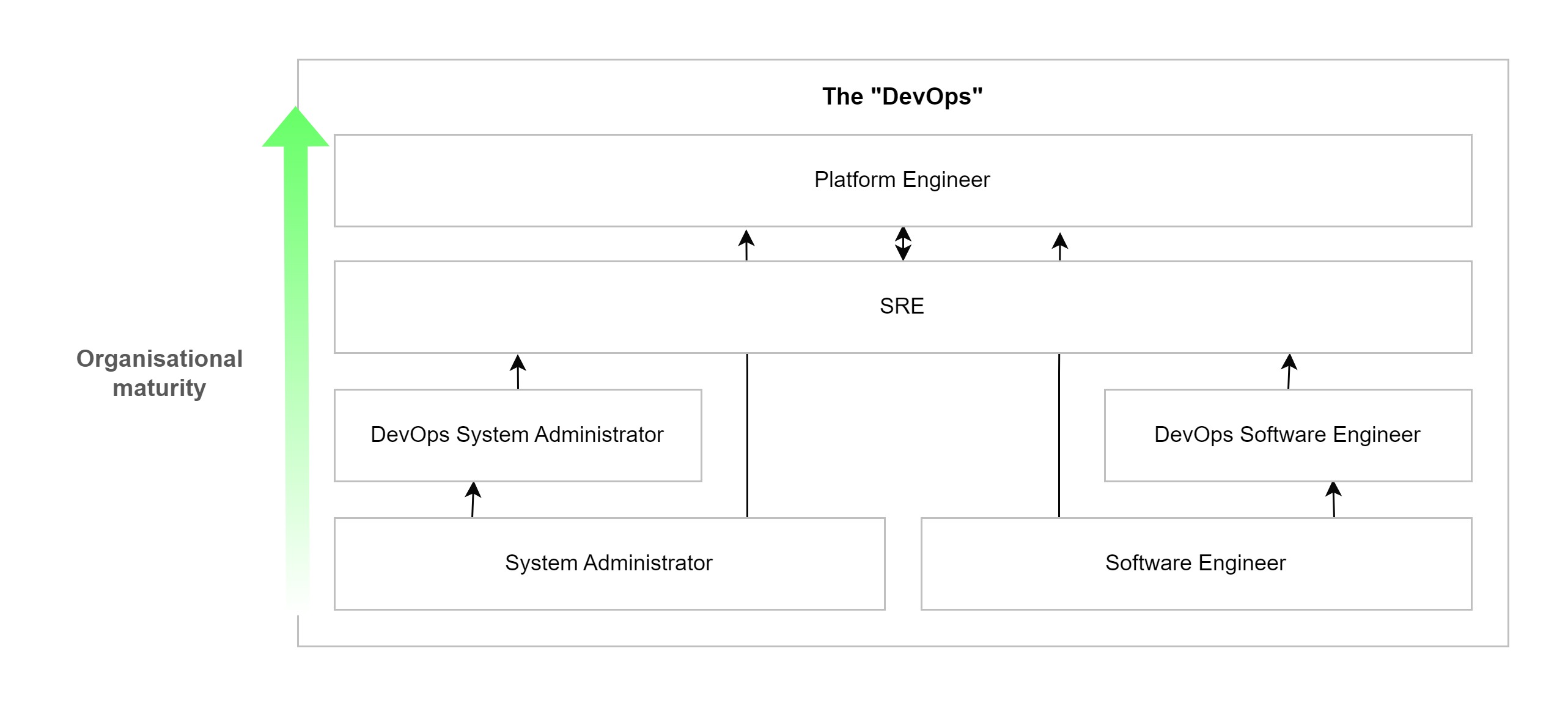
In summary, it’s said that SRE utilizes DevOps methods25. DevOps and SRE are neither opposing nor identical methods, but two disciplines that will help you break down barriers between your teams. This will allow you to deploy services faster, more securely, and of higher quality.
In this book, you will discover best practices from these unified disciplines, tailored to institutions.
The term DevSecOps is gaining in popularity. It describes a DevOps organizational approach that integrates Information Systems Security (ISS) teams from the software design phase and throughout its lifecycle.
More specifically, it ensures compliance with security standards set by the organization, using automated rules that verify the compliance of developed software.
Perhaps you’ve heard of “shift left security”? This term emphasizes the importance of incorporating security efforts into a software project as early as possible (best practices, vulnerability analyses, audits).
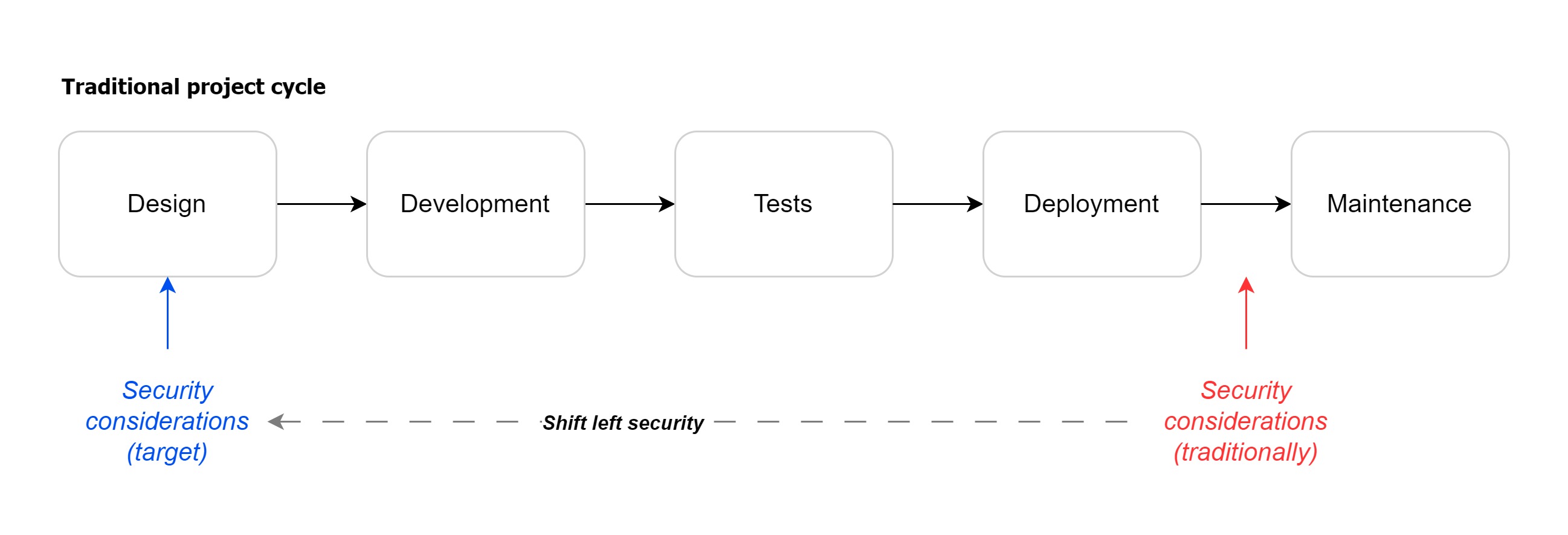
Organizationally speaking, this method places the ISS teams at the heart of the exchanges between developers and production teams. These teams will support the developers to integrate the organization’s security requirements into their software as seamlessly as possible.
From the design phase, the DevSecOps ISS teams define and provide tools that monitor the presence of privacy and security features in the software. For example, they will check for GDPR26 functionalities in a software or the proper functioning of the “need-to-know” mechanism for data access. This can also include the implementation of automatic vulnerability detectors in the code.
Nicolas CHAILLAN, former Director of Software Engineering at the United States Air Force (USAF) defines it27 this way :
“DevSecOps is the evolution of software engineering. It’s the balance between development velocity and the time allocated to security considerations. We want security to be integrated to ensure it’s not overlooked but added to the software development cycle. It’s about using modern cybersecurity processes to ensure the software is both efficient and built securely, ensuring it remains problem-free over time. This is what will allow companies and organizations to remain competitive and move forward at the necessary speed against their competitors.”
Today, the term “DevSecOps” is often favored with the sole aim of making the discipline more attractive. However, it can help Information Systems Security (ISS) teams and their managers understand they have a concrete role to play in this type of organization. It’s the “Sec” in the middle of “DevSecOps”.
Author’s Note: I consider security to be inherent to any information system, so I see the “Sec” in “DevSecOps” as implied. That’s why I will rarely use this term throughout this book.
We will discuss the paradigm of this organizational structure and its security techniques in the chapter “Security: a new paradigm with the DevOps approach”. But before that, let’s learn more about the organizational challenges of DevOps.
A DevOps initiative is a significant transformation for an organization. If it hasn’t yet transitioned to agile mode, it involves every layer of the company to foster shared synergies.
DevOps doesn’t just bring together “Dev” (software engineers) and “Ops” (system administrators), but primarily the management layer. Management needs support in understanding the opportunities presented by a change that’s often perceived as challenging because it’s unfamiliar. In most cases, this transformation requires a significant evolution of the organization’s IT systems in the long run, as it involves the adoption of new tools.
Empathy is the key skill for a successful transformation. For some, these new work methods and tools are in stark contrast to their traditional practices.
That’s why it’s crucial to frequently educate the hierarchy on the benefits of shifting to DevOps: demonstrate it to them, answer all their questions, and support them until they fully grasp its implications.
Every organization benefits from addressing new technological challenges. In the face of ever-modern and swift competition, your entity will not dominate by resting on its laurels.
Research reports support the theory that the benefits of efforts invested in SRE become apparent in the medium term28.
According to these, practicing SRE does not affect an organization’s resilience until a certain maturity level has been reached. This means that one needs to achieve a critical mass before being able to reap the benefits of these tools and practices (fig.
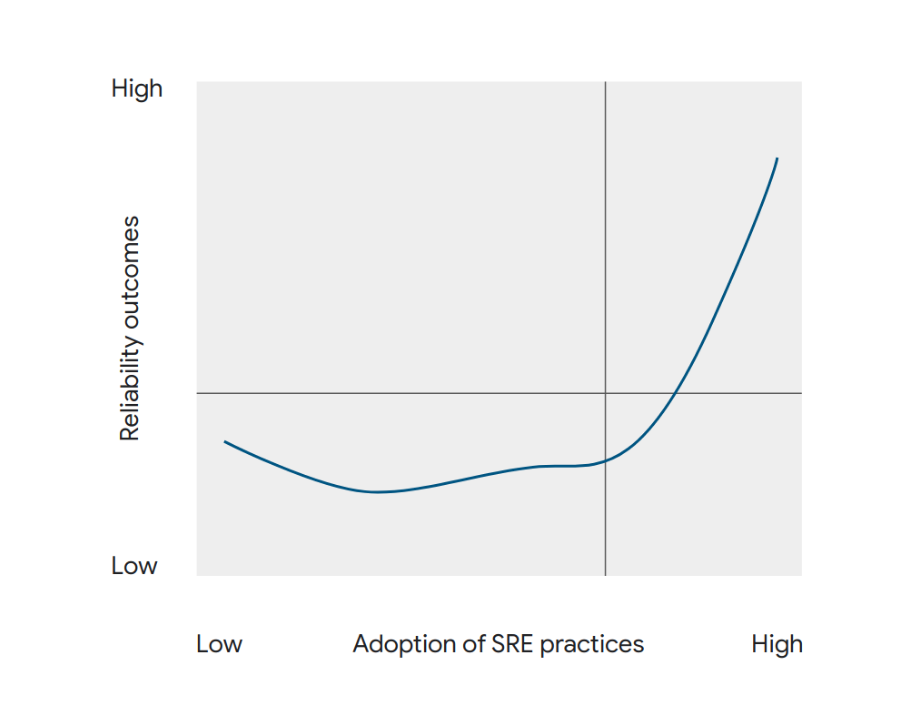
The DORA 2022 report highlights the need to adopt a substantial number of SRE practices before harvesting “significant” resilience benefits29. This phenomenon can deter decision-makers from transitioning to a DevOps model.
Where interest is confirmed is that the benefits yielded by DevOps exceed the costs once the initial investments are made.
This trend is precisely where DevOps shines: even though traditional infrastructures initially require little investment to provide a service, the cost (in terms of human resources and financially) of maintaining them increases proportionally to the number of services deployed. This makes their management unsustainable in the long run. DevOps, on the other hand, requires a higher initial investment but provides the ability to manage exponential activity with a logarithmic cost trend (fig.
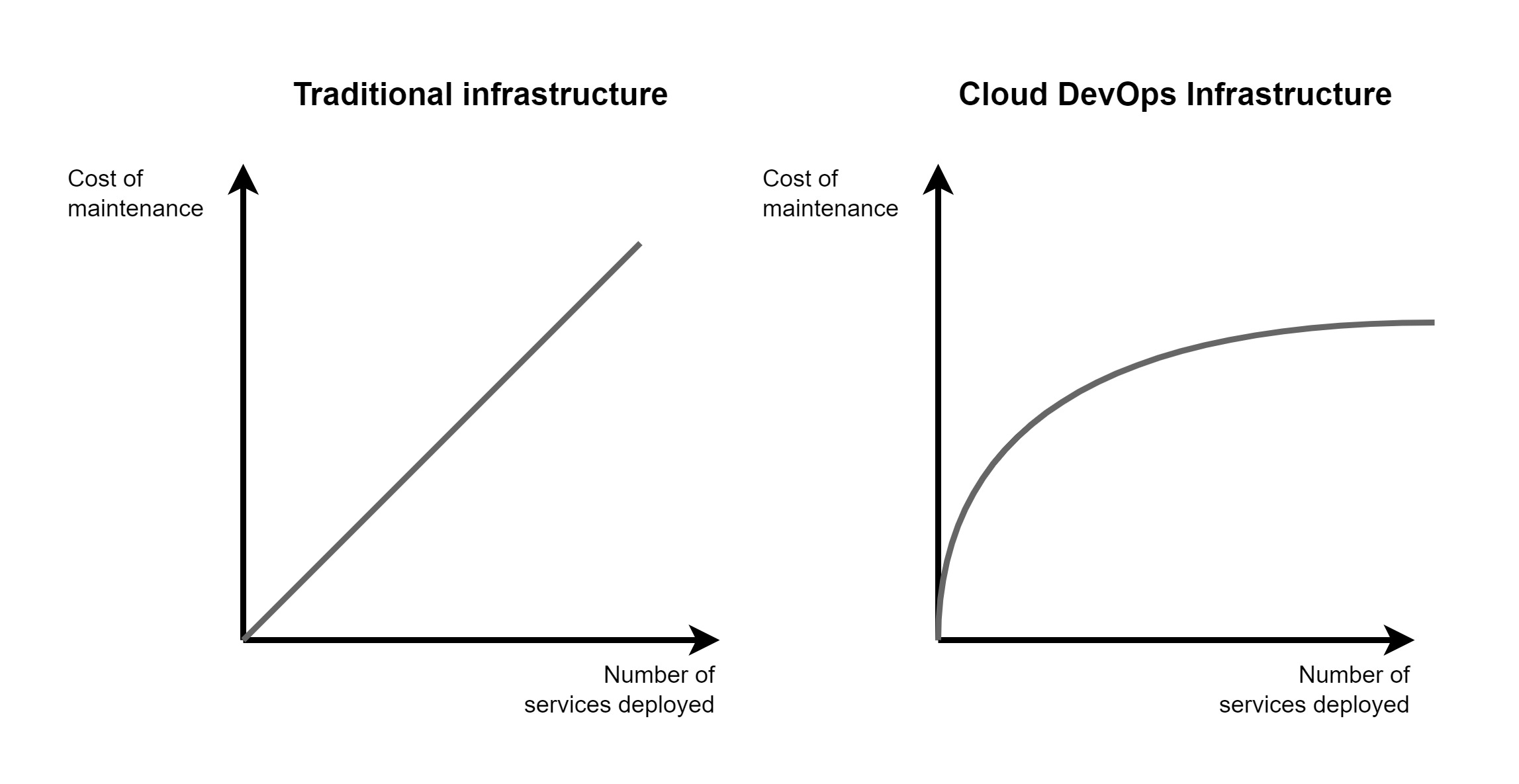
This organizational mode aims to make infrastructures more reliable, reduce manual tasks to make the most of engineers’ time, deploy software faster, and ultimately, deliver a better-quality service.
DevOps to traditional infrastructures is what assembly line construction is to craftsmanship: by constructing on an assembly line, costs are reduced, and demand is met. The added advantage in software is that one can adjust the product to be delivered within a few hours. This action can be repeated several times a day!
While historic practices deserve credit for running information systems for years, more agile methods exist today30. To militarize the argument: bows and arrows served their purpose, but since then, armies have invented the AR-1531.
The challenge of transformation is to get your hierarchy to buy into this initial (significant but necessary) investment, even when the benefits might initially be hard to see. This is a common challenge that we will address in the chapter “How to convince and keep the faith”.
Companies are typically aware of the changes they need to implement. However, they either hesitate or are unable to immediately commit to the necessary efforts to achieve this transformation.
The most skeptical or overly optimistic believe they can get by by starting a cost-effective initiative:
“I only need one SRE/Cloud/DevOps engineer.”
Sorry, no.
Let’s use an example to illustrate this scenario. You start with a 2-person team developing software. Several issues are already identified, especially if you’re operating in a regulated sector:
If you rely solely on your software engineers to manage infrastructure, they will inevitably accrue technical debt since it’s not their core competency. This debt incurs costs and maintenance efforts, which worsen as your team grows. Developers won’t focus on development but will spread thin on tasks meant for an SRE. This scenario already calls for at least 1 SRE/DevOps engineer.
What if you hired more and now have a team of 6 engineers? They need machines set up and configured. Some encounter bugs, others request library updates… If there are security mandates (e.g., approvals, event logs), time must be spent setting up tools and infrastructure properly. This calls for at least one additional SRE/DevOps engineer.
Two engineers leave your company? Unfortunately, you still have to maintain the evolved infrastructure for your remaining 4 engineers and all the machines or servers you’ve set up.
Understand that you need to achieve a critical mass of SRE/DevOps profiles to sustain a robust foundation. This foundation enables your engineers to have the necessary tools to work efficiently. This critical mass should adjust based on staff size and can’t be reduced without facing significant operational challenges.
The debate often circles back to “quality or quantity?”. History of global armed conflicts demonstrates that both are often necessary32. Armies need a critical mass of soldiers and equipment to establish favorable power dynamics and compensate for losses to keep advancing. Though high-quality equipment can accomplish more, it can’t handle everything simultaneously. The same goes for an engineering team. No matter how brilliant, a critical size is needed to meet the basic requirements for an efficient and resilient service.
For instance, Google, with tens of thousands of engineers, maintains its SRE-to-developer ratio at about 10%33. This SRE/developer ratio and associated costs are initially high at the outset of your initiative but tend to level off as the number of deployed services grows. This is due to the strong infrastructure needs at the start of your initiative, which decrease as administrative tasks become automated.
It’s proven that transitioning a traditional structure to DevOps demands significant investment. Establishing the foundation to reap its benefits also takes time. However, remember that the essence of DevOps practices is to manage exponential growth with logarithmically trending costs (see chapter “Why DevOps?”).
The failure of a project is often due to a poorly defined scope, with overly ambitious objectives or unclear planning. This mismanagement leads to uncontrolled increases in timeframes and costs. It then becomes common to seek an “interim solution” while hoping that the initial plan might eventually come to fruition.
A DevOps initiative is built upon what already exists within your institution: the key is to start small to accurately understand the needs of the business and to bring the entire organization on board. This approach is the Kaizen method, originated in Japan during the 1950s within Toyota factories. In France, it’s known as the “strategy of small steps”.
Dare to start small and iterate as both you and your institution become more familiar with the challenges and nuances of these new technologies. Ensure that each team becomes an advocate for your initiative. We will discuss the theories behind this recommendation in the chapter “How to persuade and keep the faith”.
Changing the culture of an organization takes time, but taking shortcuts may offend, demotivate your teams, and ultimately, cause your project to fail. Since DevOps is based on the principle of successive iterations, you’ll be taking fewer risks.
Has your management been convinced by your transformation initiative and granted you all the necessary resources? If so, move on to the next chapter. If not, let’s delve deeper to understand why.
It may happen that newly appointed decision-makers ask their subordinates to “quickly” find turnkey solutions to the problems they encounter. Rather than adopting an investigative approach, the urgency of obtaining immediate results leads them to make hasty decisions. After all, a leader is expected to quickly and effectively find cost-effective solutions. Most of the time, however, initiatives - of varying maturity - already exist within the organization.
Technical solutions are easy to design and delegate. Instead of considering historical proposals, purchasing “off-the-shelf” technologies or launching a brand new project may seem more efficient. However, choosing a solution without considering the organization’s inherent constraints (organizational and technical maturity, human and material resources, technical debt, learning curve…) can be risky.
Moreover, these constraints are often already recognized and have been expressed for years by internal expertise. They lead to the birth of projects initiated by employees, in response to observed needs or their own frustrations. Instead of encouraging them to find a solution, they are often reprimanded for insubordination. In reality, these projects often get lost in middle management and rarely reach the decision-maker who can sustain them.
Indeed, decision-makers seldom have the time to meet each of their teams. As a result, they tend to favor their own opinions or seek those of their deputies instead of their experts. The resulting decision, therefore, reflects the perspective of a single person, isolated from operational realities. The more layers of management there are, the more pronounced this isolation becomes. This leads to a concentration on poorly researched and non-inclusive projects. Paired with inherently low-impact communication, it inevitably produces frustration within the company.
A prime example is the U.S. Department of Defense (DoD). They launched a new DevSecOps initiative named Vulcan34 4 years after the Platform One35 initiative, which had the same aim. Beyond causing frustrations within the Platform One teams36, the Vulcan program has experienced delays and cost overruns37.
In other instances, the skepticism of some leaders leads them to question proposals made by their internal experts. Taken to an extreme, this mindset negates the benefit of hiring experts who interact daily with the company’s issues. The external expert (e.g., a consulting firm, a third party) then becomes indispensable, viewed as objective and impartial38.
When faced with leaders who do not share our vision, one can express outrage and leave or try to understand their reactions and improve practices. As the leader of an internal initiative, you need to understand the decision-makers’ fears: entrusting a groundbreaking project that disrupts organizational practices carries multiple risks.
If your organization is large and longstanding, it’s because it has consistently met a need. If leaders come to believe it needs transformation (or if you anticipate it) and nothing has been started, the organization might be facing the innovator’s dilemma.
Conceptualized by Clayton M. CHRISTENSEN39 in 1997, this dilemma describes a scenario where a pioneering company, attempting to maintain its competitive edge, inadvertently misses out on major innovation. A previously unforeseen competitor then offers this innovation and upturns the market share. For instance, in 2023, Microsoft stunned everyone by releasing a ChatGPT integrated into its search engine before Google did. At that time, Google was the pioneer in internet search and was investing billions of euros annually in AI research. How could Google let a competitor get the upper hand?
The answer is simple: the risk for Google - with 84% of search engine market share40 - of releasing an unfinished product - which might return false information, for example41 - is much higher than for a startup like OpenAI or for Microsoft’s Bing - with 9% search engine market share. This is evident as, at the time of writing this chapter, few online articles questioned the Bing Chat launch compared to Bard, despite having similar issues42. In summary: Microsoft had everything to gain, while Google had everything to lose.
That said, Google saw the pitfalls of not taking risks and has been working on a competitor, Bard43. To avoid this dilemma, organizations should:
More practically, if you decide to form your own team, members might leave your organization at any time. Given the depth of the discussions they were involved in, they might leave behind work that is challenging to pick up. That’s why many organizations prefer to engage a third party, with a clearly defined scope, ensuring the leader gets a result (through the third party’s contractual obligation). We will explore in the chapter “Staying close to business needs” how this approach can have long-term negative consequences for the organization.
Organizational changes always entail a cultural shift that must be managed. This cultural gap can sometimes be too challenging to bridge for the entire organization, indicating it might be too early to introduce your plan. Cultivate awareness through presentations and success stories. Leaders must clearly understand the transformation’s impact and associated risks: service disruption, HR strategy changes, staff training, or equipment purchases. Support your leaders in visualizing the transformation as you work on building your evidence.
The rest of this book will address understanding the psychology of change to ensure your project’s success.
“Another one!” your most loyal team members might exclaim. How many reorganizations has your organization undergone? When overdone, they muddle the message and breed confusion for your teams.
In most cases, technical teams already exist within your organization, already serving business needs that necessitate their existence.
Leaders with limited understanding of business and technical stakes often feel the urge to alter the roles of certain teams. They do this in favor of a new project, based on the current skills present within the team. However, a team always forms around a project that shaped its culture, making it so efficient for the company today. Decision-makers should consider this before thinking of breaking this hard-earned culture by imposing a transformation.
The risk of drastically changing a team’s roles means you should be well-prepared to support them – often, this isn’t the case, as you likely don’t have the time. Their current operational methods are the result of several restructurings, which probably already affected their ideals and the reasons they joined your organization in the first place.
Changing a team’s roles without considering its culture and history risks losing team members: either they’ll be demotivated by your project, or they’ll resign. You need to provide them with a clear vision, convince them with solid arguments, but most importantly, involve them.
Given their history in your organization, your teams’ knowledge can help you grasp concepts you haven’t fully understood yet. Be open to their suggestions and feedback to discern how best to reorganize the team - and only if necessary - based on its aspirations. An excellent way to gain a team’s trust and better understand its challenges is to do its job for a few days. This can be done when a decision-maker first joins the organization.
If you believe you don’t have the necessary internal resources, don’t hesitate to recruit. It’s risky to affect the established teams if they’re serving a need expressed by your organization. The essence of a transformation is to ensure service continuity while changing its practices.
Be more nuanced than announcing a “major transformation plan.” Such practices invariably frustrate many team members, fail to gain the support of all your teams, and risk undermining your credibility. They can also make you a hostage to your predecessor by associating you with past failed transformations.
As discussed in the chapter “Too big, too soon,” adopt a step-by-step strategy and gradually develop your intuition about who needs to be reorganized. Gain team buy-in by showcasing the realm of possibilities to inspire them. Then let them convince their peers on your behalf. We will delve deeper into these strategies in the chapter “How to convince and keep the faith”.
“It’s normal, we’ll always be behind here.”
If this statement sounds familiar to you, it probably evoked a sense of dismay.
It’s understandable for a company to face delays due to its size, resources, and safety requirements. However, organizations must not tolerate such lag. Under no circumstances should the statement “it’s normal here” become an acceptable response.
If the speaker is genuine, this mindset merely stems from a lack of knowledge about how to achieve the goal. Otherwise, it might indicate a lack of courage or even intellectual laziness.
If the majority of an organization’s employees believe that it is behind, there is a severe issue at hand. Maintaining the status quo in such situations inevitably leads to the organization’s decline and an irrevocable loss of credibility among its employees and partners.
In one of his articles44, speaker and transformation expert Philippe SILBERZAHN gives the example of a man waiting for his train scheduled at 9:30. The screen reads “On Time,” but it’s already 9:35 on his watch. The man thinks about photographing the sign but wonders, “what’s the point?”. Many observers would downplay this five-minute difference, express irritation, or simply blame a display malfunction. “After all, no one can do anything about it,” they might conclude. It is with such behavior that Philippe SILBERZAHN argues organizations decline: they grow accustomed to mediocrity.
While initially considered unacceptable, over time, the malfunction becomes increasingly acceptable to the organization, without them realizing the cost in time and money. The effort to rectify the issue becomes less and less justifiable, and silence becomes the default choice to conserve energy. Until an irreversible situation arises (or a few brave souls shake the structure!).
However, it’s essential to know when to unveil innovations. Preston DUNLAP, the first Chief Technical Officer (CTO) of the USAF, describes in his public letter Defying Gravity how “bureaucratic forces” can hinder innovation if introduced prematurely.
“Some have asked me what my recipe for success was over the past three years. I haven’t spoken much about it because I knew that if I revealed the elements too early, the natural forces of bureaucracy would come back stronger, rejecting at every turn all the potential of innovation.” - Preston DUNLAP, Defying Gravity45
To prevent technological lag, organization leaders can adopt several practices:
Designing the best service (a method, software, or tool) won’t let you be helpful to your organization unless you provide easy access, uninterrupted service, and support. DevOps will enable you to structure and maintain this source of value.
This book doesn’t even require your team to be especially large, nor does it require your leaders to already be convinced. However, it does require your team to be convinced that they can drive the project forward. Of course, over time, support from other teams in your organization will become a valuable argument to showcase the success of your initiative.
A leader only asks to be convinced by an initiative from their subordinates. Help them visualize and understand the added value of what you’re proposing.
This will require you to regularly present the progress of your project: both so they remember and so they understand. It’s always risky to assume a project is understood after the first presentation, especially when introducing a new paradigm.
Plan to set up an internal team: there will always be bugs to fix, configurations to adjust, and features to add. Whether developed internally or by a contractor, you’ll face the phenomenon of software erosion46. This refers to the issues software may face over time when left unattended (critical security updates, full disk space, processes that stop working…).
Don’t think that a contractor can solve all your problems: you’ll lose money and won’t achieve your goals. The result of a contractor will only be the product of your ability to synthesize your challenges. Yet, during a transformation phase, you’ll discover new issues every week. Unlike you and your team, the contractor probably won’t be continuously present in your organization to capture all stakeholder challenges.
Starting your DevOps initiative requires envisioning the recruitment of several profiles:
Whether you’re a senior manager or a mission officer aiming to enhance the services your organization offers, you will need to justify your initiative to your superiors and the rest of your organization. It’s therefore essential to understand how to communicate effectively so everyone buys into your project. Let’s explore some strategies for doing this in the next chapter.
First and foremost, it’s not about convincing. You can’t just walk up to someone and say, “you’re wrong, I’m right.” Instead, you need to inspire your audience to align with your vision or project. In this way, they’ll be convinced on their own.
Gaining the support of your superiors or colleagues for an initiative isn’t always straightforward. William MORGAN - the leader of a renowned tech startup - recommends 4 rules to follow47:
According to William MORGAN, once you reach a certain level of technical engineering, the roles of “salesperson” and “engineer” become indistinguishable: “Advanced engineering work is indistinguishable from sales work.”
Here’s how these rules could be applied to security and management teams:
The theory of mental models48 helps us better understand the decision-making process (e.g., whether someone supports an initiative). Everyone’s perception (i.e., a mental model) varies by individual. Transformation, then, is about collectively agreeing on an alternative mental model49.
Even though DevOps might be backed by studies and is evident in the private sector, institutional initiatives are still not widespread enough50. Therefore, you find yourself in a position where you’re certain about the direction to take, but you’re not fully able to justify it with data or examples. Presented with your forward-thinking transformation proposal, the decision-maker thus faces a risk. And as a matter of survival:
“It’s better to be wrong with the group than to be right against the group.”
To assist the decision-maker in making their choice, you need to work on minimizing this risk. But how? The idea is to rally early adopters to your cause without announcing it to the collective.
“The first one to step forward takes a massive risk. The 150th takes none.”
Besides enhancing your value proposition, you’ll have examples to reference and support: you won’t be the “first” taking the risk, and neither will your organization.
“Initiative is the most refined form of discipline.” - General LAGARDE
Operating behind the scenes (not announcing your project to the group) requires understanding its potential repercussions. Even though you may want to make improvements in good faith, you might misjudge the overall situation of your organization. Thus, your project could disrupt established power dynamics, making you undesirable in the eyes of some.
For instance, a team lacking resources comes to you for help. Seeing their distress, you design a brand new tool for them quickly using your DevOps platform. You choose not to inform your superiors, fearing they might reject this innovation (refer to the previous chapter).
What you don’t realize is that the team you’re supporting hasn’t been doing the work required by management for several weeks. While the leaders are trying to balance the situation, a sudden player (your team) starts doing favors for the delinquent team.
Upon hearing the news, the leaders find themselves in an awkward position: they appreciate the support you provide (it’s virtuous in good faith) but resent you for meddling in their affairs.
And thus, your initiative gets caught in a vicious cycle (fig.
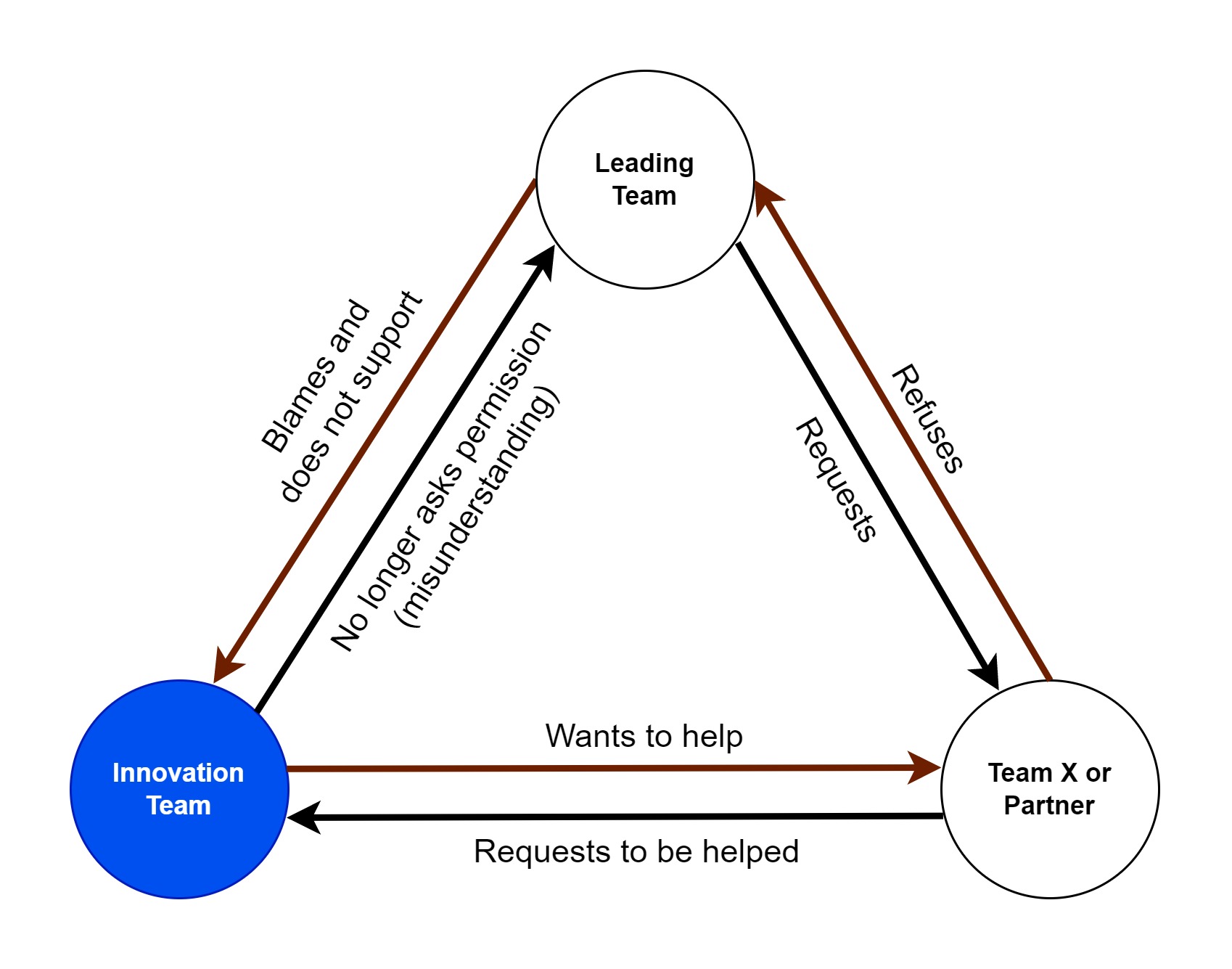
The problem is primarily cultural: the organization isn’t trained to support innovation, making it challenging to innovate. Innovators must then find indirect ways to make a difference. On the flip side, innovators are often not well-versed in the structures where they are asked to innovate. This highlights the need to train these profiles so they better understand how the organization operates. By implementing the 5 pillars of DevOps, you will help your organization transform its culture and promote innovation (refer to chapter “The five pillars of devops”)
Therefore, make sure you fully grasp the political dynamics between the leadership team and your initial experimenters before acting covertly, or you risk complicating your progress.
Keep in mind that if things are the way they are today, there are valid reasons for it: you might not necessarily have a comprehensive understanding of these past reasons (time allocated to projects, HR/financial resources, power plays, etc.) and it’s not your role to blame those involved.
Also, be aware that during a transformation, leaders must continue to deliver the same services as before. Decision-makers then have to manage the transforming environment parallel to the current environment, ensuring the former doesn’t overshadow the latter.
Furthermore, don’t be disheartened by the first person who resists. Every innovation initially faces moral mockery and goes through three phases: ridicule, perceived as dangerous, and then seen as self-evident51. Having experienced this firsthand, I can vouch for its accuracy, and there are historical examples:
If you face direct opposition, you may need to rethink your communication strategy (refer to the following chapter “Tailoring your message”). Start with understanding opposing viewpoints. If you feel that some are deliberately trying to end discussions, consider the following tactics:
Successful transformation requires impeccable communication from its initiator. It’s crucial to know how to present based on the target audience, all the while keeping in mind certain common organizational phenomena.
“Why don’t they seem convinced?”
Perhaps after one of your presentations, you’ve found yourself in this situation. Validated by many of your peers and seemingly well-suited after rehearsals, it still didn’t achieve the desired impact. The person you addressed didn’t ask the right questions or seemed bored, or even irritated.
Presenting to different audiences requires tailoring your presentation style, examples, and arguments to their roles, constraints, and needs. Don’t expect anyone to understand the so what55 of your presentation if you haven’t first understood why it was beneficial for them to attend. Typically, two presentations suffice: one for professionals (or “clients”) and another for senior officials (or “policy makers”).
However, it’s important to differentiate between senior officials (or executives) and immediate supervisors (or managers). The latter often have a stronger bond with their teams, making them more receptive to business-related arguments. Senior officials, on the other hand, operate at a strategic level56, where they set the organization’s vision and major directions. Operational, tactical, and technical considerations are delegated. As such, messages passed up the hierarchy might get distorted or altered.
That’s why you shouldn’t assume that the leaders are always aware of what you observe at your level. Don’t hesitate to remind your audience about the effort required for even the most common tasks. For instance, emphasize that 80% of n individuals’ work is dedicated to a certain task. With your approach, you could save x hours per day for each employee, equating to y euros in savings or z times increased productivity.
Decision-makers seek arguments they can use to persuade others. Endeavor to grasp the mandates they must adhere to, providing them communication tools they can reuse. For instance, the CEO of a multinational might prioritize economic profitability, while a high-ranking politician might weigh social impact more heavily. However, both will be keen to align with their organization’s strategy (corporate strategy or government/party priorities).
Just like you, a decision-maker newly introduced to a topic can only retain a few key pieces of information. Ensure you focus on a maximum of 2 or 3 main ideas you want to convey. Conclude your presentation with a call to action, guiding them on how they can support your project’s realization.
Let’s summarize the interests of our two profiles:
| Subject | Professionals | Decision-makers |
|---|---|---|
| Detail Level | Detailed practical information. | Overview. |
| Terminology | Industry jargon and specific tools. | Strategy-focused, emphasizing value to the organization or broader community. |
| Data and Evidence | Practical examples, case studies. | Impact metrics in time, money, and influence. |
| Objective | Educate, inform, gather feedback. | Persuade, gain approval. |
| Presentation Style | Interactive, hands-on. | Formal, concise, direct. Aimed at the desired outcome. |
Take, for instance, a company whose employees need a high-performing translation software. A solution provider pitches to the organization’s director. Here are the arguments for each profile:
| Subject | Employees | Director |
|---|---|---|
| Detail Level | How the tool eases work, its usage, and unique features. | Why the organization needs this tool and its impact. |
| Terminology | Technical terms related to translation and tool operation. | Focus on strategy, organizational efficiency, and performance improvement. |
| Data and Evidence | Tool demonstration, before/after comparisons, case studies. | Overview of features. Productivity boost statistics, ROI, internal usage feedback. |
| Objective | Discover the tool’s value (speed & quality of translation). Usage instructions and limitations. | Understand the tool’s positive impact on the organization and the investment required. |
| Presentation Style | Practical, interactive with demos and Q&A. | Concise, focusing on organizational benefits. End with a call to action and a summary sheet. |
Lastly, you cannot completely rule out the possibility that your counterpart might have conflicts with other stakeholders in your organization. This could hinder them from making seemingly beneficial decisions, in a bid to maintain their status or protect their career. In such scenarios, try finding equally or higher-ranked influencers to champion your vision among decision-makers. Once multiple top executives back your message, it becomes challenging for anyone to reject what the rest of the organization sees as essential.
More often than not, lackluster communication results from misunderstandings rather than malintent. Unless you’re sure, always assume the issue isn’t with the person in front of you.
By understanding the techniques to address common resistance to change situations, we can move forward with greater confidence. Let’s now explore how to structure our approach and strengthen our arguments for effectively launching our initiative.
In the chapter “Refusing technological lag”, I discuss internal innovation as a means to prevent an organization’s decline. However, it’s crucial to clarify how in-house development, beyond being effective, becomes essential if a company wants to remain competitive.
Which company responsible for a major IT project would claim, “We don’t need an IT expert”? Due to a lack of technical acculturation or previously mentioned psychological phenomena, decision-makers sometimes chronically turn to consulting firms.
Much like global organizations such as the World Health Organization (WHO) or the United Nations (UN), national entities like the National Center for Scientific Research (CNRS), the National Education, and the Public Health France agency have an internal scientific council57. This ensures they stay updated on the latest scientific knowledge, enabling decision-makers to make informed choices. In the private sector, this role is filled by the Chief Technical Officer (CTO) and their senior managers (VPs in English).
While a scientific council can help an organization remain at the forefront of scientific knowledge, it isn’t enough to make it innovative. Especially if its members aren’t periodically refreshed. To innovate, practice is key.
If you want to effectively address the challenges facing your organization, only an internal team practicing the technologies related to your topics can help. Thus, boldly setting up your technical team offers numerous benefits. Daily contact with business sectors or clients enables the creation of tailor-made tools, finely tuned to meet their needs effectively.
This close proximity to the requester also facilitates real-time support service, eliminating the additional costs and delays usually associated with external support. This leads to shorter improvement cycles and faster delivery of requests.
Having the project roadmap under their direct control allows decision-makers to ensure developments perfectly match their needs and vision. This in-house management significantly reduces costs by pooling investments for several simultaneous projects.
One of the primary strengths of an internal team lies in data security, with data strictly confined to the organization’s infrastructure, accessible only to authorized members. This minimizes the risk of data breaches.
Furthermore, an internal team has a unique ability to quickly and relevantly evaluate technological innovations, placing them in the organization’s business challenges context. They are also positioned to promote the assimilation of these new technologies within the organization through presentations suitable for all levels.
Relying solely on an external resource for your IT projects will inevitably lead to prohibitive costs. Without internal expertise, you’re at the mercy of talented sales teams from companies eager to sell you services your organization will never use.
The main reason decision-makers are cautious about in-house developments is maintenance. They’re right: paying a service provider can be expensive, but they’re contractually bound to deliver. This contract often comes with a maintenance provision. A single internal developer - poorly equipped due to limited support - might fail at the same task, ultimately calling the decision-maker’s responsibility into question.
Therefore, hiring two or three engineers won’t be enough to sustain your developments. To successfully offer a useful solution, which can be a viable, maintainable alternative and credible to your superiors, you’ll need to assemble a much larger team.
By equipping this team with a proper development environment (see “Software factory”) and incorporating best DevOps practices, they’ll have time to focus on the quality of your software. While this requires a time investment and might be a challenging step with your superiors, they haven’t yet realized how invaluable this advancement will be in the future! Stay the course.
At one of the companies I worked for, the in-house development of software by an engineer saved several million euros. Equivalent industrial programs were stagnating, and the business units remained helpless. It took just one engineer - albeit a brilliant one - to solve a problem that had persisted for over 6 years.
Thanks to DevOps rules demanding software quality standards, over ten developers in the last three years have contributed to this project to maintain and enhance it. It still receives numerous weekly updates today.
Beyond providing a pragmatic solution to a problem, this engineer especially succeeded in acclimating the entire hierarchy to modern development concepts and machine learning techniques. Invited to major strategic meetings alongside traditional external providers, he became the organization’s machine learning reference. Without him, no one internally would be able to specify a need or evaluate a machine learning solution with full knowledge.
Many organizations have sought to invigorate their structures by creating “innovation teams.” Yet, many have not truly managed to deploy into production what was developed therein.
Use cases often revolve around data and artificial intelligence. Buzzwords such as “data scientists”, “deep learning”, and “artificial intelligence” have led to numerous false hopes. Many organizations hired data science profiles only to find them unable to deploy their algorithms to interfaces designed for non-expert users.
The problem isn’t with the data scientists but rather with decision-makers who, until recently, didn’t understand what responding to business needs entails: a reliable development foundation, clean data, massive data, model tracking58 (MLOps), and a deployment team. In essence, many thought (and continue to think) that “AI” could solve any problem with just a few lines of code. These individuals are unaware of the infrastructure and technical support required by these technologies.
A typical data science example concerning DevOps is the need for computational power, storage capacity, and services to develop and monitor the training of models. Yet, most data scientists aren’t equipped to set up their machine, their GPU drivers59, and their Jupyter Notebook environment60, especially within the complex environments characteristic of large organizations (regulatory constraints).
What will set your team apart is the support you provide to your operators. Compared to traditional development teams or external service providers, your advantage is the potential to have close interactions with your organization’s business operations.
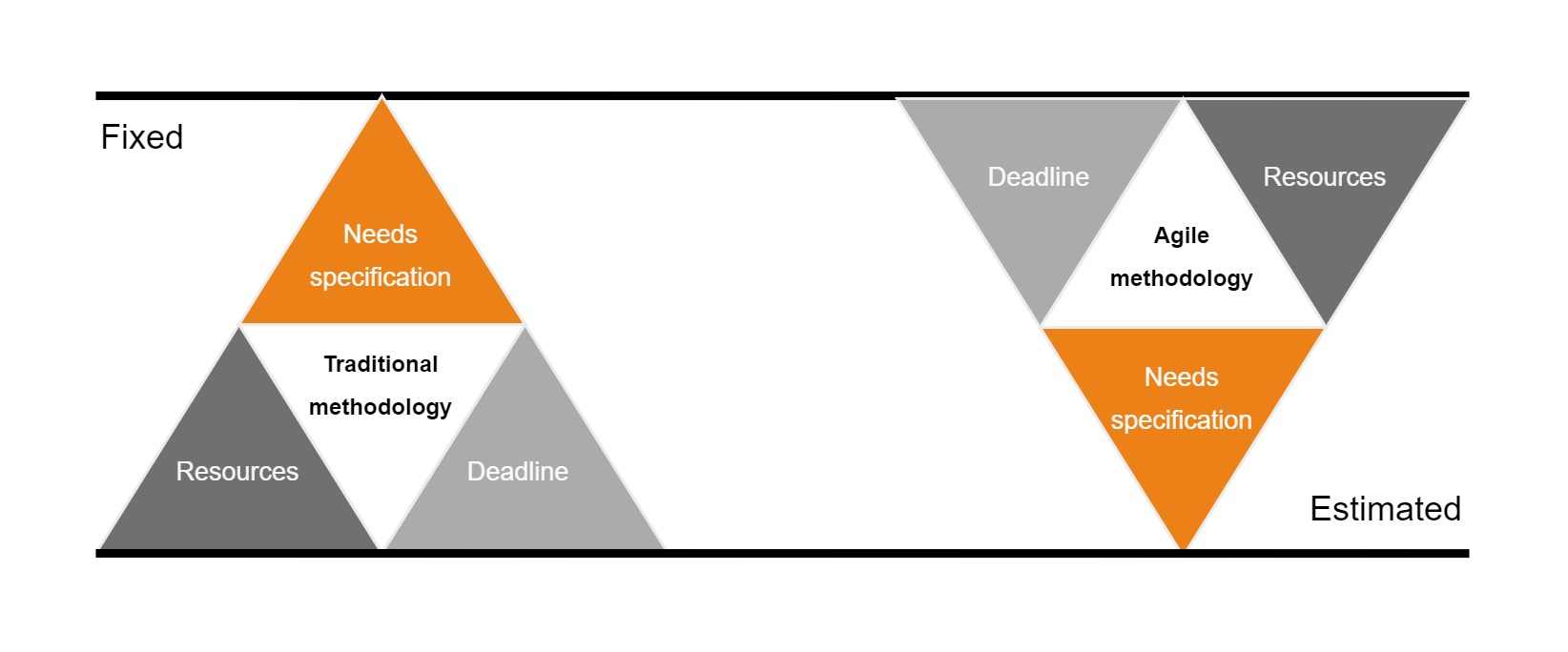
This is the renowned “agile” methodology, in contrast to the “V-cycle” (or waterfall methodology).
In many organizations, the “V” approach is still employed: the service provider meets the business team with a requirement, produces a PowerPoint presentation a month later, and unveils the development outcome between 6 months and 6 years later. In software, the delivered product is already outdated, and the teams that made the request might have changed by then.
In manufacturing—like designing a warship—it’s legitimate to ensure that the vessel will float correctly and that its rudder will steer it properly before launching. The ship’s features are often set: its range, missile capacity, service duration, etc. One wouldn’t alter the hull composition at the last minute or adjust the shaft line bearing. The “V” cycle is appropriate here.
However, in software, a more agile approach is feasible. Software behavior can be assessed and simulated in near real-time. This flexibility ensures the software can be adapted at any point, ensuring it meets set objectives (fig.

Within an armament program, the onboard computer systems of a ship (e.g., sensors, information systems) can follow agile methodology, while the carrier’s production61 can be governed by the “V” methodology. While the hull may undergo few changes, the software can be updated as rapidly as operations require62.
Beyond the technical solutions you offer, your business teams will notice that your more agile organizational mode is efficient for them. Consequently, they will support your initiative. As a team leader, your goal should be to have representatives from business teams that you’ve aided with your tools testify during crucial presentations. Such representations will bolster your credibility and prevent your teams from merely being seen as “technical development providers.”
This proximity to business operations will enable your teams to feel more involved in your organization’s missions. It’s a win-win dynamic for both your engineers and clients. Both parties benefit from each other’s expertise: the engineer gains a deeper understanding of the issue, and the operator specifies their need as precisely as possible.
Henrik KNIBERG’s63 illustration, an agile coach, effectively conveys the essence of the agile methodology: the preference is to deliver a functional (though incomplete) product at each stage, gather user feedback, and iterate (fig.
Throughout your career, you’ve likely noticed: clients often struggle to articulate their exact needs. Agile and ultimately DevOps methodologies allow for adaptation to the ever-evolving business realities, ensuring a deep understanding and delivery of a product truly aligned with their requirements.
By automating tedious processes, DevOps techniques will free up time, allowing you to spend more with your clients, understand their needs better, and effectively address their feedback and suggestions.

Bringing technical profiles and business teams together adds value by promptly and accurately addressing internal challenges. This is also a key to staff retention. Remember: your teams seek purpose. They don’t merely come to work to follow orders but to employ their expertise to devise the best technical solution for a business problem. An engineer’s work culmination is witnessing the business use the solution they’ve crafted.
One of the cornerstones of DevOps is to break down silos, including access to data.
If you want your technical teams to best respond to your needs, they require privileged access to your company’s data.
When the legal framework allows, forego “anonymized samples”. Engineers need a precise understanding of the data they are supposed to process. Trying to develop a tool based on “anonymous” data is akin to developing a tool that only partially addresses a use case.
Otherwise, you can be sure a bug will occur as soon as an “unknown” data passes through the software (see edge cases). Provide your teams with production data intended to be used in the tools: you’ll spend less time on bug fixes and improve the quality of service provided by your software.
If you don’t have the necessary permissions, perhaps hiring in-house isn’t essential. A service provider can just as effectively build the software from open-source data. However, consider the risks of proceeding this way (see Staying close to the business needs).
The idea that DevOps bridges different professions for collaboration is not easy to implement. Traditional roles in Information System Security (ISS) found themselves confronted with practices they weren’t used to and sometimes didn’t have the time to grasp.
In large organizations, company rules or even the law itself require specific versions of a software to be defined for it to be qualified64 or approved. Imagine having the responsibility to enforce these conditions when DevOps methods involve dozens of software updates daily: it’s quite daunting! Therefore, understanding the makeup of a cloud infrastructure to correctly define its “security” is essential.
Security affects all pillars of DevOps. This chapter focuses on a high-level description of security concepts within a DevOps approach.
In this organizational mode, security practices are automated to be systematically verified. The aim is to minimize so-called “documentary” security in favor of programmed rules. Indeed, using standardized technologies (e.g., containers, Kubernetes) facilitates implementing security rules, ensuring they are applied.
The DORA report65 “State of DevOps 2022”66 focuses on security challenges in corporate DevOps transformation initiatives. It states that a company promoting trust and psychological safety is 60% more likely to adopt innovative security practices. This culture reduces the number of burnouts67 by 40% and increases the likelihood of an employee recommending the company.
Security has always been a matter of culture. However, the DevOps methodology introduces all the techniques that will allow an organization not to overlook good practices, previously neglected or lost in voluminous and cumbersome archives.
The key is to understand that in DevOps mode, we operate on a principle of iterative improvement cycles. Projects are never set in terms of technology used, and deployments are continuous without human interaction. This ensures that innovation remains agile and always addresses the client’s needs most accurately.
But it’s not a free-for-all: there are technological standards and procedures that control what’s deployed, according to the security standards your organization demands.
We’ll delve deeper into the cultural aspects of the DevOps methodology in the chapter “Embracing failure”.
Governments are hungry for new innovative technologies. However, they need to strike a balance between the risks they may entail and the benefits they may get. This is why they create frameworks to manage this risk.
France’s cybersecurity agency68 defines three ways to assess risk of using a technology : qualification69, certification70 and accreditation. Most western countries adopt similar processes and signed an agreement making the trade of secure IT solutions between members easier : the Common Criteria Recognition Arrangement (CCRA)71.
As a declarative approach to managing security risks, traditional approval processes are not well-suited for continuous deployment practices. They freeze risk for a specific moment or architecture. Yet, threats emerge daily: a vulnerability in a library, for example, could be detected a day after approval is granted. Even though the approval is temporary and a periodic assessment might be required, the vulnerability might persist during this time, leading to a risk of exploitation.
For Cloud service providers (CSPs), the United States established the Federal Risk and Authorization Management Program (FedRAMP)72. It adds a new layer of security compared to traditional approaches by enforcing a demanding continuous monitoring process.
Assuming security flaws might emerge at any moment must be part of your cybersecurity posture. You must have actionable tools to quickly respond to threats and preserve your ATOs73. To address this challenge, it’s recommended to adopt continuous integration techniques.
Continuous integration allows automatic monitoring of changes made to software or infrastructure.
Whenever even a single line of code is altered, tests are triggered. If a code modification doesn’t meet the defined security standards, the contribution74 is rejected. The developer is automatically notified in their software factory (e.g., GitLab). They can see an error message explaining the issue, enabling them to immediately make the necessary adjustments.
This is where the expertise of security managers is needed. These professionals must explain to DevOps engineers and SREs what specifically needs to be monitored. These rules are then translated into code, forming automated tests, within a continuous integration pipeline used by all company projects.
These versioned rules in the form of code become automated tests. They can be updated as needed, instantly impacting all projects.
They might consist of antivirus checks, vulnerability scans in used Docker images, or ensuring that no passwords are inadvertently left in a public file.
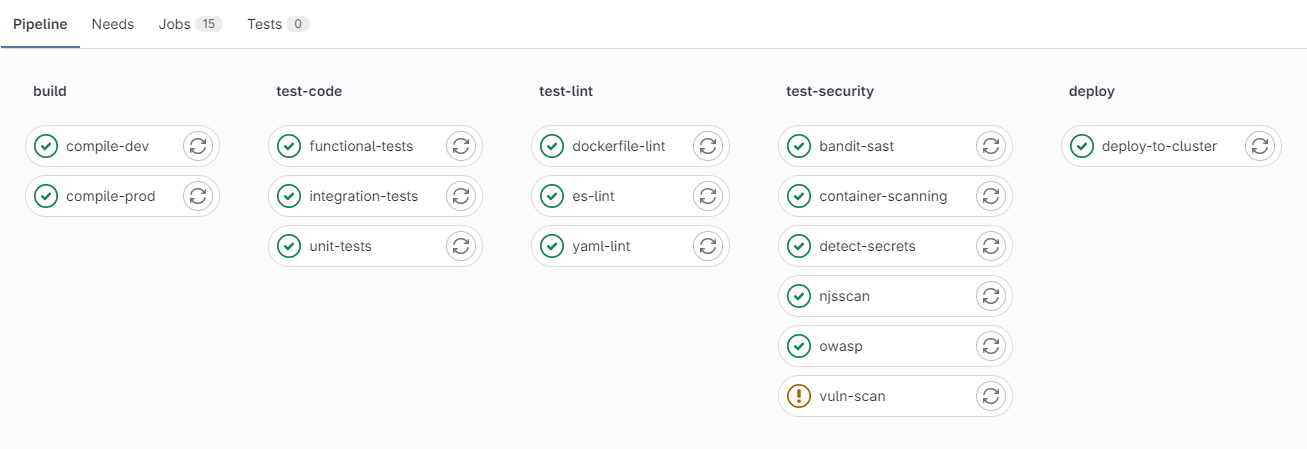
In the illustration above (fig.
An exclamation point means the test did not pass but was not deemed critical (e.g., an outdated software dependency with no security flaws).
For engineers, the ultimate goal is to see their project accompanied by a green checkmark, signifying all tests have been successfully passed.

In a DevOps approach, developers don’t start from scratch. They begin with a template75 that they copy, which integrates - in addition to development files - all security rules. Ensure that security teams co-contribute to these templates so every new project incorporates your security standards (see chapter “Continuous Integration and Security”) to save time for everyone.
Continuous integration chains aren’t limited to security tests. Consider them as scripts automatically triggered with each code modification. Although the traditional trigger is “code modification”, cloud hosts like AWS might offer their triggers (e.g., adding a file to an S3 bucket)76. We’ll delve deeper into the workings of continuous integration in the chapter “Continuous Integration (CI)”.
In an ideal world, all verification is automated. However, it’s sometimes challenging to “code” advanced security checks, and you might not have the human resources to develop them.
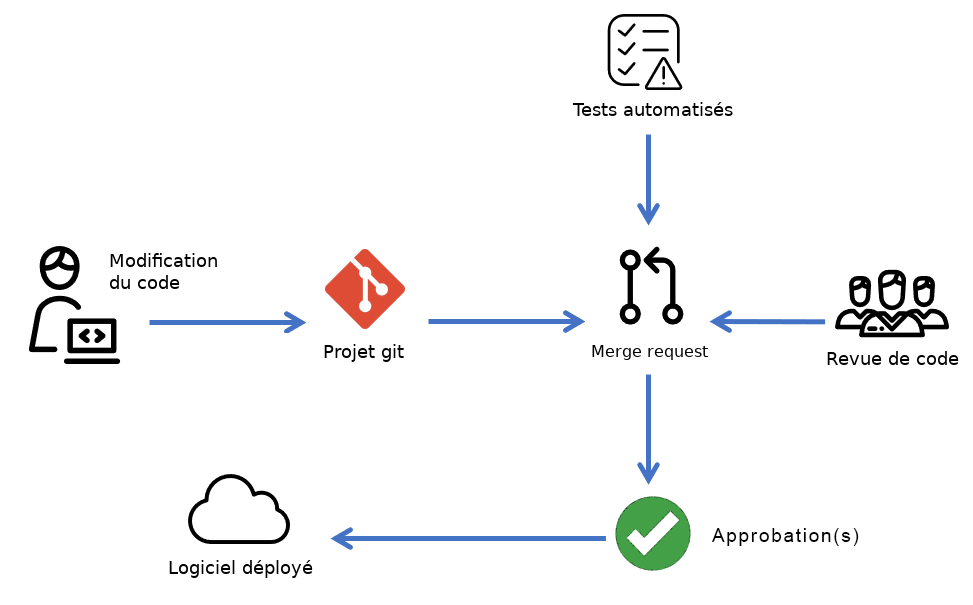
In DevOps, the GitOps methodology is practiced: everything is based on code (software, infrastructure, architecture diagrams, presentations, etc.).
Each developer works on their own branch and develops their feature. They test if everything works as expected, then creates a “merge request” (commonly known as merge request or pull request) into the main branch. This process is detailed in the “Git Workflows” chapter.
Code review takes place at this juncture. It’s an opportunity for engineers to approve others’ changes, providing an external perspective before it gets merged into the main branch. This is the time when various stakeholders involved in reviewing the quality of a contribution can write their comments (fig.
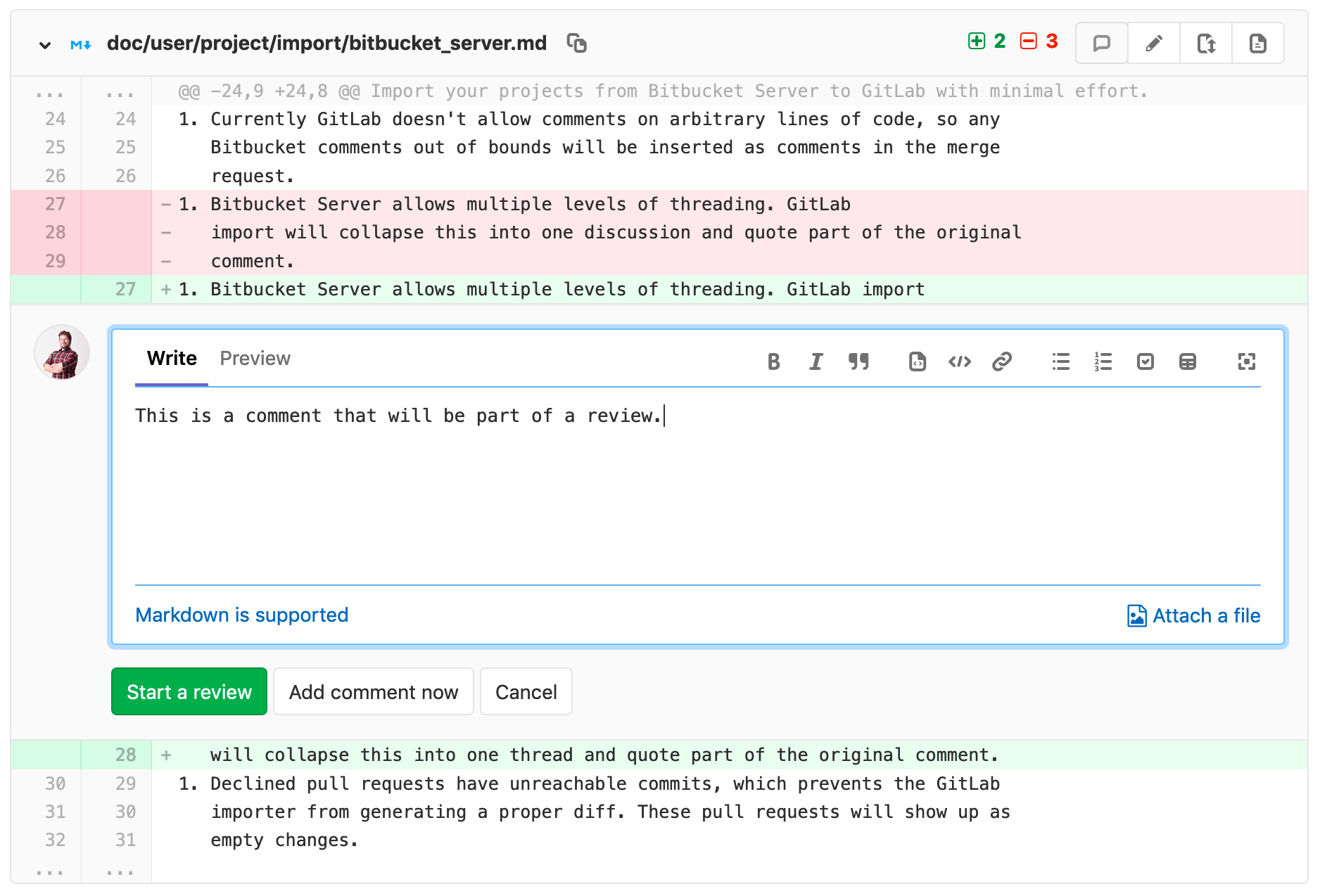
The goal is to ensure the developer hasn’t made significant errors in the code’s functionality or is not adding technical debt. For instance, at Google, a merge request requires approval from at least two engineers before it can be validated.
Releasing a new version of software in production is the ideal time for security teams to audit the code. This practice is known as “security review”. Every new software release is subject to previously mentioned continuous integration rules with additional automated security tests and optionally the validation from the security team.
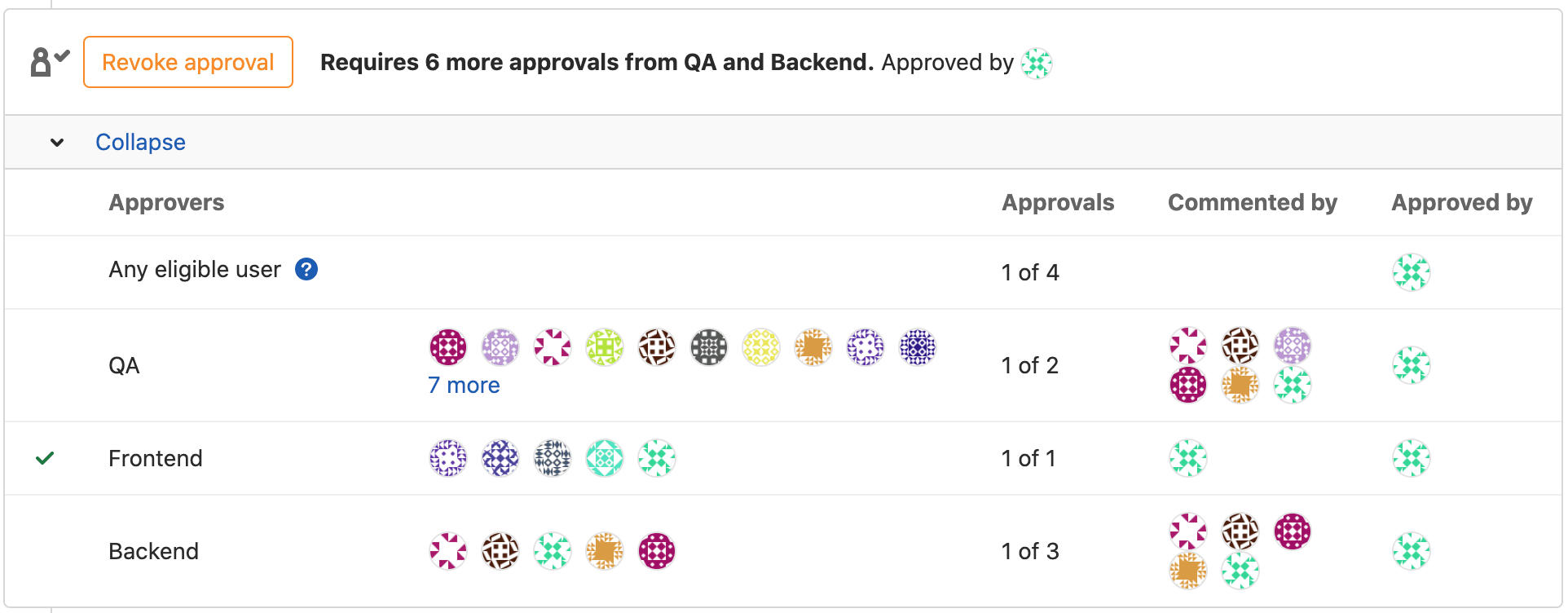
For security teams, the code review aims to ensure that the maximum security criteria are met, such as:
GitLab, for example, allows you to mandate the approval of a merge request by specific teams77 (e.g., the security team) before a contribution can be merged into the main branch (fig.
Tools like ReviewDog, Hound, and Sider Scan assist engineers during code reviews. For instance, these tools run linters78 and automatically add comments on the relevant line.
In May 2021, the White House released a decree describing new strategies for “improving the country’s cybersecurity”. Among the 7 described priorities79, enhancing the security of the software supply chain is mentioned. It states there’s an “urgent need to implement stricter techniques, allowing for quicker anticipation, to ensure products (software purchased by governments) operate securely and as intended”80. This commitment was renewed in January 2022 with Joe BIDEN’s signing of the U.S. National Security Memorandum81.
DevSecOps Maturity Models (DevSecOps * Models) like those from OWASP82, DataDog83, AWS84, or GitLab85 offer general techniques to enhance DevSecOps practices. They help in breaking down an organization’s maturity progression into more accessible steps, aiming to achieve better security practices.
First, we’ll explore the techniques and tools used to secure the software supply chain. Then, we’ll see how they’re integrated through frameworks. The vast majority of tools mentioned in this chapter are run within continuous integration chains, serving to validate an organization’s entire security rules with every code change.
Information Security practices within large organizations often require that any deployed software be accredited. The accreditation document must list the dependencies used in the software: the third-party libraries it relies on. This list is called the Software Bill of Materials (SBOM86).
The SBOM allows for quick answers to questions like “Are we affected?” or “Where is this library used in our software?”, when a new vulnerability is discovered. In a DevOps approach, the libraries used in software change over time. A library or technology used today might be replaced tomorrow. Hence, developers cannot be asked to manually list these hundreds (or even thousands) of dependencies used in their software.
SBOM is part of the techniques of Software Component Analysis (SCA) or “Analysis of software components”. SCA encompasses techniques and tools to determine the components of third-party software of a software (e.g., the dependencies, their code, and their licenses) to ensure they do not introduce security risks or bugs.
The advantage of the DevOps methodology is that all code is centralized within the software factory. This allows us to use tools to analyze the composition of each project and prevent security vulnerabilities.
It’s possible to generate the SBOM of software using tools like Syft, Tern, or CycloneDX. The standard format of an SBOM file is SPDX, but some tools like CycloneDX have their own. The common practice is to store this file in an artifact signed by your software forge with each new version of the software you wish to deploy.
The goal remains to determine if a used library is vulnerable, to update or replace it. Apart from meeting regulatory constraints, just leaving this file as a simple document isn’t very useful. That’s why it’s now necessary to analyze the SBOM.
A lightweight analysis tool like OSV-Scanner can be easily integrated into your continuous integration pipelines and provide a first level of protection. However, it won’t provide an overview of all the affected software within your infrastructure. Tools like Dependency Track (fig.

Softwares like Renovate or GitHub Dependabot allow detecting dependencies with vulnerabilities and automatically propose an update in the software forge by opening a merge request (see chapter “Code Reviews”).
In summary: Instead of just listing dependencies, the aim is to set up continuous detection of used libraries for all projects. It’s essential to alert about threats as early as possible and refuse contributions that could bring risks before they are deployed in production.
While SCA tools allow you to analyze the composition of your project (its dependencies and software used), SAST tools aim to analyze the software code you develop. However, SAST tools also cover SCA features. Both fall under the domain of Source code analysis.
Static Application Security Testing (SAST), focuses on techniques and tools intended to find vulnerabilities in your source code before it’s run. They represent a form of white box testing. For instance, SAST tools will identify insecure configurations, SQL injection risks, memory leaks, path traversal risks, and race conditions.
Here’s a list of SAST tools with their descriptions to understand their variety:
A comprehensive list of open-source and commercial code analysis tools is available on the OWASP foundation website88.
While SAST significantly improves software supply chain security, it doesn’t replace other security practices. Indeed, static analyses can produce false positives or miss vulnerabilities that only manifest during software execution. Therefore, complementing SAST with techniques like DAST (Dynamic Application Security Testing) or IAST (Interactive Application Security Testing) is recommended. We will cover these in the following chapters.
In summary: SAST is a so-called “proactive” security approach, allowing for the identification and rectification of vulnerabilities before they can be exploited. Integrated within the development process, it reduces security risks and ensures better code quality. The aim is to keep a keen eye on the security of the source code throughout its lifecycle, avoiding errors that could be exploited in production by malicious actors.
Dynamic Application Security Testing (DAST), is an analysis technique that focuses on detecting vulnerabilities in a running application.
Essentially, it’s an automated black box intrusion test that identifies potential vulnerabilities attackers might exploit once the software is in production. These vulnerabilities can be SQL injections, Cross-Site Scripting (XSS) attacks, or issues with authentication mechanisms.
One advantage of DAST is that it doesn’t require access to the application’s source code. When used in conjunction with SAST, it provides more comprehensive security coverage. Indeed, DAST can detect vulnerabilities that might go unnoticed in a static analysis and vice versa.
Numerous products with overlapping features exist. They generally allow for automated vulnerability scanning that includes: fuzzing (random inputs), traffic analysis between a browser and API, brute force attacks, and vulnerability analysis in JavaScript code. The go-to DAST tool is OWASP ZAP (fig.
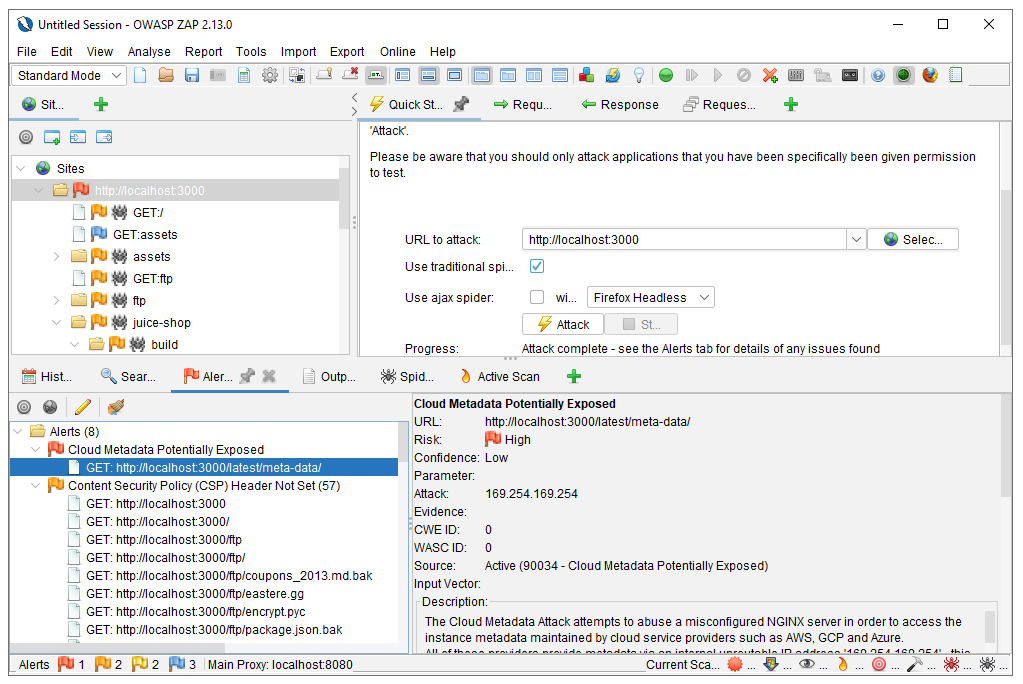
An extensive list of open-source and commercial code analysis tools is available on the OWASP foundation website89.
However, DAST isn’t a magic solution: tests can sometimes produce false positives or negatives, it cannot detect vulnerabilities or poor practices at the source code level, and advanced knowledge might be needed to configure the tests. Therefore, DAST tools should be used in conjunction with other security techniques, such as SAST and IAST.
In summary: DAST encompasses tools that analyze applications in real-time to detect potential vulnerabilities. It complements static analysis (SAST). By integrating DAST into one’s software pipeline, it’s possible to ensure the security of applications throughout the software lifecycle: in development and in production.
Interactive Application Security Testing (IAST), encompasses tools that identify and diagnose security issues in applications, whether they’re running or during the development phase.
According to OWASP90, IAST tools are mainly designed for analyzing web applications and web APIs. However, some IAST products can also analyze non-web software.
IAST tools have access to the application’s entire codebase - just like SAST tools - but can also monitor the application’s behavior during execution - like DAST tools. This gives them a more comprehensive view of the application and its environment, allowing them to identify vulnerabilities that might be missed by SAST and DAST.
“IAST tools are fantastic! Can I just throw away my SAST and DAST tools?”
Of course not. Each has its pros and cons:
Whether DAST or IAST, tools typically require a solid understanding of the application to perform and interpret tests effectively. This often relies on engineers with deep expertise in the software being tested and, more broadly, solid security knowledge. Lastly, open-source solutions are rare in this domain, inevitably incurring costs. Both tool types are valuable but demand investment in time, human resources, and money.
In a mature DevSecOps infrastructure, SAST, DAST, and IAST approaches combine. All-in-one software dedicated to securing the development cycle and integrated within software repositories exists. Examples include Snyk, Acunetix, Checkmarx, Invicti, and Veracode.
Today, standards describe how one can properly secure their software pipeline. These are grouped under what’s known as security frameworks91.
Each of the frameworks presented in this chapter (SLSA, SSCSP, SSDF) contains a list of recommendations on security techniques to implement in one’s software pipeline. They advocate for the use of SCA, SAST, IAST, and DAST techniques.
The Supply-chain Levels for Software Artifacts framework (SLSA92, pronounced “salsa”) focuses on the integrity of data and artifacts throughout the software development and deployment cycle.
SLSA originated from Google’s internal practices. The company developed techniques to ensure that employees, acting individually, cannot directly or indirectly access or manipulate user data in any way without appropriate authorization and justification93.
In software development, you use and produce artifacts. These can represent a development library used in your code, a machine learning binary, or the product of compiling your software (a .bin, .exe, .whl, etc.). SLSA operates on the principle that each stage of software creation involves a different vulnerability and that these artifacts are a prime vector of threats (fig.
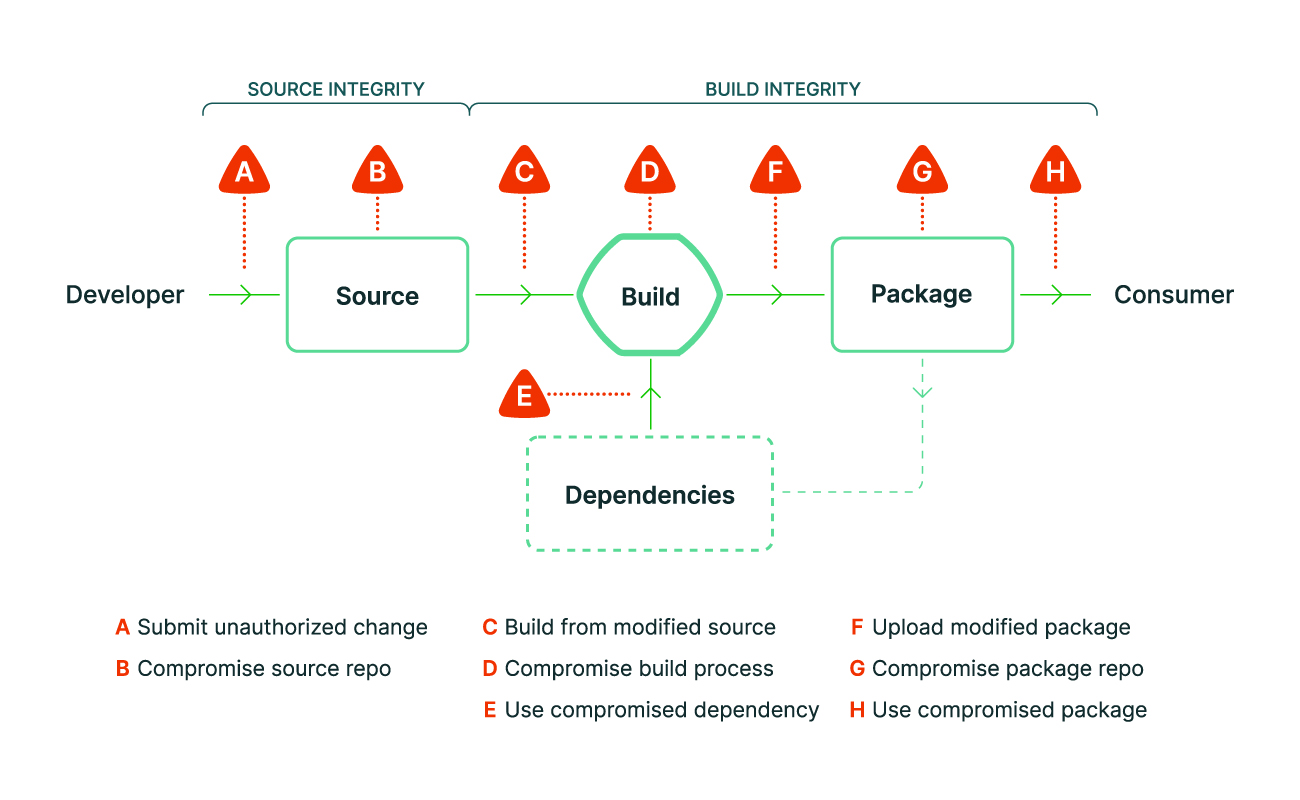
Its rules revolve around the automatic verification of the integrity of the handled data. Some examples of vulnerabilities addressed by SLSA include:
Based on a team’s technical maturity, it’s possible to apply SLSA rules across four levels of security and complexity. The idea is to progressively enhance the security of one’s software chain over time.
SLSA consists of two parts:
The FRSCA project94 is a pragmatic example of a software factory implementing SLSA prerequisites. Integrations within GitHub’s continuous integration chains, like the “SLSA Build Provenance Action”, are also available.
SLSA documentation is regularly updated by the community95 and available on its official website.
The Software Supply Chain Security Paper specifications (SSCSP or SSCP) from the renowned Cloud Native Computing Foundation (CNCF) complement the SLSA. Historically, they cover a broader range of topics, but many recommendations overlap today.
Although SLSA offers more interactive, well-illustrated documentation (with examples of tools to use or threats for each rule) and is almost gamified with its “security level badges”, SSCSP appears - at the time of this book’s writing - to provide a more high-level view of threats within a software chain.
Author’s note: For beginners, I recommend starting your software factory security project with SSCSP, then advancing with SLSA.
This document is also collaborative96 and broadly belongs to the standards97 adopted by the CNCF’s Technical Advisory Group (TAG). The TAG writes various reference documents aimed at enhancing the security of the cloud ecosystem98.
The Secure Software Development Framework (SSDF99) is a document drafted by the National Institute of Standards and Technology (NIST) of the US Department of Commerce for all software publishers and buyers, regardless of their affiliation with a government entity.
NIST deserves recognition for the variety and quality of their reports on cutting-edge technologies and techniques. Their works often result from collaboration with numerous institutions and private companies, such as Google, AWS, IBM, Microsoft, the Naval Sea Systems Command, and the Software Engineering Institute.
More comprehensive than the previous two, SSDF acts as a directory consolidating recommendations from dozens of other frameworks (e.g., SSCSP, OWASP SAMM, MSSDL, BSIMM, PCI SSLC, OWASP SCVS100). It categorizes them into four major themes: preparing the organization, protecting software, producing securely developed software, and addressing vulnerabilities.
The framework lists general concepts progressively associated with more concrete rules. Each theme encompasses broad practices to follow, which in turn include tasks with examples linked to the relevant frameworks.
For example, under the “protect software” theme, the “protect all forms of code from unauthorized access and tampering” practice suggests using “commit signing”101, referencing the SSCSP in its “Secure Source Code” chapter.
This document can be found on the NIST website. The online library of the Chief Information Officer102 (CIO) from the US Department of Defense is also an excellent source of inspiration.
GitHub is the most popular code-sharing platform on the Internet. It hosts over 100 million projects with more than 40 million developers contributing to it. As a pillar in the open-source field, it offers security tools natively integrated into its platform.
GitHub’s aim is to ensure that securing one’s code requires just a few clicks to activate the appropriate tools.
The company made a strategic move by acquiring Semmle in 2019, a tool for analyzing vulnerabilities in code. Since then, it offers several means to secure its codebase:
SCA and SAST: Automated vulnerability analysis tools for the source code and its dependencies (e.g., SQL injections, XSS flaws, configuration errors, and other common vulnerabilities). GitHub also has a marketplace that allows adding code analyzers from third parties. You can add your custom rules by writing CodeQL files. You can deploy these tools on your infrastructure, for instance with GitHub Code Scanning (fig.
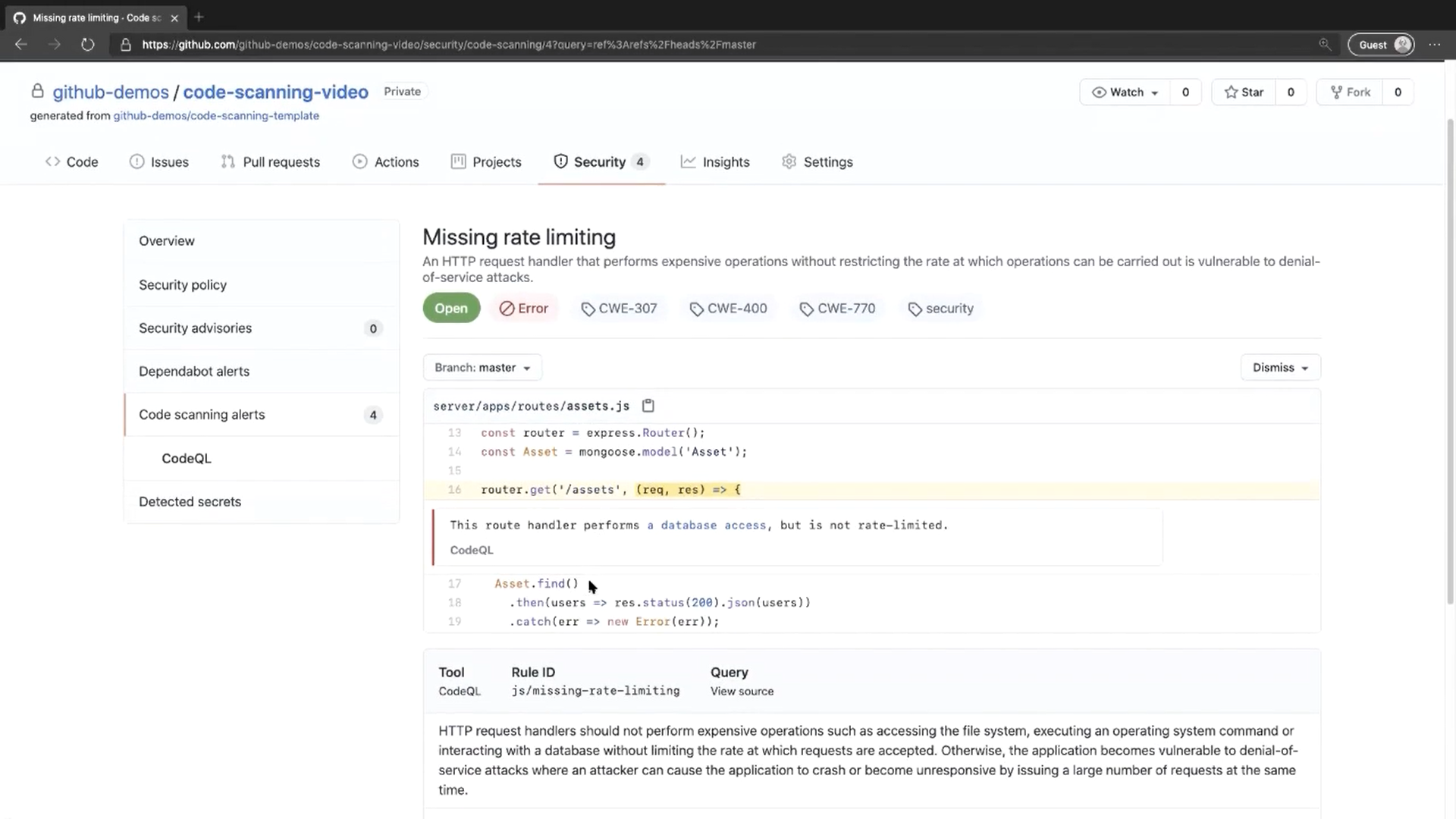
Secret Analyzer: Analyzes, detects, and alerts on potential passwords or tokens inadvertently left in the source code. Open-source alternative: Gitleaks.
Dependabot: A dynamic analysis tool for risks associated with used dependencies (e.g., vulnerabilities, unmaintained libraries, legal risks). Dependabot automatically opens a code modification proposal (pull-request) on the project and suggests updating the dependency or an alternative (fig.
All security flaws related to a project are centralized in an overview, allowing threats to be easily detected and addressed (fig.
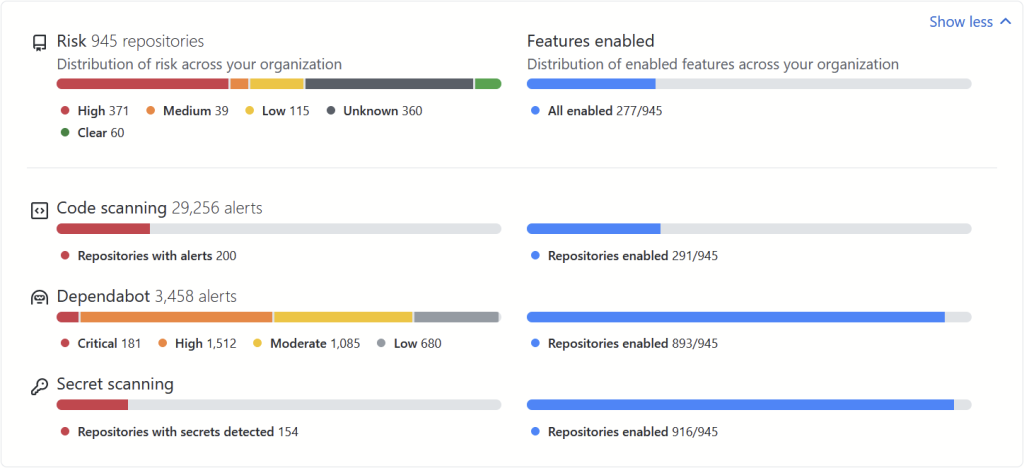
GitHub relies on the international CVEs103 repository (Common Vulnerabilities and Exposures) to recognize vulnerabilities, a list of identified vulnerabilities in IT systems described in a specific format. You can add additional verification mechanisms using GitHub Actions, GitHub’s continuous integration mechanism.
To mitigate risks, it is possible to base the software developed on pre-approved resources made available to developers. Every external component of the software is checked. This might include Python packages, NPM, Go, or even Docker images that have been analyzed, ensuring no vulnerabilities are present.
This is exemplified by the Iron Bank104 service set up by the U.S. Department of Defense within Platform One105. Docker images must undergo a rigorous validation process before approval. These steps combine manual checks with automated ones, but initially, only automated procedures may be employed. Manual actions are necessary to justify adding a new image. This is what Platform One teams call “continuous accreditation of approved images”106 (fig.
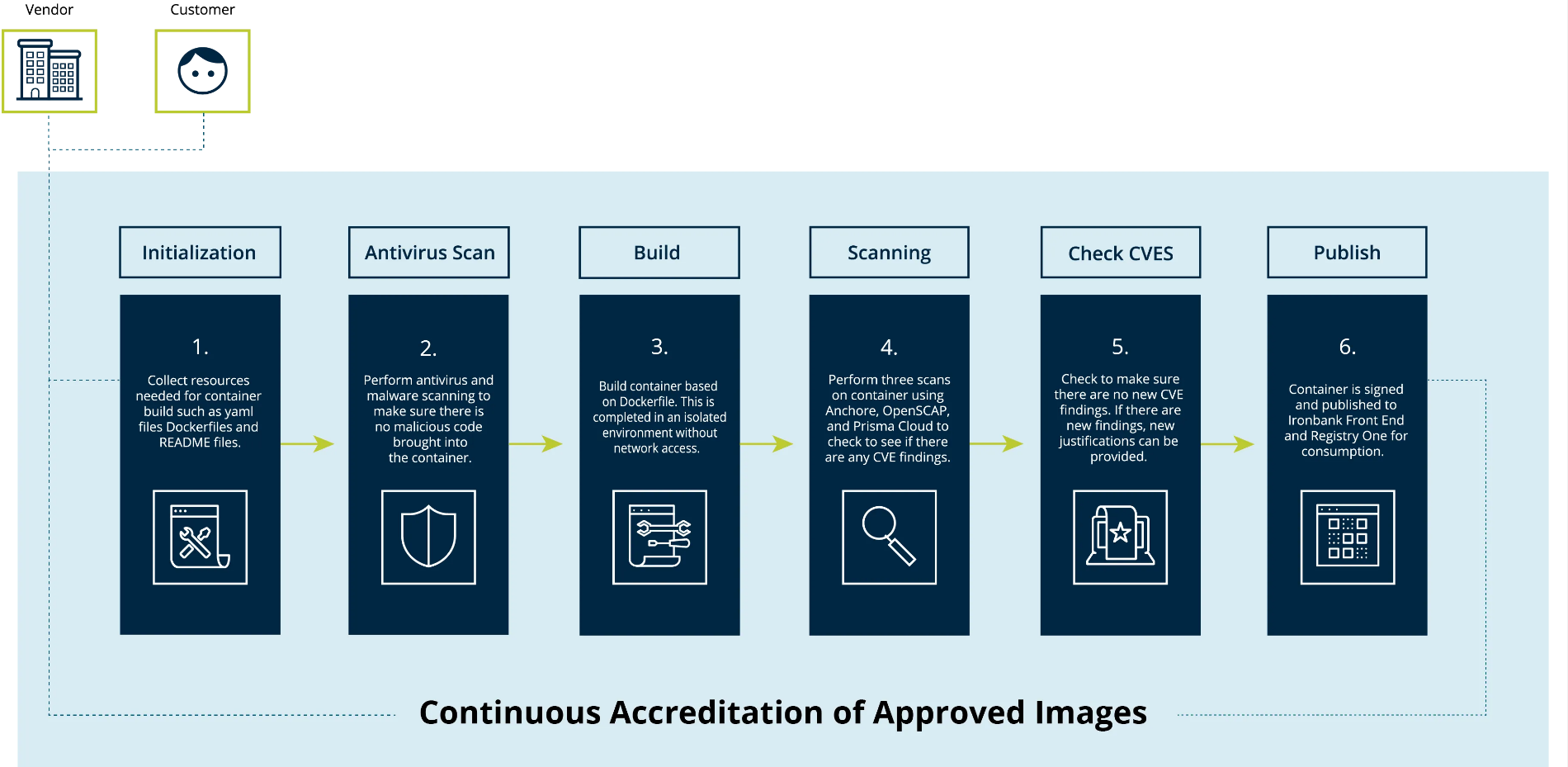
In organizations dealing with highly sensitive data (i.e., data that can jeopardize a country’s security or credibility if disclosed), the default policy is to authorize only the use of pre-approved libraries and images (hardened images). However, consider the impact of such a choice on development velocity. Ensure your security and SRE teams can keep up with provisioning libraries.
Since it’s nearly impossible to manually analyze each development library to ensure it’s flawless, software factories can rely on file signatures. Trusted editors sign each of their libraries107, so continuous integration pipelines or system administrators can verify it hasn’t been altered during transfer. Each trusted editor issues a certificate that the SRE team can integrate into its continuous integration pipelines to ensure downloaded packages haven’t been tampered with.
A simpler method is to use only the hash key of files. Each file is identified by a character string called a hash, which the computer can easily compute.
Example of a hash: a21c218df41f6d7fd032535fe20394e2.
If, during installation, the downloaded dependency has a different hash from the reference one (obtained online from the publisher’s website), the software launch is denied. This mechanism is mostly already implemented by programming language package managers (e.g., package-lock.json for NPM, poetry.lock for Python).
Humans are the primary vector for security risks108. To minimize errors or deliberate system compromises, modern infrastructures are deployed as “code”.
This means that for everyday infrastructure operation (except in emergencies), every administrative action is coded, published, and verified in the software factory before deployment. This allows for standardizing, documenting, replaying, and optimizing administrative actions over time.
The field encompassing production management techniques through code is commonly called Infrastructure as Code (IaC). This concept and its relevance are described in the “Infrastructure as Code” chapter.
Figure prod-fr-zone-c-server-18.

The above example is simple, but IaC can describe how machines can be instantiated and configured. An IaC setup can fully configure a machine from scratch (network settings, security certificates, adding users, printer drivers installation, browser favorites setup, etc.). The idea, once again, is to minimize human intervention to avoid mistakes.
The zero trust concept can be summarized in one phrase: “Never trust, always verify.” This practice has become imperative, with 55% of companies reporting having implemented a zero trust initiative in 2022, up from 24% in 2021109.
Traditionally, network security was based on defining a “trusted perimeter” drawn around an organization’s software and data. Various tools and technologies were then implemented to protect them. This network architecture, also known as “castle-and-moat”110 or “perimeter-based,” assumed that any activity inside the perimeter was trustworthy and by reciprocity, any activity outside it was not (e.g., network access via a VPN or based on a machine’s MAC address).
Zero trust assumes that no user is “trusted” by default, whether inside or outside the perimeter. Users must be authenticated and authorized to access data and software. Their activity should be monitored and recorded. This approach is more effective at defending information systems against sophisticated attacks, as it doesn’t assume that all activities inside the perimeter are trustworthy. This network security model has especially evolved due to the massive shift to remote work111.
Consider an example: Sophie is a colleague you’ve known for 3 years. She badges in every day and settles at her workstation. Days later, you learn Sophie was terminated a month ago. She might have accessed strategic company information, which she could use at her new job in a competitor company. Merely being “used to” seeing an employee allowed the company’s precious information to be stolen. With zero trust technologies providing centralized access management, Sophie couldn’t have logged in.
Three pillars constitute a zero trust network architecture (fig.
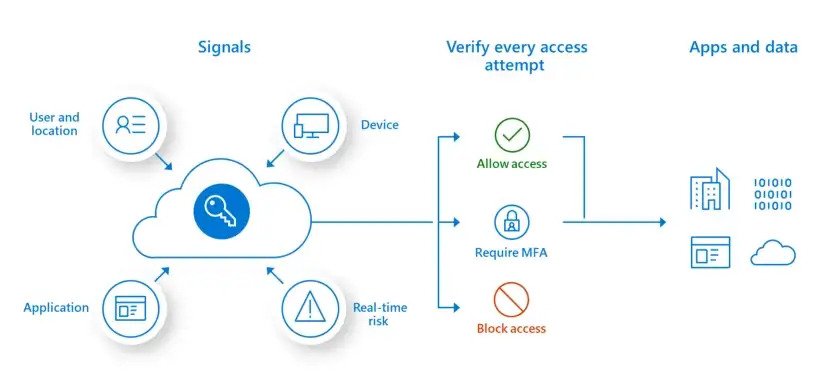
In zero trust, each request involves a fresh security check. The trust broker or CASB112 verifies these criteria (e.g., OpenID, Active Directory, PKI, SAML).
CASBs are integral to technologies known as “Zero Trust Network Access” (ZTNA) in implementing zero trust architecture. Cloudflare, Cato, Fortinet, and Palo Alto are examples of ZTNA technologies113. Think of them as advanced proxy servers that continuously check multiple security criteria set by your organization. If you’re looking to adopt zero trust, refer to the SASE framework114.
Because of the many tools involved, setting up a zero trust model is less straightforward than perimeter-based security but overcomes its limitations115.
Beyond the pressing need to bolster resource access security, zero trust architecture offers peace of mind from a secured infrastructure. It simplifies device and network equipment administration (centralized management of network flows and access rather than configuring each device), reduces costs (maintenance time, shared machines), and standardizes identity and user rights management interfaces.
Technological innovation demands swift adaptation. Zero trust enables organizations to quickly and securely adapt to environmental changes without revisiting their security stance.
Reference documents such as Google’s Beyondcorp research paper116, NIST’s publications117, or the US Department of Defense’s papers118 provide specifications for deploying state-of-the-art zero trust networks.
In the context of a Research & Development (R&D) environment, the topic becomes more intricate. To remain innovative, your teams require flexibility. They make use of cutting-edge libraries, install the latest GPU drivers for machine learning experiments, and even test the performance of their software, fully utilizing the resources of their machines.
In essence, your teams need complete access to their machine’s configuration for effective development.
However, as mentioned earlier, the third rule of a zero trust architecture is to ensure the user’s machine is secure. If you grant a developer administrative rights, they might be tempted to disable their machine’s security settings. So, what’s the solution?

Development workstations (fig.
We are faced with a dilemma here. We can choose to grant our developers full permissions, but risk them disabling our security measures. Alternatively, we can limit these permissions, potentially slowing down their development velocity and ability to innovate, while also needing to invest more time in training them for an unconventional work environment (since it’s controlled).
Several factors should be considered:
There are several ways to address development environment challenges. Here are 6, categorized by user flexibility, implementation complexity, and associated risk:
| Method | Flexibility | Complexity | Risk |
|---|---|---|---|
| Bring Your Own Device | Maximum | None | High |
| Semi-controlled machines | Maximum | Rather Low | Medium |
| Fully controlled machines with cloud dev. environment | Medium | Medium (Codespaces) to High (Coder) | Low |
| Fully controlled machines with remote dev. VM | Medium | Medium | Low |
| Fully controlled machines with local dev. VM | Fairly High | High | Very Low |
| Fully controlled and equipped machines | High | Very High | Very Low |
The more you want to reduce risk while increasing flexibility (boosting security while promoting innovation), the more your infrastructure teams will have work or incur costs (e.g., outsourcing). Consider the factors inherent to your organization and its operating mode to choose the solution that best fits it.
Administrators of an infrastructure regularly handle “secrets”: passwords or tokens. It’s common to exchange them among administrators. In other cases, we might need to share an account password with the relevant person. Password managers are a great way to centralize and share these resources.
You can manage your passwords in them and share them granularly with other users. Each user has their own account to access the secrets they have the right to see. It is recommended to use them as much as possible.
Working on a network allows you to use these tools. Here are some collaborative password management services: Vaultwarden, Bitwarden, Lastpass.
The foundation of an IT infrastructure comprises the set of technologies that allow software to be deployed on it. Typically associated with it are core services essential for the proper functioning of the infrastructure: a PKI125, a centralized authentication server (e.g., LDAP), an NTP time server, or an Active Directory126.
For engineers responsible for deploying software, the foundation provides common services to avoid deploying them with each piece of software. With these services centralized, administrative tasks are simplified. In a Cloud foundation, this concept is extended beyond a traditional foundation. This is made possible by the use of standardized technologies that simplify interactions with deployed software (e.g., Docker containers, Kubernetes).
Let’s compare a traditional foundation with a Cloud foundation to better understand the latter’s added value.

In a traditional foundation (fig.
The robustness of this type of foundation is well-established and is still widely used today among major institutions. The isolation is highly effective.
However, the maintenance needs for this kind of foundation increase proportionally with the number of deployed software. Each software comes with its installation instructions, supplemented by foundation compliance documentation. Installation and configuration are often manual. As organizations tend to install more and more services over time, to continue meeting business needs.
In summary, here the deployed software is forced to adapt to the foundation. This generates technical debt. Moreover, centralized foundation services, like those for logs or metrics management, might not always exist.
This type of foundation is effective with a reasonable number of deployed services, but it doesn’t scale easily without proportionally sized HR.
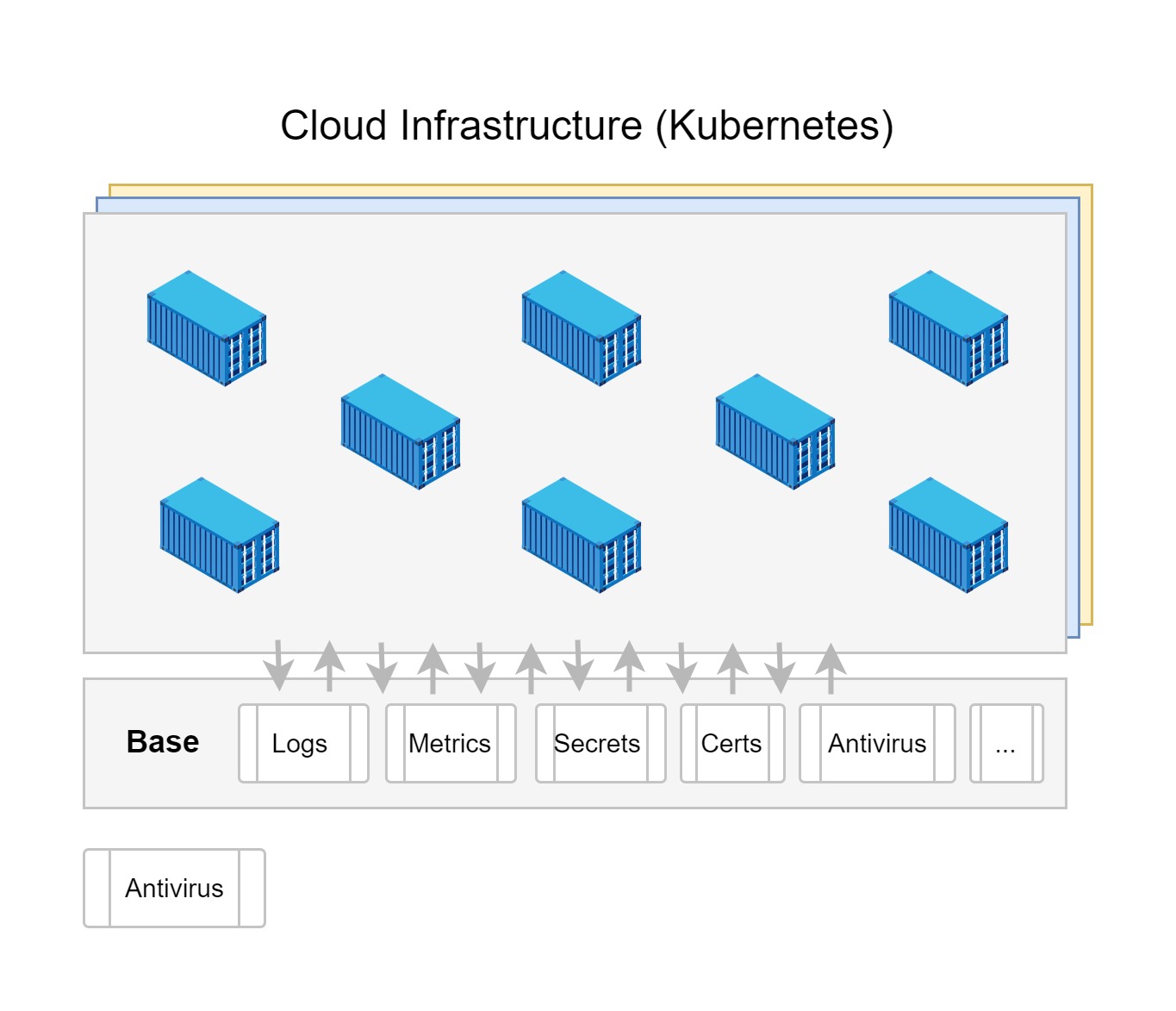
In a Cloud foundation (fig.
For instance, application logs or performance metrics can be automatically retrieved and stored in a centralized tool, then set up with alerts. An antivirus that continuously checks for threats in a container can be installed. Kubernetes’ sidecars128 mechanism makes these capabilities possible.
Data flows between containers can be encrypted by default (use case: two services running on different servers). Secrets (passwords, tokens) can be supplied by the foundation without an administrator seeing them. Persistent data (volumes) are managed uniformly, and backups can be automated.
The benefit of this kind of foundation is that it integrates all these services automatically, without ever touching the application code, nor even requiring the integrator to know about your infrastructure. Thus, you are guaranteed that all deployed software conforms to your monitoring and security requirements. It’s the foundation that adapts to the deployed software.
Installation mechanisms standardized by Kubernetes (e.g., Kubernetes manifests, Helm129) require just a few commands for software deployment. Kubernetes will automatically instantiate new containers or nodes if user load is too high. We will discuss the technical aspects of these technologies in the chapter “Extensions to simplify infrastructure”.
If your organization consists of staff already trained in ESXi technologies, or if your organization’s SSI rules are not ready for a Cloud foundation, it’s still possible to set up a Kubernetes cluster on your traditional ESXi infrastructure. This could be considered in a transformation plan, at the cost of temporarily increased technical debt while your historic teams get trained in Cloud technologies.
In terms of security, containerized technology interfaces are standardized. It’s no longer about checking the container’s contents since the infrastructure takes care of it. It’s about ensuring the security of containerization technology (e.g., Docker, CRI-O), as well as orchestration technologies (e.g., Kubernetes, Rancher, OpenShift).
For example, have you ensured that Microsoft Word is secure through certification? However, every Word file doesn’t need to be certified separately. It’s the same for a containerized application: whether coded in Python, Go, PHP, or embedding the latest libraries, it’s the container running it that needs certification.
In conclusion, treat your foundation as a product serving your engineers. The more you centralize and automate the use of this foundation’s services, the less technical debt you’ll have to maintain (see chapter “Leveraging automation”). Ultimately, this effort results in better service availability for your customers.
With microservices at the heart of Cloud DevOps infrastructures, containers seem like the ultimate deployment solution. Virtual machines become redundant, as orchestrators (e.g., Kubernetes) can be installed directly onto the machine. This is referred to as a “baremetal” installation. However, during a transformation, it’s imprudent to outright discard VMs.
There are rare cases where you can overnight shift from your existing production infrastructure to a cloud setup. If your teams are accustomed to managing VMs, they need time to familiarize themselves with these new technologies. Similarly, applications require time to migrate to a compatible format.
To progress, set a goal to reduce VM usage. For example: “In 1 year, at least 80% of our software should run in containers” Or: “Any new software must be containerized for deployment”. This involves setting up the prerequisites mentioned in the “Prerequisites” chapter, as well as implementing DevOps tools: a software factory, container image registries, and a containerized deployment environment.
Here are several complementary situations where VMs remain valuable:
However, remember that maintaining this abstraction layer (VMs) to solely manage Kubernetes on top adds complexity to your infrastructure. As practices evolve in your organization, consider removing these layers. But maintain the flexibility to instantiate them when necessary.
Within a Cloud DevOps infrastructure, tools like KubeVirt or Virtlet can be used to spin up VMs within a Kubernetes cluster. This can facilitate a smooth migration of your legacy applications while getting your teams hands-on with cloud technologies. More visual tools like OpenStack can also assist the transition to this ecosystem, more seamlessly than the traditional command lines in a terminal.
Open-source technologies represent 77% of the libraries used in proprietary (or “closed-source”) software131. Among the top 100,000 websites, Linux - an open-source operating system - is used in nearly 50% of cases.
A European Union report132 states that in 2018, contributions from Europeans to GitHub - the world’s largest open-source contribution platform - equated to 16,000 full-time positions. That’s close to a billion euros for companies in Europe. These contributions offer a cost/benefit ratio of 1 to 4, allowing businesses to remain cutting-edge, develop quality code, and reduce maintenance efforts.
For instance, software like the Firefox browser, the Python programming language, or the Android operating system wouldn’t exist without open-source. Even the proprietary software icon, Microsoft, began its open-source contributions to the Linux kernel in 2009. In 2014, its new CEO, Satya Nadella, proclaimed, “Microsoft loves Linux”133. Despite criticism134, the company even acquired GitHub in 2018 and seems to continue delivering satisfaction to the community135. They continue contributing to numerous open-source projects listed on opensource.microsoft.com.
However, where the use of open-source in the private sector is a no-brainer, technical teams in large organizations sometimes face skepticism from wary project managers. These teams are challenged regarding their use of open-source technologies based on security concerns.
Such skepticism isn’t without merit. The idea of importing a third-party library into one’s IT system without examining its contents can seem risky. Potential risks include:
So, it’s about striking a balance between the productivity provided by open-source libraries/software and the trust we place in them (security).
Yet, it’s a mistake to believe that simply buying software will ensure its security137. Although responsibility is outsourced, the damage, if it occurs, is done. Google’s engineering heads predict that by 2025, 80% of businesses will use open-source technologies maintained by salaried individuals138 (e.g., GitHub Sponsors).
Historically, the official policy for approving certain libraries went through a certification cycle, aimed at mapping the risks associated with using a technology to decide whether to accept it. This decision could be supported by a code audit.
For proper protection, maintain an active and systematic watch for security threats introduced into the code. In DevOps mode, your software factory is equipped with tools to detect dependencies or malicious code. You minimize risks by securing your software chain (see chapter “Securing Your Software Supply Chain” and job sheet “IT Security Engineer”).
For example, if you can’t set up a secure software forge yourself, you can use GitHub features (see chapter “GitHub’s Example”). More broadly, security practices at GitLab139 are a great starting point.
Joining a bug bounty platform is common among large enterprises, both to analyze their websites or the open-source software they use140. A bug bounty system rewards individuals for identifying vulnerabilities, aiming to detect and fix vulnerabilities before they’re exploited by malicious hackers. Popular platforms in this area include Hackerone, Bugcrowd, Synack, and Open Bug Bounty.
In a mature organization, you could even open an Open Source Program Office (OSPO)141, responsible for defining and implementing strategies around the use of and securing open-source technologies employed in your organization.
Finally, major tech companies often release new software as open-source. These quickly become standards used by tens of thousands of developers worldwide. This facilitates the onboarding of engineers to their technologies without incurring training costs. These companies thus find themselves with candidates already proficient in their technologies.
Far from benefiting only these companies, this practice benefits the entire sector, which now has a pool of candidates familiar with the same tools and practices.
To excel in system resilience, as in any field, training is necessary. That’s why one of the recommended practices in SRE (Site Reliability Engineering) is to train to handle incidents. The objectives are as follows:
To ensure that its teams are well organized in case of an incident, Google has designed two types of training142. The goal is to reduce the Mean Time To Mitigation (the average time to resolve an incident, cf. chapter “Measuring the success of your transformation”), which would impact the company’s service contracts.
Amazon Web Services (AWS) offers a similar approach named Game days144 to Google’s Wheel of Misfortune. The company lists its critical services and the threats that can be associated with them (e.g., data loss, overload, unavailability) to determine a “disaster” scenario. Subsequently, the idea is to provision an infrastructure identical to the production and cause the desired failure. It then observes how its teams and production tools react to the incident.
These trainings are more commonly called fire drills. Again, their goal is to practice incident response in an urgent situation. During these trainings, someone should note any incomplete or missing elements in existing procedures or tools, with a view to improving them.
Netflix goes even further with its tool Chaos Monkey which automatically, randomly, and at any time stops production services. The goal is to ensure that customers continue to have access to Netflix, even with one or more internal services down. Their tool Chaos Gorilla even goes as far as simulating the shutdown of a complete AWS region (e.g., a datacenter that would be taken out of service) to observe its consequences on the platform’s availability. These practices are part of what is called chaos engineering.
Finally, apart from audit software that can detect some vulnerabilities (e.g., Lynis, Kube Hunter), there are other exercises for your security and SRE teams to practice.
The most popular way to assess the security of your infrastructure is the “blue team / red team” exercise. Inspired by military training, it consists of a face-off between a team of cybersecurity experts trying to compromise an information system (the red team), and the incident response teams (the SREs, the blue team) who will identify, evaluate, and neutralize the threats. The idea is to avoid relying on the theoretical capabilities of your security systems, but to confront them with concrete threats to assess their usefulness and weaknesses. Variants exist with a purple team, a white team, or even a gold team. But start by setting up a simple scenario. For example: one of your developers who introduces a Docker image or tainted code.
This topic is vast and practices vary depending on the size of the organization you are employed in. This chapter gives you some references to start your training practices. Structure them subsequently according to your objectives and resources.
Here we reach the heart of the matter. In this chapter, we will discover the different pillars of DevOps, describing the various practices and technologies that can meet our challenges.
In terms of organization, see DevOps as a way to apply “healthy pressure” on your teams, encouraging everyone to move in the same direction. It is about optimally communicating everyone through standardized technical tools.
The desire to eliminate silos within an organization is a common mistake. Let’s see it differently: a silo is a concentration of knowledge; it’s expertise.
It’s fortunate that your organization has silos. For instance, they might consist of experts in organic chemistry, experts on the political science of a specific world region, or masters of a particular technology.
The creation of a silo is often essential to cater to an expertise requirement. This silo becomes necessary because this specialized expertise requires a structure tailored to its tasks (specialized tools and practices, advanced machinery, specific standard rooms). The key is to have tools and practices to let this silo communicate with the rest of your organization.
Undesirable silos emerge when the company doesn’t provide teams with the tools they need to work effectively. Individuals then take initiatives to find more efficient alternatives. This is a predictable “immune” response when employees face deteriorating work conditions.
For instance, your expertise center is aging and doesn’t renew its tools. Faced with an ever-increasing workload and the company’s inaction, long-standing employees become frustrated. Some become disheartened at the thought of discussing issues with unresponsive managers. Others try introducing new practices but face outright refusals. Then, new employees join and find that their working conditions are below expectations. Knowing of an extremely efficient software, one new employee introduces it. Its compelling efficiency makes it popular and spreads throughout the center and then the company. Of course, the employee won’t discuss this with the management, risking criticism and potentially having this new tool banned.
Due to the management’s failure to anticipate decline or heed internal feedback, they initiate a transformation project. Concurrently, the isolated initiative, undertaken without informing management, leads to scope conflicts and unclear objectives. Management becomes increasingly disconnected from their teams, unaware that they’ve adopted new practices. The lack of communication with other employees and duplicated efforts become noticeable. This is the result of a lack of overall coherence—a fertile ground for resistance to change in the face of the leadership’s belated reaction.
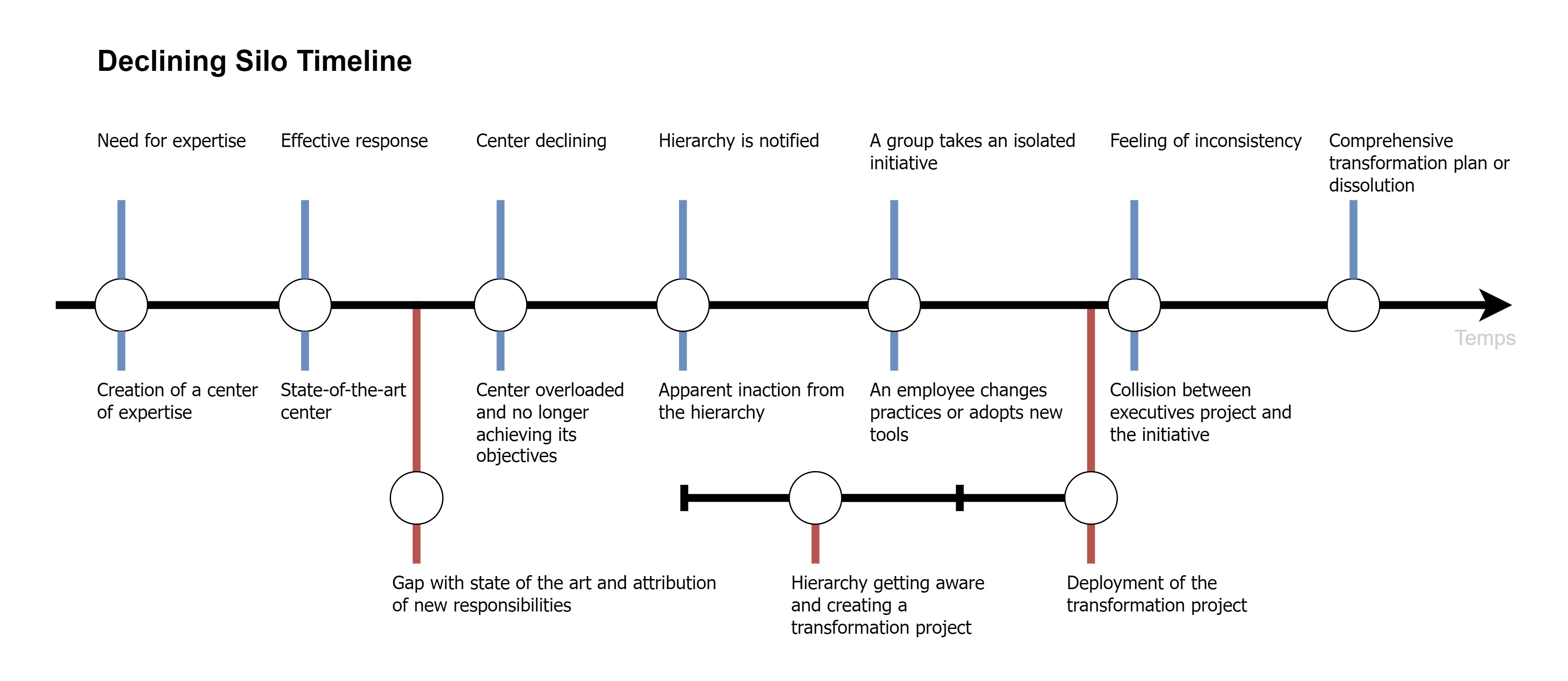
To prevent the decline of a silo that would spread company-wide (fig.
The DevOps movement believes in using common methodologies and tools to facilitate these exchanges. This chapter outlines the methodologies to adopt to achieve this objective.
To achieve a successful transformation, one must have a comprehensive view of the starting environment. Mapping it is a vital step that lets you understand the reality you’re operating within and gauge the investments required.
Your environment’s map should answer the following questions:
By having a clear, substantiated overview of how the company is organized, you’ll pinpoint critical areas to address. Use this document as your starting point and iterate on actions to take.
Imagine for a moment data-scientist teams within each of your organization’s offices. Fantastic! Every department has dedicated technical support to process their data. However, soon these teams of engineers begin communicating and realize they are working on the same topics. They notice they’re developing the same things. This is frustrating for them, but it primarily means the company is wasting money.
If no one is aware of what the other is working on, efforts will naturally be duplicated. In large organizations, needs are often systemic: offices encounter the same problems with minor variations. Technical solutions can often address these problems in 90% of use cases.
By working on a unified network, all your documents and data are shared. Gone are the questions like “Has the Marketing department provided all the stats?”, “Where’s the latest version of this presentation?” or “Where is the procedure to apply for holidays?”. Everyone virtually works in the same place. No more wondering whether a folder’s content is up-to-date.
Engineers can share technical environments instead of redeploying infrastructure in every office. For instance, there’s no need to duplicate a mirror of development libraries on two machines a few offices apart. For machine learning, a network allows for the shared computational power by utilizing resources from a central supercomputer.
In many large organizations, the main obstacle to adopting internally developed software is the network they’re deployed on. Teams are forced to deploy on a different network from the departments due to information systems security concerns.
To make their software accessible on the departmental network, validation is often required. For any developed software, this process can take several months to a year. If these teams deploy dozens of updates every day, enduring such delays is impractical (see chapter “Security: a new paradigm with the DevOps approach”). In the end, the users you have the least time to assist will abandon your tools because the time irritant will become too significant for them.
Using a unified network is key in adopting your new tools. It allows your organization to save money, and your collaborators to be less frustrated by delays.
In the next chapter, we will see how a software factory is organized and how, thanks to a unified network, it greatly increases the productivity of the organization.
The software factory is at the heart of your DevOps infrastructure. This is where your engineers will spend most of their time: if they’re not coding in their IDE145, they will be managing their projects in the software factory.
A software factory consists of a software forge and services allowing your engineers to develop and deploy software on your infrastructure: container image registries, dependency mirrors, artifact/binary repositories (see Nexus146, Artifactory147, Distribution148). Nowadays, most of these features are directly available within software forges.
The most popular software forges are GitLab and GitHub. GitLab is more commonly found in large organizations since it is simply and freely deployable on isolated networks. Other platforms like Froggit149, Gitea, and Bitbucket also exist.
As we will see in the chapter “GitOps”, in DevOps, all software source code and all production configurations are stored as code within a software forge. It’s thus said to be the “single source of truth” of your infrastructure.
Without a software forge, development teams would each work in their local folder and exchange code via network folders or USB sticks. This would waste significant time when merging code from multiple different contributors and would create numerous security issues. Needless to say, there’s no way to trace actions or recover files in case of accidental deletion. Additionally, project management teams would be entirely left out of the software development cycle.
The most popular software forges rely on the git technology150, allowing for tracking every contribution. Thanks to git, it’s possible to know who made which change and when. You can track the history of contributions and easily manage merging these contributions. We will delve deeper into these mechanisms in the next chapter.
Today, development, sysadmin, InfoSec, and management teams collaboratively work on such platforms, capitalizing on:
The goal is to store as much knowledge as possible in one place, ensuring the most up-to-date documentation is always consulted (fig.
git is a means to consider for capitalizing on guides, tutorials, and even administrative procedures for my teams. If someone spots an error or outdated information in documentation, they can directly suggest the modification in git to keep the document current.
Teams adopting DevOps are replacing traditional Word or Excel with Markdown (the format for documentation in git projects). This format, designed to be intuitive for both humans and machines151, is independent of any proprietary technology (e.g., Microsoft Word).
It’s even possible to create presentations in code form. These can be viewed in a simple browser (e.g., Markdown-Slides152 (fig.
Conversely, git is not designed to store large files. One should avoid storing large images, videos, binaries, or archives in it. Other technologies can store these types of files (see Amazon S3156, Minio S3157, HDFS158, CephFS159, Longhorn160) with or without a reference to a git project (e.g., DVC161).
However, the software factory is not just about capitalizing knowledge. It also serves as a control point for all contributions. An initial level of control is established by adding users to projects they have permission to contribute to.
But a second level of control can be set up: through continuous integration mechanisms (see chapter “Continuous Integration”), automated scripts can validate a contribution based on rules defined by your organization (software quality, SSI compliance). If the contribution doesn’t meet your standards, it’s rejected. The contributor sees it instantly, knows why, and can suggest a correction within minutes.
Since software factories can manage access to resources based on a user’s profile, it’s entirely possible to open yours to external partners (e.g., contractors). They can then add their software following the rules established by your organization and will immediately know how to comply. These rules are defined internally by security engineers.
This is already the case with Platform One162, which opens its software factory to manufacturers contracting with the U.S. Department of Defense. Similarly, the NATO Software Factory is NATO’s software factory163.
However, transformation offers an opportunity to develop internal expertise before being able to define rules for others. You must master the technologies discussed in this chapter to ensure your platform’s security. So, work first on your internal projects before overseeing external ones. Each organization is unique but should have its internal experts to provide the best advice.
As described in the chapter “Code Reviews”, these reviews offer an opportunity to provide feedback on a contribution before it’s deployed. It’s possible to set rules so that specific teams (e.g., SSI team) must approve the contribution before it can be accepted. This mechanism can be seen as a “seal of approval”. Software factories contain all these contribution validation features to best ensure the software supply chain’s security.
Lastly, the software factory is where software developed by your teams will be built (compiled, formatted for deployment) and then deployed on your infrastructure. Analogous to the continuous integration principle, continuous deployment chains are responsible for deploying software according to rules defined in code (see chapter “Continuous Deployment (CD)”).
Caution: under no circumstances does a software factory allow your teams to develop software per se. The software factory provides resources for engineers to develop their software (dependencies, packages, binaries) but doesn’t allow for code writing or execution within it.
The software factory to a developer is what a brush set is to an artist: the set contains all the tools to paint, but the artist spends their time working on their easel. The developer’s easel is their IDE164 on their computer: they code and run their code to test it as they write it. Options for setting up development environments are described in the chapter “Zero Trust-Based Development”.
All these technologies help to bring teams closer together and unify practices within the organization. In the next chapter, we will explore how technical teams can organize themselves to collaborate effectively within a software factory.
GitOps is a methodology for Cloud applications based on continuous deployment (see Continuous Deployment). It uses git projects as a “single source of truth” for infrastructure and application configurations. Once capitalized in this way, the configuration is termed “declarative”. In other words, you “code” configuration files to define how to deploy your infrastructure.
The idea behind GitOps is to rely on code to determine the system’s desired state.
Synchronizing the desired state is achieved through specific technologies (e.g., ArgoCD, FluxCD). This approach provides a single source of truth for the entire system, facilitating change tracking, configuration auditing, and ensuring the infrastructure meets the company’s requirements.
Example: if you need to create a backup mechanism, you can code an Ansible playbook (see chapter “Infrastructure as Code (IaC)”), push it to a git project, and a continuous deployment chain will deploy the change. The target end state is described by code.
You can start by writing manually launchable IaC scripts and then choose an automated solution after maturing on the topic (e.g., an Ansible script automated by a continuous integration (CI) chain with deployment handled by ArgoCD, see chapter “Continuous Deployment”).
A git workflow is a method to organize contributions to a software’s code.
git allows for easy collaboration on code by providing a file history mechanism. But for effective collaboration, organization is essential.
Imagine several engineers working on a car on an assembly line. Robert works on the starter while Caroline ensures the headlights respond to commands. But when Robert turns off the car, Caroline can’t measure the current. They can’t work together simultaneously.
Due to a personal emergency, Robert has to leave quickly and is replaced by Marie. Unfortunately, Robert didn’t have time to tell Marie his progress. So, she has to guess based on what she sees.
It’s the same with software. Working in the same place at the same time leads to collisions. In git, when two people work on the same file and try to merge it, it causes a “conflict”. Some structure is necessary when developing a project. Otherwise, there’s a risk of accumulating technical debt and ending up with unmanageable software.
git operates on a branching principle. By default, only the main branch, main or master, exists. It’s considered “stable”. If an integrator has to deploy software in production, they will choose the code from this branch.
A developer wanting to design a new feature will create a new branch from the main branch. This results in a copy of the code where changes (commits) are at their discretion, without disturbing others. Once the feature is finalized, the developer can make a “merge request” towards the main branch. Figure
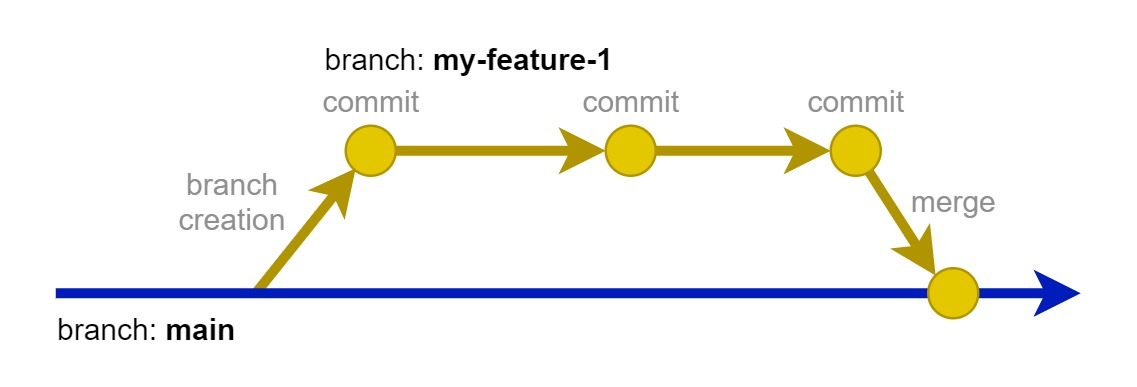
There are three questions to ask when determining a “good” git workflow:
Several methods have emerged over time165, but there are 4 main ones:
Release Branching: Suited for periodic software deployment (release), this method involves creating a new branch from the main branch and then stabilizing it with bug fixes and other changes before publishing.
Here, a release refers to a branch that evolves alongside the main branch for an extended period, eventually becoming obsolete.
It allows groups of developers to collaborate on a particular release or a customized version of the software for a client. This limits conflicts but complicates merging contributions between versions.
Gitflow: An extension of the Release Branching method, this uses 6 parallel branches166 addressing specific needs (release, hotfix, feature, support, bugfix, in addition to the main master or main branch). It’s historically used for managing very large projects (fig.
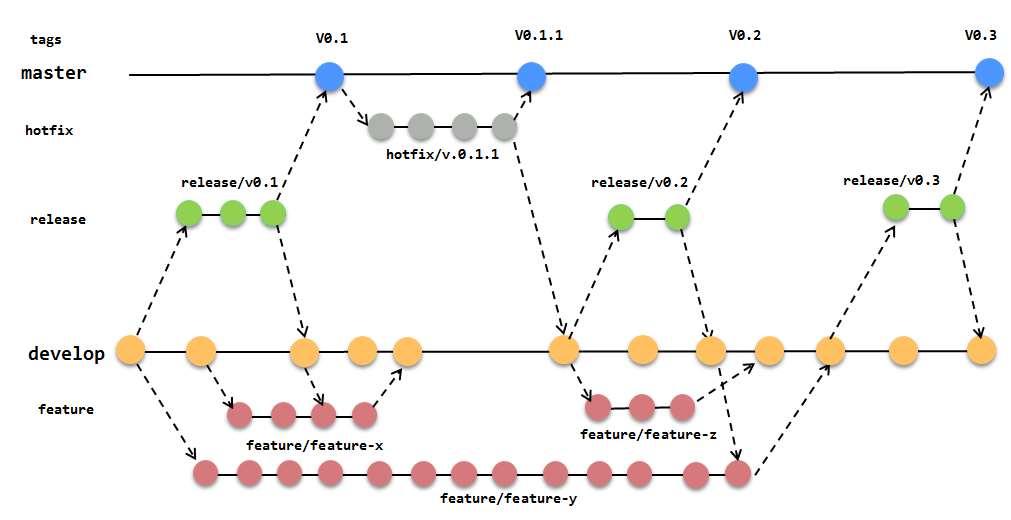
GitHub flow / GitLab flow: This method reduces the complexity brought by Gitflow by eliminating its 5 parallel branches to the main one (fig.
A developer should create a branch for each new feature from the main branch. A release can be created at any time from the main branch. Beyond its simplicity, the benefit is having a branch that always contains functional code and knowing it’s up-to-date at all times.
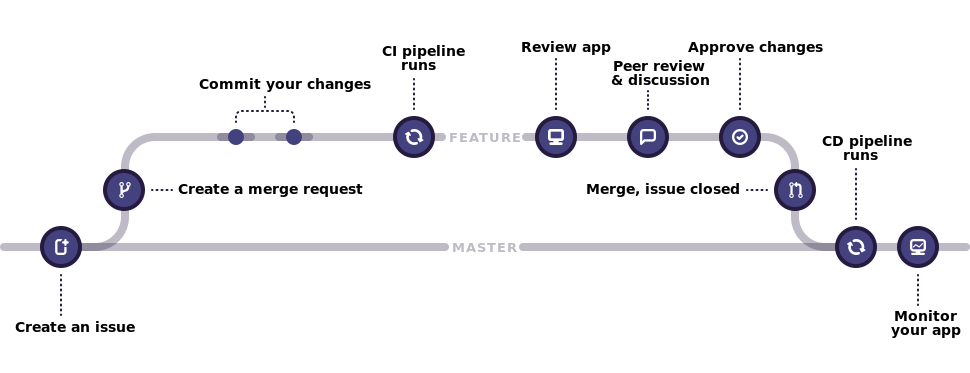
Trunk-based: This method promotes continuous deployment of software (see the chapter “Continuous Deployment”).
Unlike github flow, there’s only one branch here. Each developer pushes their code directly to the main branch (the trunk, fig.
This method heavily relies on CI/CD mechanisms because every contribution is checked (CI). If checks pass, the software can be automatically updated (CD) by creating a release. This ensures that the deployment mechanisms (CD) work at all times.
At scale, it’s advised to create very short-lived branches to benefit from code reviews (maximum 1 day).
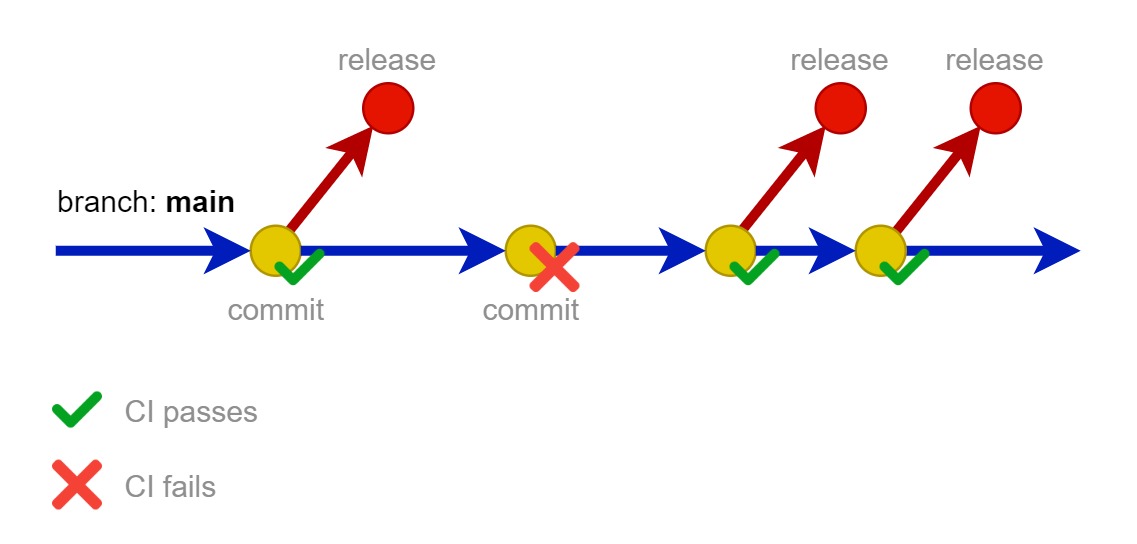
According to Atlassian, the state-of-the-art git workflow today is trunk-based development167. Google’s codebase is a good example: despite tens of thousands of daily contributions, they chose this method168.
However, you may not have Google’s engineering teams. Trunk-based development requires a specific rigor that only a seasoned technical team can handle. This method needs continuous integration chains that ensure the pushed code is valid (risking releasing a non-functional software version). It also involves creating optimized continuous deployment chains (as they’re frequent). Writing these chains takes time and requires experience.
If you don’t have a properly equipped team, it’s recommended to stick to github flow169.
But adhering to a common contribution methodology (branches, commits) isn’t enough. While collaboration might now be easier, you’re not equipped to understand everyone’s status. In the next chapter, we’ll explore a project management method.
You might not have a large team at hand but want to benefit from best organizational practices on your git project. This chapter provides insights into a method suitable for most development teams. It’s the one I use for the vast majority of my projects, whether professional or personal.
Drawing from the best of various Agile methodologies (Scrum170, Extreme Programming, Kanban171), it borrows their pragmatism without their organizational overhead. This methodology will be more suitable for a transforming hierarchy compared to the more demanding trunk-based development. IT managers also prefer it because it establishes software versions and facilitates long-term project maintenance. Finally, it allows both project managers and developers to easily track developments.
Named “Flexible flow” (fig.

To bridge project management and technical contributions, GitLab or GitHub projects use issues. These are tasks assignable to a collaborator, describing which feature to develop or which bug to fix (fig.
.")
With the Flexible flow, every contribution must refer to an issue that describes the task’s genesis, how it can be resolved, and centralizes stakeholders’ thoughts. Anyone can create these tasks (project manager, developer, user). The project manager then prioritizes them. Any newly assigned developer should know: what to do, where to start, and why by consulting the issue. Each is automatically numbered by the software forge.
Project Management:
Use the Kanban view of your software forge
Create four columns: Open, To do, Doing, Done
Create and document the issues (tasks) in the Open column
Create contribution type labels: type/bug, type/feature, type/iteration, type/refactor, type/documentation, type/discussion
Helps teams understand the nature of the contribution to be made.
Create contribution domain labels: area/backend, area/frontend, area/documentation, area/cloud (Docker, Kubernetes, CI/CD), area/infrastructure (Ansible, Terraform, AWS/GCP/Azure configuration)
Allows specialized teams to know which task to handle. For instance, on GitLab, any team concerned by a label can “subscribe” to it to know when a new task is added.
Create commercial value labels: business-value/p1, business-value/p2, business-value/p3, business-value/p4
Enables prioritizing tasks based on the commercial value the task realization brings:
p1indicates high commercial priority.p4denotes low commercial priority.
Create complexity labels: complexity/1, complexity/2, complexity/3, complexity/4
Allows for prioritizing tasks based on complexity and the time the task demands:
1is for a simple task, while4is for a highly complex or lengthy task.
Create priority labels: priority/low, priority/medium, priority/high, priority/critical
Helps prioritize tasks based on the current project development context (political or client priorities).
For each issue, assign a label from each category (domain, type, commercial value, complexity, priority)
Order the issues by priority: the higher an issue is in the Open column, the more important it is
Assign an issue to a team member and move it to To do
Limit assignments to 1 issue per available team member: this helps focus efforts.
Optionally, create a milestone to group issues meant for a specific software version. A milestone is often tied to a software release date (deadline).
Contribution Management:
main/master branch from which developers can branch off to add a contribution.f/#65-add-users-profile-page for issue no. 65 of feature type titled “Add users profile page” ;package.json) and make a release from the trunk branch.Other Recommendations:
Author’s Note: This method has proven effective over time in the projects I’ve contributed to. Easy to grasp even for beginners, I’ve refined it over time to be less cumbersome, yet addressing software technical debt issues and team turnover.
To introduce this methodology to your teams and easily access references, view its full-resolution illustration173.
Cloud technologies offer undeniable flexibility and allow for serving an increasing number of clients compared to traditional technologies. However, transitioning from a monolithic software to a scalable application requires adhering to certain design principles.
The 12-factor methodology (Twelve-Factor Methodology) encompasses a list of best practices for creating applications suitable for Cloud platforms. It summarizes the experiences of Adam WIGGINS and his engineers at Heroku. The aim is to prevent “software erosion”174, a phenomenon defined by the slow degradation of software over time, which eventually becomes faulty or unusable. In other words, it helps in creating applications that are easier to maintain, deploy, scale, and more resilient to failures.
The website 12factor.net, created by Adam WIGGINS, lists and details these principles:
package.json for NPM (Javascript) and requirements.txt for PIP (Python). They should be isolated during execution to ensure no dependencies are pre-installed on the machine. This can be achieved using Python’s virtualenv, Ruby’s bundle exec, or Docker for any language.mysql://auth@host/db and mysql://[email protected]/db without any code changes, as long as the technologies are the same.2022-05-07-21:33:18) and make the code immutable for that version. Any code change necessitates a new release.SIGTERM signal (graceful exit).stdout) as promptly as possible (without buffering). This enables the Cloud platform to easily process logs from deployed applications (see the chapter “A foundation for your resilience”).psql, or triggering a backup with a command. The idea is to facilitate script execution in the same environment where the software is deployed.Implementing these criteria - particularly breaking software into microservices - combined with continuous deployment pipelines, increases the chances of anticipating software incidents by 43% according to research177 (e.g., failures, vulnerabilities, or degraded service performance). Containerization is especially suited to these practices. Concepts of isolation are recurrent, and technology like Docker aptly addresses them.
Even though these are now standard practices in the industry, it might be beneficial to include them in a guide for newcomers.
A simple yet especially effective way to bridge the gaps between silos is to implement a shared instant messaging system. Through this medium, team members can quickly communicate without overloading their email inboxes, engage in group discussions about the next feature to develop, share snippets of code or documents effortlessly, foster cohesion by sharing memes, make general announcements, or even conduct polls to decide on a list of options. Beyond facilitating collaboration, messaging enables remote work or collaboration with decentralized teams (in other cities or countries).
In the context of system reliability improvement, messaging is the ideal location to centralize production alerts for SRE teams. System monitoring tools can be set up to raise alerts in a single location. SREs are immediately notified when an alert is issued. When set up properly, these alerts provide all the information the SRE needs to promptly address the issue. Production teams can also easily inform their users of actions they are taking on the production system.
Messaging platforms like Mattermost, Element, Zulip, and Slack come with built-in VoIP (calling) and video conferencing capabilities. Most also natively support integration with tools used in production (e.g., automatic notifications for every GitLab release, incident reports in chats, updates on the status page, postmortem timelines; see Rootly).
Several companies, like Scaleway, open their corporate messaging to their customers. This forms a community of mutual assistance and a knowledge base for new users. It fosters engagement and reassures potential users, knowing there will be someone to answer in case of problems. Users facing issues can ask their questions, to which another user or a company expert can respond. At Canonical and Prefect, there are even “Community Engineers” whose specific role is to help the community with issues they may encounter178. Some companies opt to charge entirely for this user support.
Large organizations are often hesitant about offering remote work to their employees. They fear that employees might not focus on company tasks.
If you need to convince your superiors, clearly list the objectives for the remote-working employee (with help from the previous chapter). If that doesn’t suffice, you might suggest the employee submits a daily work summary. However, this approach essentially tells the employee, “I don’t trust you to be diligent.” Think twice before proposing it.
Research179 has shown that a flexible work environment is linked to a reduction in burnout and an increased likelihood of an employee recommending their company.
Understanding different software architectures will help you grasp how software is deployed in cloud architectures.
Depending on your organizational maturity and team sizes, certain architectures will make your software easier to maintain, update, or ensure longevity.
This chapter introduces three renowned architectures and describes their pros and cons. Finally, we will explore how to progressively transition your legacy software into microservices.
A monolithic application (designed as a monolith) is developed as a single, indivisible entity where every function or module is interconnected. The software components depend on each other.

While initially easier to develop and use, software designed as monoliths complicates the addition of new features as they grow180.
Updates to one part of the system impact the entire application, necessitating extensive testing to ensure it functions as expected upon deployment. The potential “blast radius” of a bug is significant in such an architecture.
Many renowned software like Wordpress and Magento still employ a monolithic architecture today. However, the trend is shifting towards microservices architectures, which are more scalable and resilient181.
An application designed with microservices breaks down each software functionality into isolated services (e.g., email sending management, login management, order management). Each operates independently. Every microservice communicates with others using a predefined exchange format (an API182). Updates can be deployed without disrupting the whole system.

By splitting your software into microservices, you can parallelize team work on each part of your software. Each team develops and deploys independently.
But one of the major benefits of microservices is the ability to scale easily: the most in-demand services can be instantiated multiple times simultaneously to distribute the load. Some service orchestrators, like Kubernetes, allow automating this behavior183.
However, this architecture requires advanced tools to maintain hundreds of intercommunicating microservices. DevOps teams facilitate the implementation of such architectures. For instance, they provide developers with application templates (boilerplates) containing everything needed to kick-start a microservices application on its own infrastructure.
To enable fine scaling on isolated functionalities, so-called “serverless” architectures have emerged. The advantage of a serverless architecture over traditional micro-services approaches is multifaceted:
Included in this are Function as a Service or FaaS technologies184, Container as a Service (CaaS), serverless compute platforms or SCP185, self-managed storage services186, and self-managed messaging services187.
By only charging for resources when they are used, serverless represents a significant economic and ecological argument. These technologies can reduce your bill from tens of euros to a few cents every month.
For instance, Functions as a Service each represent an isolated feature of your microservice. If you know that only 10% of your functions are used 90% of the time, there’s no need to pay for 100% of the resources constantly.
Consider a specific case: you decide to start an email marketing campaign. Precisely the email sending function will be highly solicited for a short moment. There’s no need to scale the function that lists your products. The infrastructure will only provision instances for the email sending function.
However, serverless architectures require specific skills to maintain. They might also tie you to a Cloud provider’s proprietary technologies (see proprietary lockdown or vendor lock-in188) or explode costs if the use case isn’t suitable189.
Let’s summarize some advantages and disadvantages of each approach:
| Architecture | Advantages | Disadvantages |
|---|---|---|
| Monolithic | • Simplicity in development and deployment • Centralized management • Easy to test and debug |
• Difficult to scale • An update affects the whole software • Slower and less frequent deployments |
| Micro-services | • Scalable on-demand • Quick deployments • Isolated bugs and crashes • Language-agnostic |
• Specific skills needed to manage • Data format consistency to maintain (API) • More difficult to debug |
| FaaS | • No infrastructure management • Targeted scalability • Cost-effective for sporadic traffic |
• Vendor lock-in • Less control over the execution environment • Start-up time if unused (cold start) • Limited run duration |
The leap to switch from monolithic software to a microservices architecture is often significant. However, this approach provides unprecedented flexibility in development and makes scaling drastically more efficient. But how do you make this transition without disrupting your entire operation?
Deciding to switch to microservices is tempting but involves compromises. British software engineer and author Martin FOWLER enlightens us on the prerequisites your team must have before starting this journey190:
In essence, we’re talking about Cloud technologies and DevOps techniques. At this point, you just want to validate the development process of a microservice and deploy it automatically.
To practice creating microservices, decouple an initial feature that doesn’t need to be modified throughout your software. For example, an app’s authentication mechanism is often centralized in a class or function: create and interface this microservice.
The Battle of Alesia, fought during the Gallic War in 52 B.C., is often cited as an example of strategic military planning. Julius Caesar’s Roman army faces off against Vercingetorix’s Gallic army. Pushed back by the Germans - allies of the Romans - the Gallic military leader is forced to take refuge with 80,000 men in the oppidum of Alesia. Julius Caesar decides to build two fortified lines around the city to dislodge the Gallic army.
This stratagem allowed Julius Caesar to control the entries and exits from the area, to manage the number of soldiers arriving from the oppidum on one hand, and from the outside where reinforcements were pouring in on the other.
Without considering ourselves as great military leaders, we can still use this strategy to control, on one hand, the user load, and on the other, the flows either towards the monolith or towards the microservices we’ll progressively create.
That’s the second step in the journey: placing a proxy or a service mesh around our application (see chapter “Service mesh”). It will allow us to redirect each request either to the new microservices or to the monolith for functions that haven’t been migrated yet. For example, if we choose to extract authentication functionalities to a microservice, we will redirect requests starting with /auth to the authentication microservice.
A new rule should now be established alongside the transformation you’re undergoing: every new feature should be developed as a microservice.
Former Director of Emerging Technologies at Thoughtworks, engineer Zhamak DEHGHANI offers valuable insights in her article “How to Decompose a Monolith into Microservices”191. Let’s review a few of them.
One of her first pieces of advice is to avoid creating microservices that recall the monolith. Instead, prioritize calls from the monolith to the microservices.
The goal is to prevent a vicious cycle of changes that only serve to enrich the monolith. That’s why it’s essential to tackle the software’s core. Start by breaking down the most integrated functions that handle the main data of your project.
Prioritize the segmentation of functions hard to decouple by logical domain (e.g., product management followed by order management). Then focus on the most frequently updated parts of the software.
Lastly, consider rewriting a part of the code completely. Sometimes, legacy code is too complex, slow, outdated, or different from the current tech stack and needs a serious update. It might be more advantageous to rewrite it, especially if it lacks clarity.
These insights and tips will allow you to confidently approach the task of rewriting your software to better integrate it into a Cloud infrastructure, taking advantage of the agility it offers your organization.
You should be prepared to see failure as an opportunity to correct your course toward a better direction. If you face significant failure, it indicates a lack of elements to control the situation.
Using indispensable tools and methodologies in the field, this chapter aims to make you understand the importance of a company culture that accepts failure. It will enable you to better anticipate risks, embrace them more confidently, and increase your velocity.
Instilling this mindset is a cultural shift that an organization must implement at all hierarchical levels.
“Psychological safety is the shared belief that one will not be punished or humiliated for speaking up with ideas, questions, concerns, or mistakes.” - Amy C. EDMONDSON, Professor of Leadership and Management at Harvard Business School.
An organization’s culture is foundational to its potential. A positive culture promotes team collaboration and communication, essential for the successful implementation of a DevOps initiative. This idea isn’t new and was theorized in 2004 by sociologist Ron WESTRUM in his article “A Typology of Organizational Cultures”192.
By ensuring your employees’ psychological safety, you encourage shared responsibility for successes and failures. Shared outcomes rather than attributing them to specific teams or individuals.
In a work environment that overlooks psychological safety, collaborators:
As mentioned by Kiran VARMA in her course on SRE culture at Google193, research194 identified two primary drivers fueling the human tendency to blame others: hindsight bias and “discomfort discharge.”
Hindsight bias is when an individual overestimates their ability to have foreseen an event. People often struggle to grasp that something only seemed obvious after it happened. In a professional setting, this might lead to blaming a person responsible for a task, claiming they should’ve “seen the obvious thing” coming.
The concept of “discomfort discharge” refers to the neurobiological phenomenon where we blame others to alleviate mental pain. Sociologist Brené BROWN suggests that humans do this involuntarily but blaming hampers our ability to learn from mistakes195.
In organizations uncomfortable with failure, team members might hide information or not report incidents for fear of punishment. Similarly, out of fear of appearing foolish, they might hesitate to ask questions that could identify a problem’s root cause. However, mistakes only become opportunities for improvement if their true causes are identified. This can only happen in a psychologically safe work environment.
A psychologically safe organization believes:
This mindset fosters trust. Organizations should shift from asking “Who did this?” to “What happened?” Focus on methods and procedures rather than on individuals. It’s best to assume employees act in good faith, making decisions based on the most relevant information available. Investigating the source of misinformation is more beneficial for the company than blaming someone.
Innovation requires risk-taking. No product or strategy comes with a 100% guarantee of success. So, if everyone’s afraid of taking risks, nobody will, and your organization will stagnate.
There are numerous other decision-making models196 and project management methods197 available. Don’t hesitate to explore and adopt them.
When discovering the plethora of experimental technologies to implement for operating in a DevOps mode, you might be intimidated by the idea of becoming responsible for this vast, new system.
This chapter aims to juxtapose a traditional responsibility model with the DevOps model. It also offers a tool to guide decision-makers, the DACI. It’s up to you to pick and choose methodologies from each that seem most appropriate for your organization. However, be bold enough and try to avoid reverting to a traditional model, which would only give you the illusion of transformation.
One of the responsibility-sharing models is “RACI”, which stands for Responsible (Executor), Accountable (Owner), Consulted (Consulted), and Informed (Informed). It ensures all stakeholders are aware of their roles and responsibilities in a project.
In the table below, we have five stakeholders for the development of a new website. A responsible, an executor, consultees, and informers are designated for each activity.
| Project Deliverable (or activity) | Project Leader | Archi -tect | Design -er | Front-end Developer | Back-end Developer |
|---|---|---|---|---|---|
| Site plan design | C | R | A | I | I |
| Artistic direction | A | C | R | C | I |
| Mockup design | C | A | R | I | I |
| Code structure (template) | A | I | C | R | C |
An extension of RACI is RACI-VS198, which includes a validator (the person in charge of the final deliverable validation, an authority) and a signer (the person in charge of the official approval of the deliverable, a higher authority).
The RACI model is built on a clear separation of roles and responsibilities. This can be counterproductive in a DevOps initiative, which seeks to foster collaboration among teams. Moreover, RACI doesn’t consider the dynamic and ever-changing nature of project development.
In a DevOps model, everyone can contribute to a project. Everyone is accountable at the same level based on their expertise. A significant change—like launching a new software version—requires the approval of each team (from the design team to marketing, engineering, and security).
Of course, you wouldn’t ask the IT security team for their opinion on changing a button’s color… But the point is, there isn’t just one owner or executor: everyone is responsible and can validate or invalidate a change based on current rules and constraints.
RACI, as used in large organizations, plays a referee role. A specific team is designated for specific tasks. However, DevOps is a collective set of practices that are interconnected. If you aim to evolve multiple organizational teams, RACI can have a discouraging, perverse effect. It might allow Team A to ignore Team B’s issues under the pretense that it’s not their responsibility.
To mitigate this, while still reassuring your managers, RACI’s deliverables can initially be broadened. For instance, instead of referring to “a mechanism that collects application logs,” you might refer to “a set of tools for observability.” Specific sub-objectives can still be defined, but responsibilities should remain broad. If some don’t play along, RACI can force them to do the work, but they might not be the right members for your project.
As a leader of an initiative involving new technologies and practices, your superiors will ask you to take on many of the roles in the table above. Take on this responsibility to reassure your authorities199. There’s no need to fear since you know the methodology you want to implement is collective and iterative.
Most of the time, it’s not advisable to immediately abandon a RACI-like model. It’s a matter of evolving culture and implementing tools. But that’s the goal: a cultural shift in your organization so that authorities overcome their fears.
However, by assuming shared responsibilities without placing blame, you focus on improving the service to achieve the desired end result (e.g., a more stable infrastructure) rather than finding a culprit. With this principle in mind, let’s analyze a common concern.
As you’ve realized, DevOps encourages not blaming stakeholders. It might seem logical to argue that if no one is personally accountable, teams might be less diligent in their daily duties. How can we imagine a production head deleting the entire client database without consequences? Leaders must realize their actions have repercussions. DevOps addresses this challenge in two ways:
That’s why you should start with available resources, but have the boldness to start small in your transformation journey. Your company should gradually implement procedures (in our case, IT system control technologies) based on available human and financial resources. Once these techniques have been tested, iterate on a larger scale.
DACI is not a means to define responsibilities for a project. Instead, it’s a document and method to organize occasionally, aiming to make a group decision when faced with multiple options. It’s typically used to ensure a decision is made by the end of a meeting. Consider it a tool that supports the approach of shared responsibilities in DevOps mode.
A meeting based on the DACI model involves defining four roles:
Next, the goal is to collaboratively list the considered options in a few words. For each, indicate its cost, time required, and other pros or cons.
In the remaining 5 minutes, set a date for when the decision should be made (if not immediately). Based on these preliminary options, if any need further details, assign the task to the person responsible for fleshing them out.
Once the options are consolidated, the approvers make the decision, and tasks are delegated accordingly.
Example of a DACI, listing options considered for making a decision on the issue “How should we finalize our product specifications?”:
| Criteria | Option 1: Discussion Groups / Paid Target Persona200 Discussion Groups | Option 2: Online Reviews / Internal Content Expert Team | Option 3: Do not finalize / Take no action to address the issue at the moment |
|---|---|---|---|
| Strategically reliable / high priority | (+) Targets rooted in strategy = feedback rooted in strategy | (+) 2 new team members match the persona = some feedback rooted in strategy | (-) Risk of significant or costly mistake, (-) Risk of delays or confusion |
| User-centered / high priority | (+) Precise customer feedback | (-) Expert bias | (-) Navigating blindly |
| Cost / medium priority | (-) More expensive short-term, (-) Time-consuming | (+) No additional cost, (+) Relatively quick to implement, (-) Takes team’s time | (+) No additional cost, (+) Quickest option |
| Opportunity to learn more / low priority | (+) Chance to learn more about our targets | (+) Opportunity to learn from feedback of our inter-team experts |
An example of using the DACI model to weigh pros & cons and make a decision (in this case, option 1). Translated from English. Source: atlassian.com
Once your decision is made, it’s time to communicate it so everyone is on the same page. Send the document to those who need to be informed and then archive it.
Once archived, it will help new stakeholders understand why specific decisions were made. By conducting this collective reflection, individual cognitive biases are also avoided.
You receive an alert message from customer support on Slack. They inform you that your file-sharing platform is down.
This marks the beginning of the problem investigation. The most common technique is root cause analysis (RCA), inspired by quality control techniques in manufacturing. It helps understand the factors behind the incident and determine its source. The goal then is to establish procedures to prevent the incident from happening again.
In RCA, your primary goal is to restore the services. This is followed by a solution to permanently resolve the issue. Lastly, preventative action is implemented to prevent future recurrence.
For instance, in the case of a faulty coffee maker:
To make upper management understand the value of this method, present it as an investment in saving time and money201. RCA reduces the risks of expensive software redesign and is time-efficient. Focus your RCA efforts on the incidents that cost your organization the most. Establishing procedures and preserving knowledge on incident resolution also improves team communication. Instead of merely applying patches, the idea is to find a lasting solution.
Here are the 5 steps of Root Cause Analysis:
Identify the problem
Analyze the situation to ensure that it’s indeed an incident and not just a harmless alert. The company should set a threshold to classify an event as an incident, such as an anomaly lasting more than 1 minute. If the event threatens the stability of your resilience indicators, treat it as an incident.
When in doubt, the best practice is to report incidents early and often. It’s better to report an incident, quickly find a fix, and then close it, rather than allowing it to persist and worsen. If a major incident arises, you’ll likely need to handle it as a team (see chapter “Structuring your incident response”). You can distinguish a major incident from a minor one if you answer “yes” to any of these questions:
As soon as the incident starts, begin taking notes on what you observe and the actions you plan to undertake. This will be helpful for your postmortem. Next, classify the problem using the “5W2H” method (5 whats, 2 hows):
| Question | Description |
|---|---|
| Who? | People or customers affected by the issue |
| What? | Description or definition of the issue |
| When? | Date and time the issue was identified |
| Where? | Location of complaints (area, equipment, or affected customers) |
| Why? | Any prior known explanations |
| How? | How the issue arose (root cause) and how it will be addressed (corrective action) |
| How much? | Severity and frequency of the issue |
On mature infrastructures, problem identification is made easier by monitoring systems. They notify about detected anomalies. For example, these anomalies can be detected by tools like Statping, which trigger an alert when a service goes down. But they can also be detected by machine learning mechanisms, revealing unusual trends. The advantage is that alerts are not just triggered when a simple threshold is breached, but when something unusual occurs.
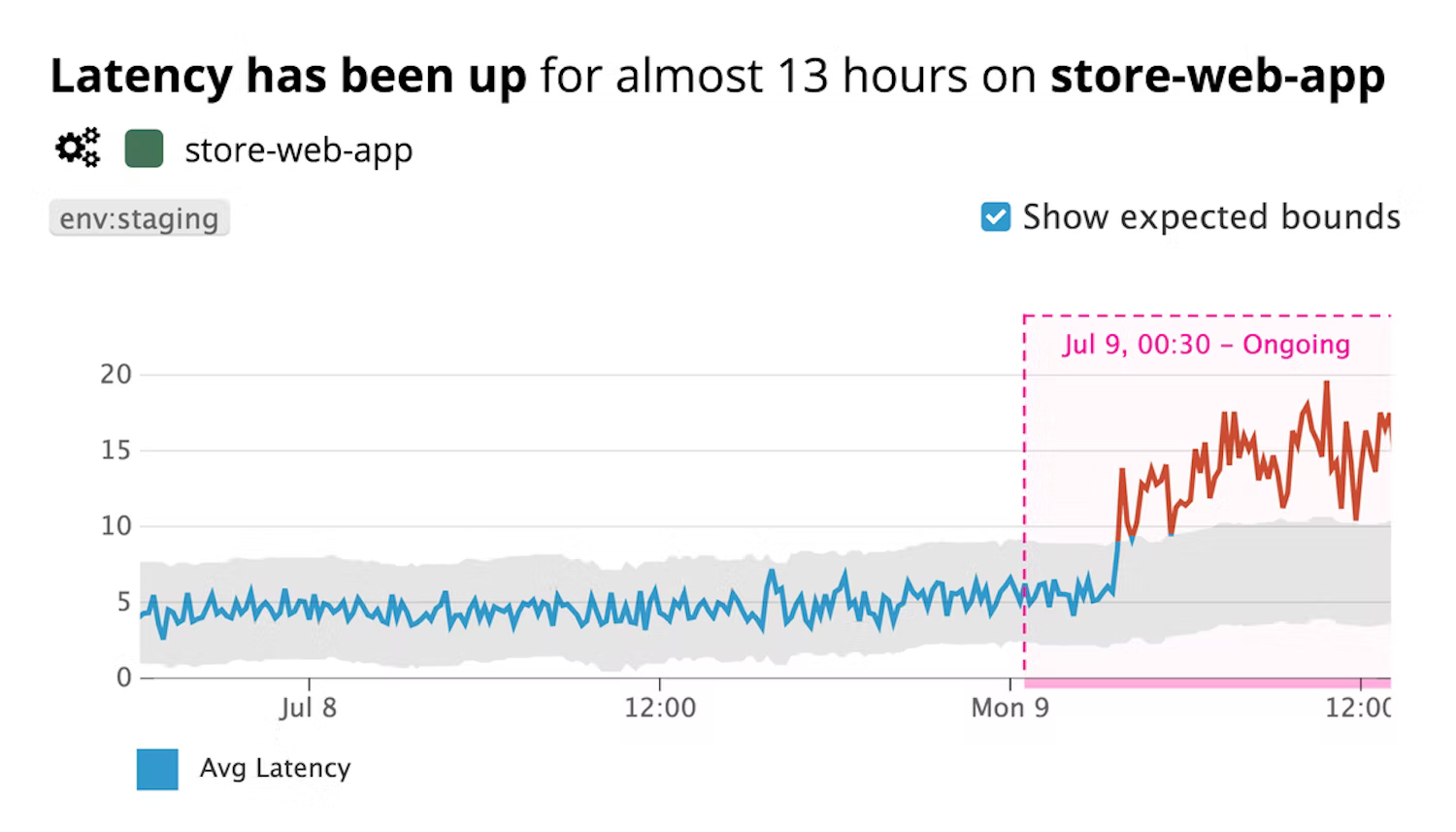
Tools like OpenRCA, OpenStack Vitrage, and Datadog can help identify the root cause of a problem by highlighting anomalies within your infrastructure.
At this stage, you only recognize the symptoms of the problem, not its severity.
Contain and analyze the problem
Always start by resolving the problem. Restore service as soon as possible to prevent further escalation, even if the solution is temporary or not deemed “clean.”
The trust your users place in your service is linked to your responsiveness during incidents. Users don’t expect 100% uptime but do expect clear communication during outages. Transparency is vital.
A service status page is an excellent way to inform your users about an incident’s progress (fig.
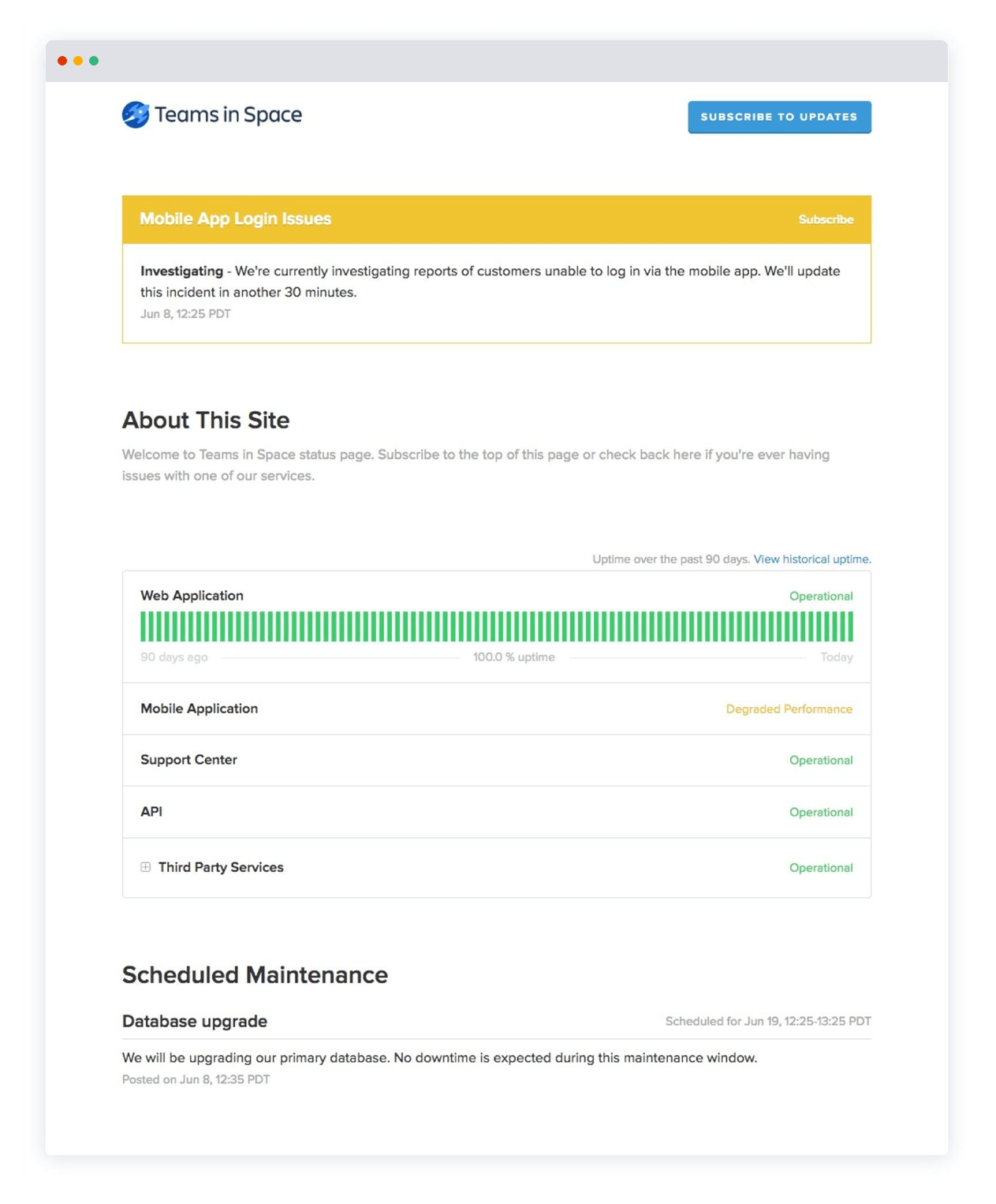
With each update on the incident’s status, communicate:
To analyze the issue in more detail and locate the source of the malfunction, use your observability tools (activity logs, metrics).
The Beats suite from Elastic is an example of a tool that monitors infrastructure. We will explore these technologies further in the chapter “Measure Everything”.
At this stage, you must find an immediate action. For instance, a manufacturer could decide to re-inspect ready-to-ship parts, rework them, or issue a recall. For software, the idea is to find a way to restore service, often by pushing a quick fix (known as a “hotfix”).
Your SRE team must ensure deployed fixes work. They can do this by running pilot tests202 prepared in advance.
Determine the cause of the problem
With the incident’s impact now managed, it’s time to investigate the root cause.
As a team, list likely factors contributing to the problem. Structure your hypotheses using a cause and effect diagram (or Ishikawa diagram, fig.
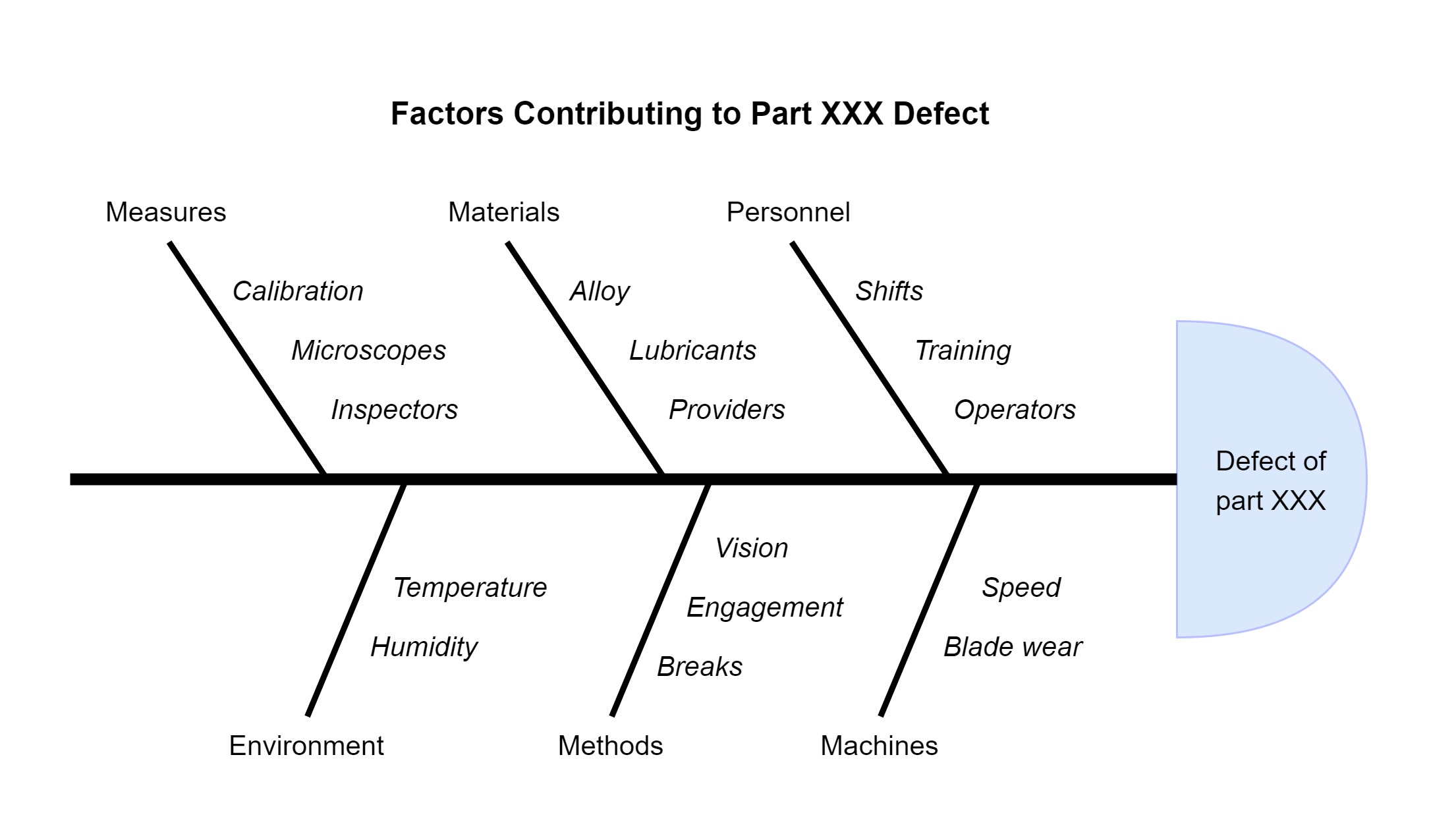
Choose by majority vote the causes that seem most likely to reoccur. According to Pareto’s principle, 80% of effects come from 20% of the problems. You now have a focus for your investigation.
Use the “5 Whys” method. The idea is to identify cascading symptoms until the root cause of a problem is found. “5” is an arbitrary number; it can be less or more, depending on the situation.
Here’s an example for the identified problem “Our software crashes frequently”:
| Question | Answer |
|---|---|
| Why? | Because memory usage increases over time |
| Why? | Because there’s a memory leak in the code |
| Why? | Because developers didn’t properly free memory after allocating it |
| Why? | Because they weren’t aware that their program could have a memory leak |
| Why? | Because there was no continuous integration chain checking for it |
Address the problem in a sustainable manner
After identifying the root cause of the issue, it’s time to design a solution to address it.
Validate that the solution works by performing a proof of concept before deploying it to production.
Define and outline the steps to rectify the problem, assign responsibility, and set a timeline for completion.
Determine how the solution’s effectiveness will be measured, such as through telephone surveys, online polls, automated feedback, manual measurements, etc. Set a timeframe for monitoring the action, then implement the fix.
Validate the fix and ensure the incident doesn’t recur
Using the measures set in step 4, ensure that the actions taken have had the desired effect.
The incident is now resolved and the cause understood. Now is the time to inform your users on the status page: “Root cause analysis complete, incident resolved, incident documented.”
All that remains is to draft your post-mortem, noting what measures you’ve put in place to prevent a recurrence (see chapter “Postmortems”). Use the notes from previous steps to structure this document.
Publish and share this document internally or publicly. This keeps customers informed and satisfied, and recognizes the hard work of the operations teams.
Just as airplane pilots train for emergency scenarios, your SRE teams should practice to save time when an incident occurs (refer to the chapter “Assessing security and training”).
Your incident response procedure should be easily accessible and written for all audiences. It should provide guidance not just for SRE teams but also for non-SREs who might encounter an incident. Regardless of your organization’s size, you need an incident response procedure.
A postmortem is an incident investigation technique. Its purpose is to determine corrective actions to prevent recurrences. Your SRE team should draft this document based on information gathered during the root cause analysis (see chapter “Investigating Incidents”).
In the military and aerospace fields, the AAR (After Action Review) or debrief is systematically practiced following an event to learn from it. The postmortem, on the other hand, is only initiated when an incident or failure has occurred. That is what distinguishes them.
It’s recommended to store these documents in a git project to track changes over time (refer to the chapter “GitOps”). My personal recommendation is to draft them in Markdown format.
Historically, the Latin term “post mortem” means “after death” and refers to investigations carried out by law enforcement to understand how a crime occurred. They analyze evidence, identify the cause of death (e.g., through an autopsy), then attempt to apprehend the perpetrator or amend the law to prevent future occurrences. The concept is similar for IT incidents.
The structure recommended by Google203 serves as a good example. The document consists of two parts: one that describes what happened and another that details the steps to be taken following the incident.
Create a new Markdown document and name it in the following way:
yyyymmdd_postmortem_summary-incident_duration.md20230604_postmortem_file-sharing-outage_00d00h38m.mdFor the first part, set the following headings:
The second part describes what your team might do differently next time. As a conclusion to your postmortem, it lists actions to prevent recurrence of the issues. Focus not only on bug fixes but also include necessary procedure changes to mitigate similar future incidents.
Define a table with four columns and as many rows as desired:
As your team or projects grow, a more formal structure for your postmortems might be needed. The postmortem model proposed by Atlassian is a good example204.
For minor incidents or daily bugs, use a Q&A service like Scoold or question2answer. This can address technical problems (e.g., “How to resolve a dependency conflict”) or more general queries (e.g., Q: “I can’t connect to service X”. A: “Did you try registering at this URL?”).
With such software, your SREs will have a list of problems that are easily solvable in the future. A private alternative to StackOverflow, it also allows your developers to ask questions to other company colleagues confidentially.
As discussed in the chapter “Investigating incidents”, publicly sharing one’s work allows it to be recognized by the community. This practice also enhances retention by enabling collaborators to build their reputation.
Video creator Bastien MARÉCAUX (known by the pseudonym Basti UI) introduced the concept of “teletralive”, a blend of “telework” and “live streaming”. He broadcasts live work sessions on the Twitch platform, with permission from his clients205. This underscores the significance of publicizing one’s work—a trend that might gain traction in the future.
Beyond personal perception, showcasing one’s work to an informed audience motivates the individual behind the published name to deliver quality work206. Initially, it might just involve sharing internally with company colleagues. A mere notification about the postmortem in the company’s messaging platform could suffice.
Transparency is also an excellent way to attract talent. In the industry, companies brave enough to document and publish their incidents are deemed trustworthy. This is because they are not hesitant, given their robust procedures and meticulous work, inspiring confidence and attracting talent.
Many companies like Spotify, LinkedIn, Meta, Airbnb, and Capgemini share articles on their respective blogs. Topics range from postmortems to best internal practices or overcome challenges.
For instance, Cloudflare is renowned for its high-quality postmortems regularly published on its blog207. Newsletters such as SRE Weekly also list public incidents every week.
A public postmortem is typically less detailed than an internal one. The former often summarizes the latter, excluding sensitive parts.
For significant incidents, effective organization is crucial. A productive technique is the 3 Commanders system (3 Commanders or 3Cs). Initially theorized in 1968 by firefighters as the Incident Command System (ICS)208, it was later adapted for IT incidents. Today, it’s employed by Google’s SRE teams209.
When a major incident occurs, the immediate challenges are task coordination, incident resolution, and communication—all simultaneously. Imagine driving while navigating using a map.
Ouch! The server handling employee authentication for the intranet just crashed.
To manage, designate 3 individuals for the following roles:
In smaller teams, the IC often assumes all three roles. However, preparation for delegating these tasks during severe incidents is essential.
Defining and organizing roles should be a part of your incident response procedure. Ensure clarity in your knowledge base so teams know how to act. Regularly train your teams for potential incidents (see chapter “Assessing security and training”). Setting a low alert threshold can help expose teams to your incident response procedures more frequently.
Communication is vital, whether with customers or internal teams. During a significant incident, Datadog emphasized in its postmortem210 the need for early communication about outages to both customers and internal teams. Here are some insights:
For incidents not fully identified and impacting clients differently (e.g., based on location or product used), the rule is to report the “worst symptoms”. Instead of potentially frustrating clients or spending excessive time communicating for each region or product, decide to communicate promptly about the most affected area or product. For instance, if the “EU” region shows more severe symptoms than the “US” data centers, report the EU’s issues, even if the exact scope of the outage is unclear. Clearly state that the “US” might be similarly affected as the “EU”.
During major incidents, many customers might open tickets. Assigned “support” engineers then address these distressed clients. Without clear internal communication for support engineers, both your teams and customers can grow impatient. Ensure a dedicated internal communication channel (e.g., Slack channel, Google Docs) so support engineers can provide consistent responses to clients.
More broadly, the company learned over time that updating clients every 30 minutes was optimal. This frequency allows technical teams to focus on problem resolution without being interrupted too often for updates.
In this chapter, we will explore two techniques to proactively anticipate potential incidents: the premortem and the cause-and-effect analysis.
If multiple approaches are being considered, start with a DACI (refer to the chapter “The DACI Model”). Once a decision has been made, the team should have an intuition about which approach to pursue: this is the moment to test it with a premortem.
The cause-and-effect analysis (FMEA) focuses on technical considerations, taking place after the decision regarding which approach to use has been made.
Before the start of a project, project managers and engineers should gather to list out potential reasons for its failure.
The premortem is also known as the “study of nonconforming cases”. The military strategist Sun TZU already advocated in the year five before Christ for planning as many possible war scenarios as possible (or “nonconforming cases”) before a battle, in his writing The Art of War.211.
The premortem is a project management methodology that involves imagining that the project has failed even before it has started. The result is a document listing the incidents the team needs to prepare for to ensure project success.
For example: “Our team currently manages its infrastructure using traditional methods. We want to establish a plan to work in a DevOps mode.”
Here’s a more technical example: “Our team deploys its software using Docker Compose. They now want to deploy using Kubernetes.”
While the RCA is a “reactive” method employed after an issue has occurred, the failure modes and effects analysis (FMEA) is a “proactive” method to attempt to anticipate failures before they occur. Introduced by the U.S. military in 1949212 and later adopted by the automotive industry, it lists out product or software error states, prioritized by risk. Based on the potential consequences of a risk, design teams prioritize the development of mechanisms to prevent its occurrence.
In FMEA, one can visually represent a cause that might lead to an error situation (fig.
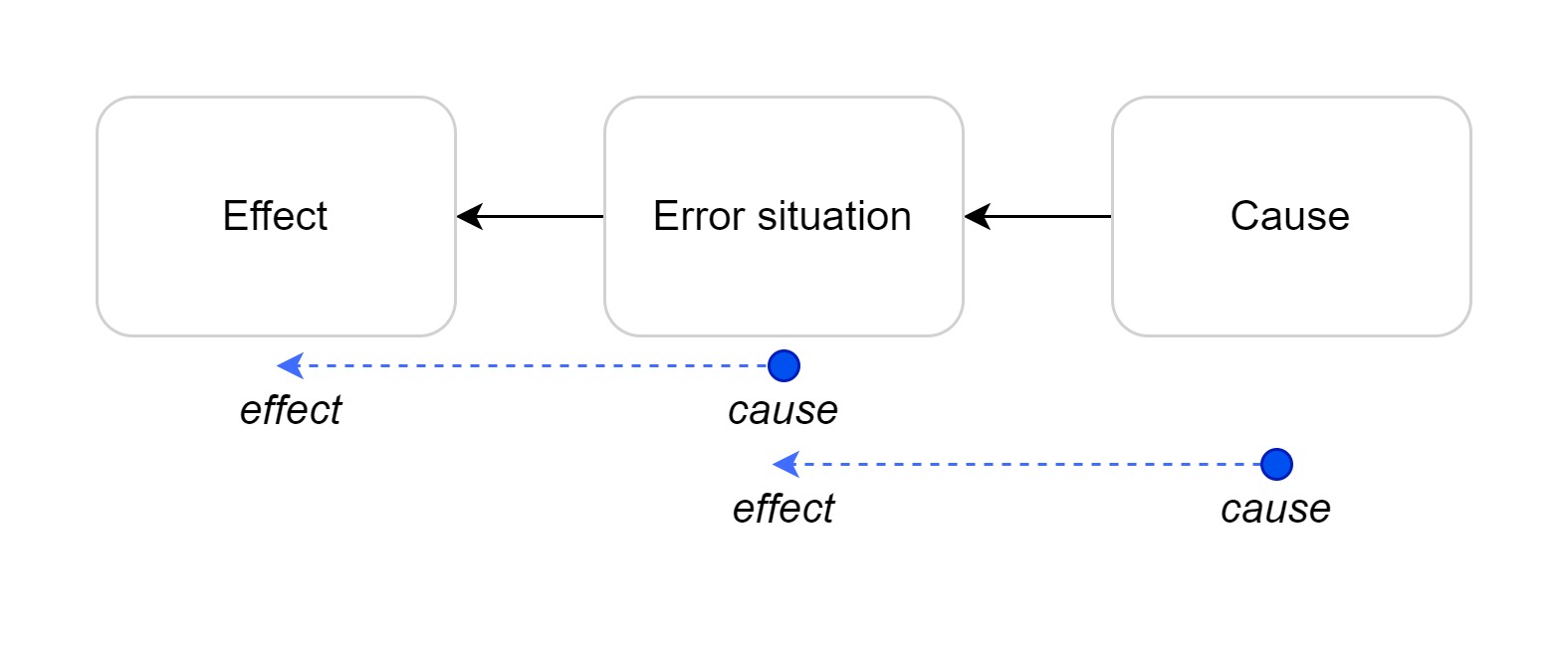
A chain of causes and effects can be established to better visualize the consequences of a problem. For instance, consider the figure

You can do the same with malfunction scenarios of software or infrastructure. Set up a table with 7 columns. For each hypothesized incident, the author should determine:
From this table, prioritize tasks for your teams to work on anticipating the most critical situations.
For infrastructure maintenance, a best practice is to create “incident sheets”. Each includes a breakdown scenario, coupled with potential solutions. Typical breakdowns include running out of disk space, a poorly migrated database, or a failed backup export. Catalog them in your knowledge base (e.g., GitLab, Confluence).
If you are a small organization, start by formalizing your procedures to conduct an RCA and write postmortems. Then, gradually establish FMEAs and try to start your projects with premortems. Periodically, conduct FMEAs.
The decision to invest time in conducting premortems, FMEAs, or postmortems is governed by your priorities in terms of resilience. Research shows that service downtime can be costly for large organizations, averaging $500,000 to $1,000,000 per hour of unavailability213.
DevOps is often portrayed as a disruptive organizational approach, meaning a paradigm shift in technologies and practices. To avoid intimidating the stakeholders of your transformation, instead present DevOps as an evolution of traditional technologies.
For instance, Windows 10 (released in 2015) is merely an evolution of Windows NT 3.1 (released in 1993) and still contains code from the early days of the Windows NT architecture (designed in 1988)214.
Here are some parallels concerning the Cloud:
Traditional VMs also have their place in a Cloud DevOps infrastructure; they can be part of it (see chapter “Abandoning VMs?”).
Along with these technological evolutions come methodologies to manage technical debt, accelerate deployments, and maintain a high level of resilience: a software forge, gitops, continuous integration, continuous deployment, postmortems… That’s DevOps.
By implementing the methodologies covered in this book and using standardized administration technologies (e.g., Kubernetes), you will ultimately reduce administrative costs.
As discussed in the chapter “Staying close to business needs”, it’s common to not meet the initially expressed need using traditional methods. Setting the requirement at a fixed point is not a reliable way to deliver the expected product. Needs continually evolve, and clients often can’t articulate exactly what they need.
Agile methodology aims to reduce this risk by offering several short delivery cycles (sprints). After each cycle, the client provides feedback. This loop continues until the project suits the client or the contract ends. DevOps provides the tools for a company to streamline these interactions. In the most efficient companies, sprints are merely a contractual detail to discuss progress: the software is already in production and ready to use.
On the contrary, this methodology avoids being trapped by clients too specific in their requests. Some are convinced of how software should be designed to best meet their needs. However, their suggestion might not be the most suitable option. Throughout your deliveries, the client will always have feedback or details they forgot to communicate. These details—big or small—accumulate over time and can lead to excessive delays.
If software is meant to deeply change its recipient’s habits, delivering it early is necessary for them to gradually adapt to the imposed changes. They can, for instance, modify their internal procedures, hire the right profiles, and prepare their communication strategy. This will prevent frustrations and ensure a deliverable that closely meets business needs.
Avoiding this approach, especially with a very demanding client, can in extreme cases lead to projects that drag on for years. Or even worse, to abandoned projects. This will inevitably cause mutual frustrations among the team leader, the development team, and the client.
Human error is the primary cause of mistakes. That’s why automation is a fundamental component of a DevOps mode organization. Continuous integration and deployment chains are particularly effective in streamlining the software delivery cycle.
If you currently feel friction in your production cycle, you likely need to invest time in automation. In mature companies, teams dedicated to developing automation tools for development teams exist. Their mission is to listen to developers to enhance their development experience. For example, they might develop internal tools that analyze added code to suggest readability or security improvements. At Google, an internal platform handles this kind of suggestion: if the code doesn’t conform, a click is enough to reformat it. If a library is considered vulnerable, an alternative is suggested.
These tools generally speed up the development process and expedite code reviews to get the software into production as quickly as possible. These methods are especially effective when you regularly onboard new staff unfamiliar with your development practices. Inexperienced newcomers, without explicit and restrictive rules (like CI/CD pipelines), can quickly impact the quality of your codebase. A slight oversight, and a bug can quickly emerge.
Deployment techniques like blue/green also reduce the risk of software regressions (see chapter “Continuous deployment”).
Companies with a strong SRE/DevOps culture encourage innovations put forward by their team members. Thanks to techniques discussed in the previous chapter (CI, CD, blue/green, premortems, FMEA), it’s fortunately possible to control the risks brought by these innovations.
To keep your employees motivated to achieve great things, it’s crucial to avoid limiting their creativity or ideas. That’s why design thinking and the creation of prototypes are key techniques for an efficient organization.
Design thinking is an innovation technique that merges creativity and method to try to solve complex problems. It comprises 5 phases:
In summary, you need to put yourself in the user’s shoes, and techniques like continuous deployment help streamline this process. When faced with reality, innovation isn’t stifled by the organization.
If it fails, the organization learns more about its customer and environment. If it succeeds, it’s a win for everyone: the innovation team, the organization, and the customer.
This prototype-driven culture is vital because a company that doesn’t prototype launches fewer ideas, thus experiences fewer successes and takes longer to fail. Conversely, a company accustomed to testing its prototypes will fail faster and consequently achieve more successes.
You don’t have to build the software from scratch before presenting it to the customer. You can create a mockup on Figma or Penpot, use a low-code/no-code solution215, or find someone to play the customer role.
A good culture is nurtured by knowledge of cutting-edge techniques. The technical skills of your teams are the foundation of your organization and bolster your reputation as a resilient structure.
Continuous training is a straightforward way to prevent your organization from losing millions each year. Indeed, if your staff stays updated with the latest technologies, they’re less likely to be deceived by third parties. These third parties often promise “the ideal solution” through impressive and ambitious presentations, which, more often than not, hide an underdeveloped or wholly deficient service. By staying updated, your team will make better decisions for your budget and the organization’s future.
However, keeping pace isn’t easy, especially considering how fast technology evolves. All the more reason to implement good training practices right from your employees’ onset.
For instance, at Google, interns start with a full week dedicated to training. They get briefed on security best practices, administrative tasks they need to complete, and are introduced to internal technical tools. Later, like all employees, they must periodically complete awareness modules on a dedicated platform with written or video courses.
The United States Air Force (USAF) has, since 2019, invested heavily in self-learning solutions. In a podcast216, its former Chief Software Officer, Nicolas CHAILLAN, explains how he deployed this system for over 100,000 developers. A web platform was launched with educational content specially selected or created by his teams. He added that an hour a day was allotted to employees to “catch up and stay updated on the latest technologies.”
“It (training) is an investment for the company and for themselves. People who don’t want to learn by themselves don’t have much chance of succeeding in IT. Anyway, the industry moves so fast they don’t have a choice.” - Nicolas CHAILLAN
Following the USAF’s footsteps, one successful approach I witnessed in one of my previous experiences was: we managed to get one day of remote work per week. It wasn’t easy to get approval from our managers, but they finally granted it after understanding its benefits. This day was dedicated to our continuous training as AI, data, and DevOps experts. But we were equipped, and our progress was measurable: almost unlimited access to a Cloud service and an e-learning platform. The latter allowed our management to see statistics on our training time and completed courses. The cost of these services was negligible compared to the knowledge they imparted.
If you already have technical teams, allow them to experiment and practice. From what I’ve observed, the most effective (hence profitable) approach for the organization is: invest time in training your staff. For instance, provide them access to machines or cloud hosting services to experiment with the latest innovations from the private sector or open-source projects. Your teams will be thrilled to have access to these services, while the management will be assured of receiving the best advice from updated employees.
It might be tempting to think that training staff in innovative technology - making them attractive to competitors - might encourage them to switch companies. Firstly, leaving just because of acquiring a new skill indicates limited prospects within their current company, reflecting already demotivated, thus less productive, personnel. Secondly, research suggests that staff training in their free time tend to look for other jobs more often217. The opposite is true when the company provides the training.
In any case, present your transformation as a career growth opportunity. And be honest with those who need to upscale: yes, it will require personal effort and time. But developing these new skills is worth it.
In increasingly complex information systems, it is essential to automate recurring tasks. Humans are the primary source of errors within an information system218. Any seasoned engineer will confirm this. That’s why Google teams try to minimize operator interactions when managing their systems219.
« If a human operator needs to touch your system during normal operations, you have a bug. The definition of normal changes as your systems grow. » - Carla GEISSER, SRE at Google
If you want to make your IT system an integral tool within your company, you must first automate repetitive and time-consuming actions: manual tasks (or toil).
This notion of toil describes all manual, repetitive, and automatable tasks. Essentially, these are all the intellectually uninteresting tasks that a robot would be far better suited to do than your brilliant engineers.
Google’s SRE teams aim to keep operational work (manual admin tasks) below 50% of the time for each SRE. At least 50% of each SRE’s time should be devoted to engineering projects that will reduce the future amount of manual tasks or add functionalities to the infrastructure.
This process can begin with small things within your existing infrastructure. In this chapter, we’ll categorize them based on organizational maturity levels. It’s up to you to determine which level of automation is most suitable for your organization, based on the technological acculturation of your engineering teams and the time you want to allocate to implementing these technologies.
Keep this in mind: automation is the action that reduces technical debt. Make sure you give your teams enough time to work on it.
This popular term is easy to understand: it encompasses practices and technologies that make your infrastructure configuration explicit, in the form of computer code.
Here are some configuration examples:
Of course, when I mention “all your machines”, IaC scripts allow you to specify which machines exactly, so changes are applied only to specific groups of machines.
This practice offers several benefits:
Common technologies for these tasks include: Ansible, Terraform, Puppet, and SaltStack.
Each has its pros, cons, and community. Some complement each other. The key is to adopt a standardized format (not necessarily using only one technology) so your SRE teams can navigate it. A newcomer will greatly benefit from these practices, and your most seasoned engineers can incrementally improve these algorithms.
You can start by automating your infrastructures with basic scripts (bash, Powershell) and then move on to more advanced technologies like Ansible that will standardize your configurations.
Refer to the GitHub project “ToDevOps”220 to see this technology in action.
For supervising and automating these admin tasks, advanced tools like Ansible AWX, Ansible Tower (fig.

Remember that maintaining infrastructure is complex, so keep it simple! Don’t rush to adopt the latest technology just because it’s “sexy”: the more technologies and abstraction layers you add, the larger and more experienced your team needs to be to maintain and fix it (see chapter “Too big, too soon”).
Test-driven development (or TDD for short) is a software development practice that dates back to the early 2000s. The objective is to control software erosion222, which means preventing regressions and managing technical debt over time. Put simply: it’s about avoiding bugs as contributions accumulate.
The idea is to write tests before developing the actual functionality. The TDD development cycle is as follows223:
This approach is common in tech companies, especially within giants like GAFA (Google, Apple, Facebook, Amazon). They rely on it to manage their technical debt, despite having thousands of developers contributing in parallel to their software daily. Most of the time, software is developed with few or no tests. It can be challenging to justify to non-technical superiors the time spent on test development instead of focusing on new features. While working with TDD might impact productivity, it significantly enhances code quality224.
For legacy software, it’s advisable to at least adopt the TLD (test-last development) approach, which means developing tests after the functionality has been created. Then, progressively transition to TDD to improve code quality and reduce complexity225. For new projects, prioritize TDD.
In all scenarios, the goal is to test your code to prevent unpleasant surprises in production. According to Atlassian226, it’s recommended to have 80% of your code covered by tests (referred to as code coverage).
TDD is recommended in certain scenarios but not all. For instance, if you operate in a regulated industry—like banking or healthcare—it’s imperative to test your code. Software malfunctions can impact your organization’s legal liability. If your software is designed for long-term use and maintenance—as in defense—TDD is advised. However, if you’re a start-up in the proof-of-concept phase, software malfunction consequences might be less severe, allowing you to prioritize productivity. As your organization grows and the number of contributors increases, testing becomes essential. For a new contributor, a test can serve as an example of how a function operates, aiding code understanding.
In essence, it’s about striking a balance between productivity, functionality assurance, and technical debt control.
This chapter serves as an introduction to the importance of testing your code. Many complementary approaches and best practices concern software engineering more generally (see YAGNI, KISS, DRY) rather than specifically DevOps. For instance, TDD can be supplemented with BDD (behavior-driven development) or ATTD (acceptance test-driven development)227 if your organization’s maturity and team size allow.
All these tests can be automatically verified before any production release. Let’s explore what this entails and how to implement it in the next chapter.
Continuous Integration (CI) is a development practice within the software factory. The idea is as follows: with every code change, automated scripts are triggered to check the conformity of the contribution (fig.
For instance, your security teams may not have the time to validate the conformity of every contribution. They can then delegate part of these checks to scripts that will automatically and consistently ensure the codebase meets your security standards. The benefits are threefold:
Thus, in a DevOps approach, security managers are no longer individuals setting rules on paper but engineers “coding” security rules in the form of automated scripts, within the software forge (fig.

Here are some examples of algorithms that can be executed to automatically check rules or take actions upon a triggering event:
All these tasks contribute to reducing the technical debt of your codebase and facilitate the deployment of your projects, ensuring the effectiveness of the standards defined by your DevOps teams.
It’s common to hear about a so-called continuous integration “pipeline”, which accompanies other terms in the CI/CD tech universe. Let’s define the most common ones:
As mentioned earlier, the advantage of a continuous integration pipeline is also to test the pushed code across multiple environments automatically: your development and pre-production environments before deploying to production. However, these multi-environment pipelines introduce additional complexity, which requires a larger technical team to manage.
Within a software factory, technologies such as GitLab Runners, GitHub Actions, or services like Circle CI are used to execute continuous integration tasks.
Continuous deployment (CD) is a DevOps practice that allows the triggering of administrative actions or the deployment and updating of software in production. The triggering is not necessarily automated, but the applied actions are coded. This means they are predictable, traceable, and replicable. This reduces the time to provide a new feature to its users, minimizing manual intervention and the risk of errors by administrators.
This practice aligns with the principle of “continuous delivery”, which encompasses steps prior to deployment. For instance, publishing the binaries or images of the software’s latest version, or creating the latest release of the project in the software factory.
Most of the time, continuous deployment pipelines are technically similar to continuous integration pipelines. For example, they replay tasks from continuous integration pipelines before deploying the software. However, they might require more specific parameters, such as environment variables or secrets (e.g., Hashicorp Vault, Akeyless, Keywhiz, Conjur). Indeed, deployed software often relies on environment variables to run correctly on a target infrastructure.
It is common to encounter different qualification/pre-production (staging) and production environments. These validate the proper functioning of software before its production release. Continuous deployment pipelines automate all or part of this process, optionally adding smoke tests or functional tests (see chapter “Test-driven development”).
Initially, the goal is to at least automate the update of your software in production. You can do this similarly to continuous integration pipelines, using GitLab Runners or GitHub Actions.
More advanced practices exist for seasoned users. As discussed in the “GitOps” chapter, our git repository is the “single source of truth” for software. Therefore, infrastructure should ideally rely on it to determine the expected state of software in production. For instance, ArgoCD continually checks for changes in a git repository on a specific branch (often main or master). When ArgoCD detects a change, it attempts to deploy the very latest version of the monitored software.
Tools like ArgoCD (fig.
Built on the same mechanics, it’s possible to deploy multiple instances of software simultaneously. For instance, during a code review in a merge request, you can configure ArgoCD to temporarily and independently deploy this “under evaluation” version of the software. This technique allows engineers to quickly test software, rather than deploying it themselves. The URLs often look like this: wxyz.staging.myapp.com.
Using these same tools, you can adopt and automate a blue/green deployment strategy. This technique gradually shifts users to a new software version, ensuring it functions properly. The idea is to instantiate the new software version (green) alongside the current one (blue). The system then directs a limited proportion of users to the new software (e.g., 10%). This proportion is gradually increased over a set period, while measuring the error rate for each request. If the rate is the same or lower than the previous deployment, the software is rolled out to all users. Otherwise, deployment is canceled, and the old version remains in production.
Even more advanced tools exist to address large-scale deployment challenges. We’ll explore Palantir’s Apollo as an example in the chapter “Deploying simultaneously in different environments”.
Moreover, continuous deployment pipelines are not limited to software deployment or administrative task launches. They can be the starting point for monitoring your software. For instance, a continuous deployment pipeline can set up a Prometheus / Grafana instance and start sending its activity logs. Deploying your software doesn’t mark the end of your infrastructure’s resilience cycle: now you need to monitor it. We’ll delve into these techniques in the chapter “Measure Everything”.
In the previous chapter - “Leveraging automation” - we saw how automation greatly saves time in managing our infrastructure and enhances its security and resilience.
In this chapter, we’ll discuss a significant dimension of automation: observability. It’s through measurements that systems can be massively automated, and better decisions can be made organization-wide. Measuring everything achieves three objectives:
Trusting decisions based on its own data marks the culmination of a successful DevOps transformation. The industry calls this “data-driven decision making.”
Activity logs, metrics, and traces are regarded as the three pillars of observability. These three types of data can be generated by software to identify and address issues that might arise once deployed.
Observability is a vast topic in the realm of system reliability230. In this chapter, we will only touch upon the essentials.
The field of observability can be summarized as the set of tools and practices that allow engineers to detect, diagnose, and resolve system issues (bugs, latencies, availability) as swiftly as possible. Beyond the need for resilience, the collection of some of this data is sometimes legally required231.
Let’s delve deeper into what each of these data types can tell us:
Let’s focus on traces to better grasp their implications. Consider an application (a client) sending a request to a REST API (a server). A trace consists of spans and metrics, associated with a unique identifier. This ID differentiates the path of our request as it moves through all the services it touches. Figure
To better visualize the request’s timing, the logs of a trace are often displayed in a diagram. Each span is represented by a rectangle including a name (on the left) and a duration (within the rectangle), as depicted in figure
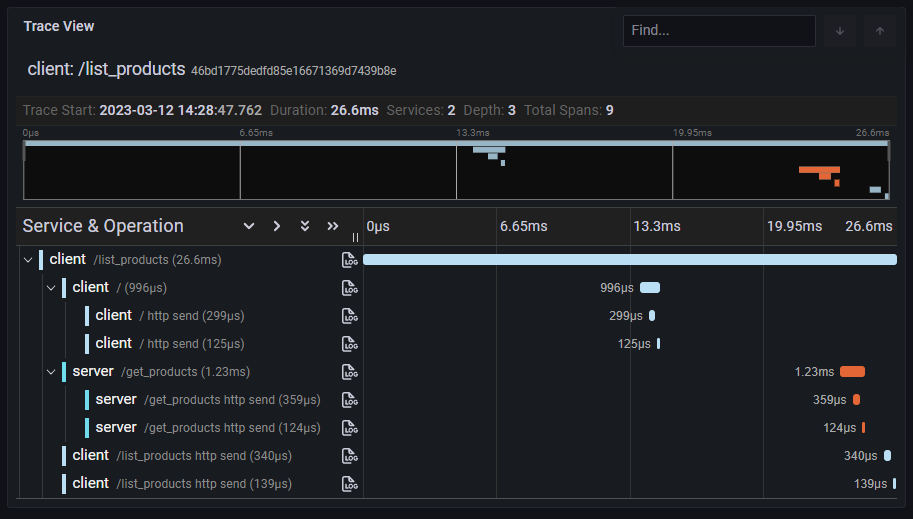
Traces are independently relayed by libraries like OpenTelemetry’s SDK. These are then sent to a trace collector such as Jaeger, Tempo, or Zipkin for validation, cleansing, and/or enrichment. They are subsequently stored in centralized log servers like Prometheus or Elasticsearch. The trace identifier allows us to retrieve the chronology of the operations it underwent.
The biggest challenge of tracing is its integration within an existing infrastructure. To fully utilize traces, every component the request goes through must emit a log and propagate the tracing info. Tracing via a service mesh might be a quick way to avail tracing features without altering the software code232. We’ll explore what a service mesh is and how this technology works in the chapter “Service Mesh”.
Within vast infrastructures, logs and traces might be too extensive for timely ingestion by their log server. Data can then be lost. To avert this, it’s common to use services that stagger the indexing. A server like Kafka can be positioned in front of the log server to gradually absorb logs. Then, a tool like the Jaeger Ingester steadily indexes them. For rsyslog logs, protocols like RELP233 might be necessary to ensure proper storage.
Whether using Logstash or Loki for logs, or Jaeger or Tempo for traces, normalizing your data is crucial for proper storage and processing. To address this challenge, the OpenTelemetry library defines semantic conventions234. It’s commonly used.
By implementing observability mechanisms, you’ll be better equipped to answer questions like “what caused this bug to happen?”. Your engineers can rely on comprehensive data to fix bugs faster. This data will enable us to construct our resilience indicators, leading to more informed decisions.
At first glance, it’s not clear where to draw the line between resilience and innovation. The idea is to measure the state of services to determine when it’s appropriate to innovate.
Measurement is one step, but it’s crucial to measure the right things, at the right level. In a distributed infrastructure, one of the servers can fail without necessarily affecting the availability of software for your customers. Measuring a server’s availability might be interesting for your technicians, but it may not be the right metric to determine the impact of a malfunction on the user. This is something your organization needs to define:
For the second question, you can’t answer “100%”. If you put all your efforts into keeping the service available 100% of the time, you’ll slow down the release of new features. And it’s these features that propel your project forward. That’s where the concept of an “error budget” comes in.
The error budget is the amount of time within a given period that your company allows for your teams, during which your services can be unavailable. As long as your service availability exceeds the allowed downtime, you can take the opportunity to deploy a significant new service, highly interactive with others, or even update a critical system. But this budget is crucial for addressing hardware malfunctions requiring replacement or for intervening in a system during a planned outage.
For instance, if your error budget is 54 minutes per week, and you haven’t exceeded 10 minutes in the past three weeks, allow yourself to take more risks. If it’s the opposite, work on making your infrastructure more resilient.
In short, the error budget is an agreement between management and the technical teams, helping to prioritize innovative efforts versus work to enhance infrastructure resilience.
It enables engineering teams to reassess goals that might be too ambitious concerning the acceptable risk. This way, they can set realistic goals. The error budget allows teams to share responsibility for a service’s resilience: infrastructure failures impact developers’ error budget. Conversely, software failures affect the SRE teams’ error budget.
Be mindful of your error budget consumption peaks: if an engineer spends ten hours instead of one to fix an incident, it’s advisable to open a ticket with someone more experienced. This will prevent consuming the entire error budget.
To answer the first question, let’s look at the possible indicators to monitor in the next chapter.
Monitoring distributed systems presents a real dilemma. SRE teams need to monitor them effortlessly - allowing quick interventions - even though their architecture is often complex. Indeed, various technologies make up these systems. The 4 key signals offer a unified method of characterizing the most vital phenomena to watch.
Let’s explore the four metrics that will allow us to create our resilience indicators:
Within a Cloud infrastructure, a service mesh automates the collection of these measurements. We’ll explore this technology in the “Service mesh” chapter. We’ll also discuss tools available to gather and visualize these metrics. But before that, let’s see how to create our resilience indicators in the next chapter.
The value of your error budget stems from your Service Level Objectives (SLO).
An SLO defines a target resilience level for a system. It is represented as a ratio of “good” events to be honored, out of all monitored events, over a specific time period. For instance, your SRE team may set the following objective: “99% of pages should load in under 200ms over 28 days.”
The “right” objective of an SLO is determined by the threshold of tolerance your customer can bear against an annoying issue. For example, quantify what it means for them to experience a “slow” website (e.g., through an SEO study235). If your clients typically leave your pages after waiting more than 200ms, set your SLO to “99.9% of responses should be returned in under 200ms, over 1 month.”
A good SLO should always be close to 100% without ever reaching it; we discussed the reasons for this in the chapter “Knowing When to Innovate and When to Stop.” As for how often you should achieve this target (99.9% over 1 month), there’s no initial rule to define it. You can base it on the average of your past measurements or experiment. This value should match the workload your team can handle.
SLOs are built upon one or more “Service Level Indicators” (Service Level Indicator or SLI). The SLI is the current rate of good events measured, from all considered events, over a given period. Built on one or more measurements, it measures one aspect of a system’s resilience. It characterizes a phenomenon that can negatively impact your user: response time to a query, the number of up-to-date returned data, or even read and write latency for data storage.
Here are some examples to clearly differentiate which SLI an SLO is based on, and which measurement(s) an SLI relies upon:
An SLI can be composed of one or more measurements. However, avoid creating overly complex SLIs or SLOs, as they might represent vague or misleading phenomena.
An SLO sets a service quality to maintain, which means a certain value for an SLI. An SLO takes a format like: “SLI X should be maintained Y% of the time over Z days/months/years.” Here’s a table correlating resilience rate and maximum allowable downtime (the “Z days/months/years” part of the previous example):
| Resilience Rate | Per year | Per quarter | Per month (28 days) |
|---|---|---|---|
| 90% | 36d 12h | 9d | 2d 19h 12m |
| 95% | 18d 6h | 4d 12h | 1d 9h 36m |
| 99% | 3d 15h 36m | 21h 36m | 6h 43m 12s |
| 99.5% | 1d 19h 48m | 10h 48m | 3h 21m 36s |
| 99.9% | 9h 45m 36s | 2h 9m 36s | 40m 19s |
| 99.99% | 52m 33.6s | 12m 57.6s | 4m 1.9s |
| 99.999% | 5m 15.4s | 1m 17.8s | 24.2s |
If SLOs should primarily represent your users’ pain points, you can also establish them for your internal teams. For instance, your infrastructure could ensure each server responds “99% of the time in under 500ms to ICMP requests over 1 week.” In this case, determine your SLOs based on your historical measurements (see fig.

SLOs should be defined in collaboration with decision-makers. Their involvement in this definition is essential for them to understand how their decisions (e.g., prioritizing tasks, workload demands) impact the resilience of the infrastructure. If a decision-maker wants engineers to frequently and quickly roll out new features, SLOs help understand when the imposed pace is too demanding. Conversely, consistently exceeding SLOs suggests that your company can move faster without compromising service quality. The participation of decision-makers is all the more critical as they sometimes stake the company’s reputation on the line. It’s the SLA that is the root cause of this.
The Service Level Agreement (SLA) is a contract between your organization and a client. If your service quality falls below what your SLAs dictate, your organization faces penalties. An SLA is built on one or more SLOs, setting intentionally lower resilience rates for safety. Here are some examples:
SLAs are not mandated by law. However, they can be part of your service contract to clarify your commitments and avoid disputes. Indeed, it’s always preferable to list clear terms both you and your client have agreed to. SLAs also serve as a competitive edge: your company commits to a certain quality of service, whereas your competitors might not. Implementing an SLA in your governance approach holds stakeholders (developers, SRE, decision-makers) accountable and shares expectations. The company now pivots based on the metrics it gathers and interprets as SLOs. This is referred to as being data-driven.
Within an institution, you can use SLO/SLA as a means to gain credibility among your superiors or specific teams. An SLA might justify hiring necessary personnel to maintain a certain service level. Or it could warrant a budget increase to enhance the team’s operations. Conversely, superiors might demand a certain service quality level from your teams, reflecting in the annual objectives of staff members. For pilot projects, establishing SLOs is sufficient. Setting reliable SLOs is a challenge in itself. Maintaining those objectives is another.
Your alerting mechanisms must continuously monitor your SLIs to ensure they don’t exceed your SLOs. And most importantly, that they don’t surpass your SLAs! But how do you raise an alert before your SLOs/SLAs are breached?
Take this SLO as an example: 99% of pages must load in under 200ms over 28 days.
The simplest method is to calculate the average page load time over a short period. For instance, the average load time over 5 minutes. When set to this approach, your alerting mechanism triggers if, over the past 5 minutes, the average load time exceeds 200ms.
However, basing alerts on averages or medians is not ideal. This approach might miss widespread failures. Google recommends another method237 using percentiles. This distribution method highlights trends among the top X% of gathered measurements.
Imagine your infrastructure serving millions of users, handling billions of requests. A faulty page, affecting only a few hundred users on your site, might go unnoticed if you rely on averages or medians. But with percentile aggregation, you can spot these anomalies more clearly (fig.
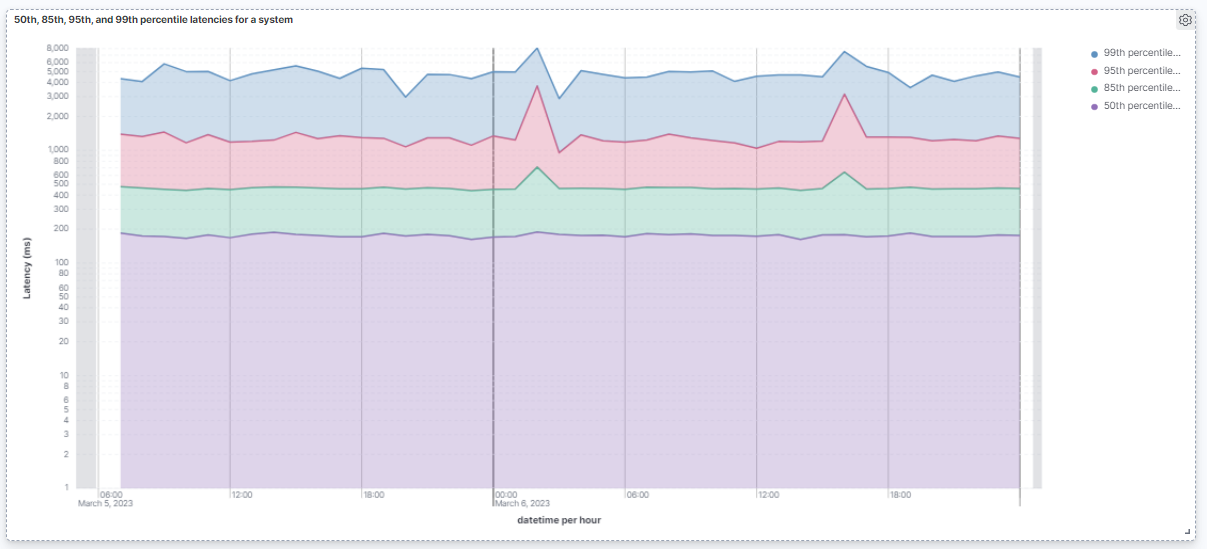
With this depiction, we can deduce that, on average, request latency is at or below 200ms (the 50th percentile, purple section, represents the median). More intriguingly, it allows us to understand that 5% of requests (starting from the 95th percentile, red section) are 2.5 times slower (~500ms) than average. Your SRE team can now investigate why latency is high for these requests.
Now, let’s focus on another phenomenon: on March 6th, shortly after midnight, the top 1% of the slowest requests (99th percentile, blue section) spike to 8000ms latency compared to the usual 5000ms. Something is amiss: your alert system can detect this anomaly more easily, and your SRE team can better isolate and investigate the affected requests. When observing just the median (50th percentile), these trend changes appear smoothed out, almost imperceptible.
Given these insights, we can enhance one of the indicators from the previous chapter:
To develop your intuition regarding these indicators, start with classic SLIs and SLOs. Once your infrastructure matures – especially in user count – you can shift to advanced SLIs and SLOs.
MTTx refers to metrics that qualify the average time it takes for an event to occur or conclude. The “x” in the acronym MTTx represents the multiplicity of these types of metrics. For instance, MTTR (mean time to recovery or average time to restore) is used to track how long a team takes to restore a failing system.
Monitoring these metrics over time allows you to gauge the effectiveness of your resilience efforts. It also helps in assessing the efficiency of your teams in responding to incidents. If the metrics deteriorate, you will need to examine the reasons and possibly reshuffle your priorities so as not to compromise your SLOs. The advantage is that you will know what to focus on.
There are numerous MTTx in literature, each with their particularities and nuances (fig.
| Metric | Full Name | Explanation |
|---|---|---|
| MTTD | mean time to detect | The average time between the onset of an incident and when your systems trigger the alert. Detecting an incident may take a few seconds when a significant issue arises. But it might take several weeks if it affects only a solitary user who does not report the problem… until they can’t manage it anymore. |
| MTTA | mean time to acknowledge | The average time between an alert trigger and assigning personnel to address the incident. |
| MTTI | mean time to investigation | Once the incident is acknowledged, the average time required for the designated person to genuinely understand the problem and how to fix it. A high MTTI suggests that your infrastructure or application is too complex, or your observability mechanisms are lacking. It might also indicate that your engineers are swamped, making it difficult for them to address an incident promptly. |
| MTTR | mean time to recovery or average recovery time | The average time between the alert and the problem resolution. |
| MTTP | mean time to production | The average time for the service affected by an incident to be operational and accessible to users in production. Unlike MTTR, which measures the repair time of a service, MTTP measures the service restoration time after its repair. For instance, during a breakdown, your website might display a “We are under maintenance” message even if you’ve just fixed the failing service. |
| MTBF | mean time before failure | The average time between the last detected failure and the current one. This metric helps predict a service’s availability. |
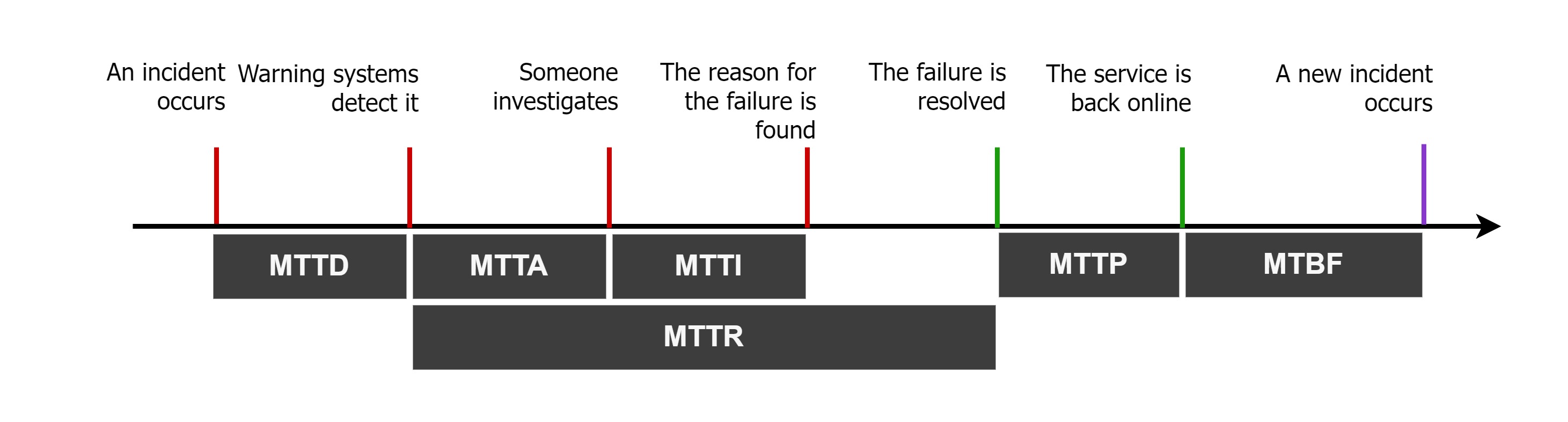
You can begin tracking your MTTx using collaborative spreadsheets (e.g., Baserow, NocoDB, Google Sheets) and later transition to more integrated tools like Jira Service Management or Odoo. The idea is to be able to compute and visualize the trend of your MTTx over time.
If you choose a spreadsheet, you can use the following structure:
| Metric | Start Date | End Date | Incident |
|---|---|---|---|
| TTD | 04/07/24 16h45 UTC | 04/07/24 16h50 UTC | xyz.com/C4D5E6 |
| TTA | 04/07/24 16h50 UTC | 04/07/24 17h00 UTC | xyz.com/C4D5E6 |
| TTI | 04/07/24 17h00 UTC | 04/07/24 17h20 UTC | xyz.com/C4D5E6 |
| TTR | 04/07/24 17h00 UTC | 04/07/24 18h30 UTC | xyz.com/C4D5E6 |
| TTD | 02/06/24 13h30 UTC | 02/06/24 13h34 UTC | xyz.com/A1B2C3 |
| … | … | … | … |
Calculate your MTTx by averaging the differences between start and end dates for each incident. Sample over a calendar month period.
As you can see, most of the metrics can be derived from your postmortem. They are intrinsically linked to it and complement it. Ensure to keep your MTTx updated to quantify your resilience level and pinpoint critical areas affecting it.
Despite its very tangible and practical application, the service mesh or “service grid of services” can seem complex at first glance.
Let’s approach it through some challenges that illustrate its significance:
Thanks to the standardized deployment mechanisms offered by container orchestration systems (e.g., Kubernetes), a service mesh can address these challenges by “plugging into” your orchestration system. It can enhance the security, stability, and observability of your infrastructure by:
As these metrics are standardized, most service meshes allow for their use in setting up automatic rules based on the network activity of the infrastructure (fig.
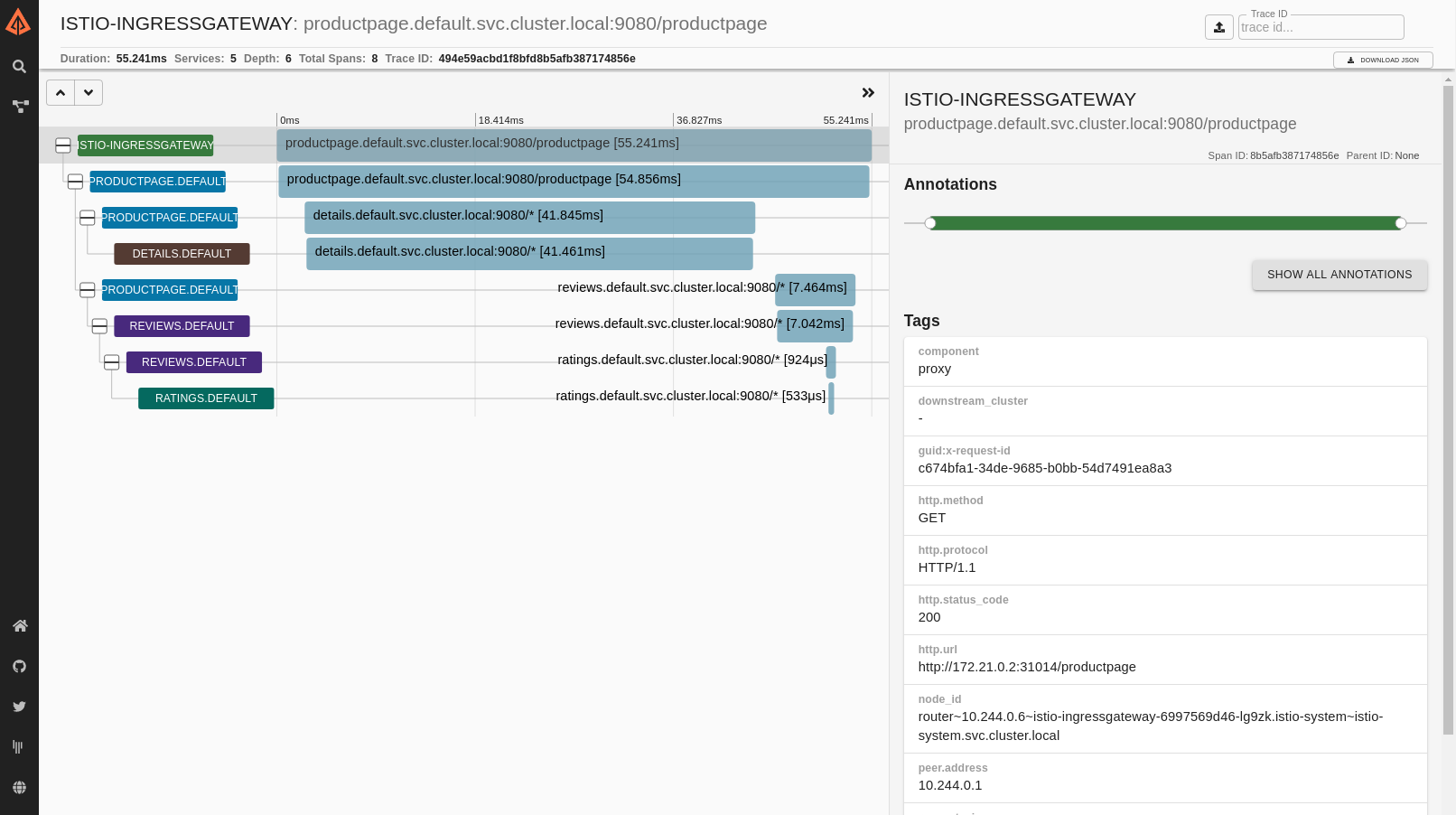
In summary, a service mesh manages all or part of the following aspects: network traffic management, flow security, and network observability (fig.

An overview of the workings of a service mesh: “proxy” containers are added to each pod to manage interactions with the service mesh.241
Technically, a service mesh will install on your orchestration software (e.g., Kubernetes) and attach a container called sidecar to each pod (group of containers/application). This sidecar acts as a network proxy, managing the above-mentioned interactions with the service mesh.
However, a service mesh is not lightweight technology: it requires internal administration and training (for both developers and administrators) before you can reap its benefits. Don’t expect a technology that reduces your system administrators from 50 to 5 to be manageable by only 2 people. Service meshes are undoubtedly beneficial, but ensure you’re sized to manage them.
Several service meshes are available, each with its strengths and weaknesses. Take your time to compare them before selecting one. For instance, Linkerd242 is easier to deploy than Istio but offers fewer features. Consul243 is another alternative.
As described in the chapter “A Foundation for Your Resilience”, Cloud platforms offer the advantage of including a variety of services that cater to common security and monitoring needs. These services automatically handle features that historically were tedious to develop individually for each software or for the infrastructure itself.
Using CRDs244 or by deploying the Helm245 configurations of Cloud native246 tools, it is possible to easily “install” foundational services within a Kubernetes cluster. Here’s a non-exhaustive list of services that can be natively supported in your cluster and managed centrally:
Centralization of application and network logs and traces (see Filebeat, Fluentd (fig.

Centralization of performance metrics of cluster nodes and containers (see Mimir, Metricbeat, fig.
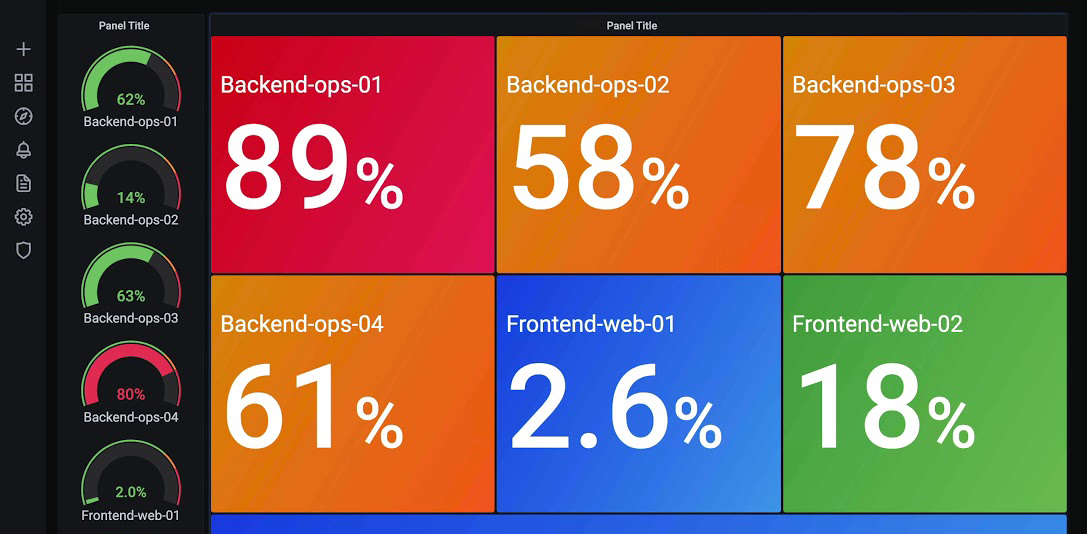
Antivirus analysis of node and container content (see Docker Antivirus Exclusions, Kubernetes ClamAV)
Detection of suspicious Linux system call behaviors (see Sysdig Falco)
Control and audit of cluster configurations (see Gatekeeper (fig.
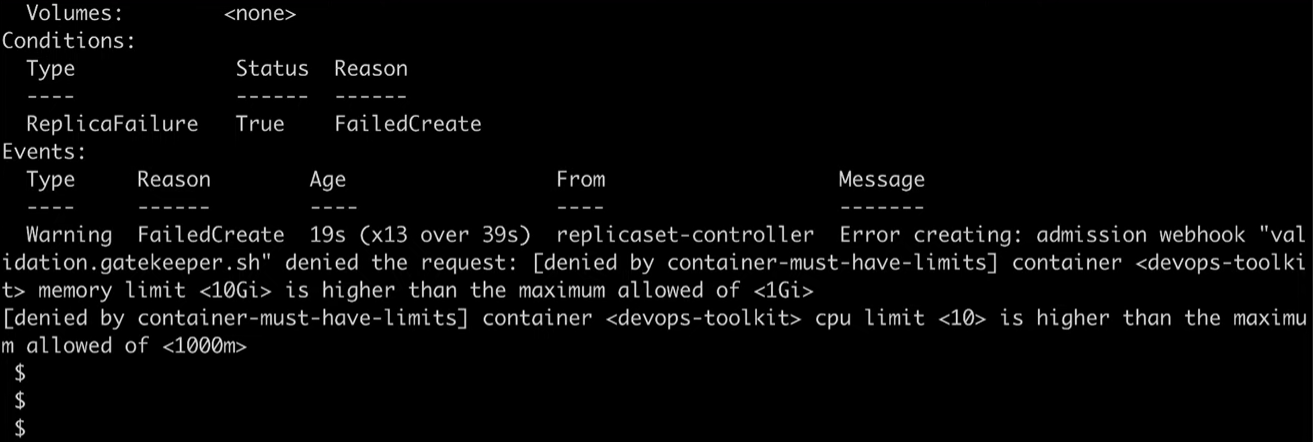
Management of application secrets (passwords, tokens) (see Vault (fig.
Automated backup of persistent volumes (see Velero)
Encryption of network traffic between containers (see chapter “Service Mesh”, fig.
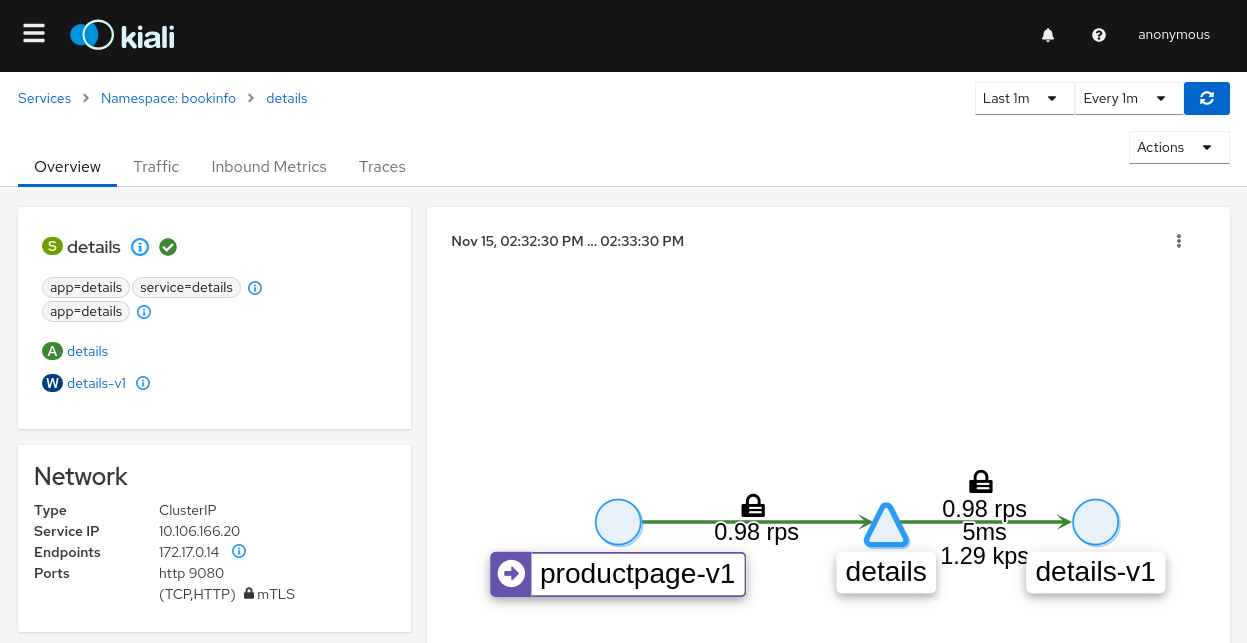
details service to the details-v1 pod. Source: istio.io.Management of security certificates (see chapter “Service Mesh”)
Management of web service authentication (see Istio Ingress Gateway, Keycloak)
Integration and automation are the fundamental characteristics of a Cloud foundation. Once again, in DevOps, it’s believed that something not automated won’t be used.
The technologies mentioned above automatically interface with the deployed software. In the Cloud, it’s not the software’s job to interface with the foundation’s technologies, but rather the foundation interfaces with the software.
The project manager is responsible for doing everything necessary to ensure the project meets its objectives. They often play the role of a product owner - a term defined in the Agile methodology - who acts as a liaison between technical and business teams. They are the one who “sells” your project to its users.
It’s vital for this role to be close to both the end-users, to understand business challenges, and to the technical team to grasp engineering stakes.
Sometimes, project managers tend to “over-promise” timelines. This practice creates stress for teams and ultimately leads to client frustration. Indeed, clients are promised a tool that will only be delivered later. Thus, it’s essential to manage expectations.
“Under-promise, over-deliver”
To accelerate the adoption of your solutions, invite a business representative to your presentations. If this person is convinced by your product, they might be inclined to present it themselves, explaining its significance in their daily work.
Getting clients to vouch for you is the best way to gain credibility. It proves that your solution meets a current need. By illustrating a use case, your audience can quickly envision how they might use your tool. If you want to convince a hard-to-reach audience, a client testimonial is your best ally.
Try to establish a strong network of a few “ambassadors” (product advocates) within your organization to assert your legitimacy and support your initiative. Besides this support, the ambassador will help capture user feedback or provide it themselves to refine your value proposition.
In the private sector, especially among the GAFAM248, it’s common for employees to get one day a week dedicated to participating in a different project within the company. One day out of five, they choose to work for another team. This option benefits both the employee and the company: the employee explores different technologies and practices, enhances skills in those areas, and then leverages this knowledge for other projects they handle.
Another example is the “10% program” by French governmental organisms DINUM249 and INSEE250. Based on volunteering, the aim is for public service agents to dedicate 10% of their working time to common interest projects251.
Try to offer your hierarchy this possibility so that each employee can benefit from this program: this will encourage exchanges, bring the teams closer together and build loyalty among your employees by allowing them to discover and work on new subjects.
To take advantage of all the resources at your disposal, consider employing reserve personnel within your team if your organization allows it. Even if they are only present a few days a year, they can support you on specific tasks. For example, an information systems security reservist will help you complete certification. A data scientist to evaluate an artificial intelligence solution or provide one-off support on a complex dataset to process.
Major organizations today primarily rely on services provided by industrial partners for their technical projects. This might be due to a lack of in-house experts, a lack of human resources, or both. It’s a mistake to simply trust the industrial partner thinking, “they are the experts, everything will work, I just need to pay.” Anyone who has led an industrial program has faced challenges with stakeholders understanding the business stakes (project managers vs. business vs. industrial partners) and has seen that a project never goes 100% according to the planned blueprint.
It’s a strategic error to believe that merely paying a service provider will get you the solution you expect. If you’re not a technical expert in the field who has practiced recently, you’ll never be at a level to effectively challenge your provider’s proposals. You risk either not addressing your business challenges, losing money, or likely both.
This is why it’s crucial to have in-house, within your own teams, experts who are practitioners on the topic you want to develop. They are the only ones capable of critically assessing your service provider’s proposals to save you time and prevent you from being tricked with features that have exorbitant costs or unrealistic promises.
Every DevOps and SRE engineer knows: it’s impossible for a system to function 100% of the time. That’s why you cannot expect from a service provider, regardless of the price you pay, to deliver something 100% functional.
For instance, even Google does not promise more than 99.9% availability (SLA)252 with its capitalization of over 1.6 trillion dollars and its approximately 150,000 rigorously selected employees. Amazon (AWS) with its capitalization of more than 1.4 trillion dollars does not guarantee more than 99.5%253.
The traditional approach of institutions working with industrial partners resembles “waterfall” developments: a major meeting is set up to gather requirements, a technical and functional specification document is drafted to structure the contract, developments are then undertaken, and the final product is delivered, concluding the contract.
Given the intense dynamics of the digital realm, this method is suboptimal. The average lifespan of software doesn’t exceed 3 to 5 years254, even if periodic updates are provided.
Consider this scenario: you are tasked with equipping your organization with a new digital tool.
In the end, the entire process might take roughly a year, and you’ve yet to place the tool in the users’ hands. At this point, you can’t even be sure it meets the need, considering that the stated requirement often differs from the actual requirement.
Finally, when the users get their hands on the tool, unfortunately, it might not fully meet the needs, might be impractical, and your colleagues might prefer the old tools they are familiar with.
Such an approach is untenable today. One of the tenets of DevOps is the ability to “fail fast,” iterate frequently, and swiftly arrive at a version that meets requirements. In this context, the DevOps methodology advises against rushing into a “fully fleshed out” specification. Start with an initial version, fail, iterate, and perfect the tool alongside your customer.
Remember this principle? “Break down organizational silos by involving everyone”: it’s vital to engage your customers throughout the project lifecycle. If you don’t frequently consider their feedback, the end product might be misaligned. Even if it does meet their needs, it might be too complex and thus unappealing.
Thus, if you aim to work efficiently with an external company, you should bring all project-related stakeholders closer. Ensure everyone’s voice is heard by establishing an easy and practical communication tool for feedback and suggestions. For instance, you could ask the industrial partner to grant access to their software factory (e.g., GitLab, BitBucket, GitHub) for your teams to provide comments, and for engineers to address them in a feedback loop.
GitLab also supports continuous deployment, allowing the industrial partner to provide clients with a URL to access the latest version of the software. This way, you avoid lengthy meetings and achieve flexibility. The goal is met: you iterate, quickly.
The figure
showcases the Kanban view in GitLab, where comments on software (tasks, feedback, bugs…) are consolidated.
If you can’t influence your collaboration practices with the industrial partner, at the very least, internally organize to have a collaborative project management tool. For instance, use software like Atlassian Confluence (see fig.
.")
Kanban view in Atlassian Confluence showing consolidated comments on software (tasks to be done, feedback, bugs…).
For instance, the ITZBund (German Federal Center for Information Technology, akin to France’s ANSSI255) has been using the open-source software Nextcloud256 in its Bundescloud (inter-ministerial cloud) since 2018. It enables file sharing and collaboration on a unified platform. Roughly 300,000 institutional and industrial users employ it. A year later, the French Ministry of the Interior also adopted it257.
This practice is a win-win for everyone: clients experience shorter delivery times, end-users get a tool that better fits their needs, the industrial partner sees the potential for renewed contracts with satisfied clients, and taxpayers get value for their money. Overall, everyone saves time, is pleased with the outcomes, and feels more engaged in every interaction.
It is crucial to measure the efforts you invest in your initiative. This allows for a factual assessment of the effectiveness of your decision-making. Of course, initially, it’s not uncommon to witness a degradation in performance since you are altering routines, meaning the organization’s equilibrium. If you notice a decline in the metrics over time, you know you need to adopt a different strategy to reverse the trend (see chapter “Knowing when to innovate and when to stop”).
According to research, an organization’s technical maturity can quadruple its team’s performance258. Let’s explore some indicators used in the industry. These indicators are frequently debated but still seem to be the widely accepted reference.
The success of a DevOps initiative is measured using 4 theorized measures (4 key metrics259). An additional fifth measure reflects the organization’s operational performance. These metrics showcase results at the overall scale of your IT systems and your organization rather than just software measures. The latter might stem from local improvements, compromising overall performance. Let’s dive into them:
All these measures are based on the infrastructure’s availability rather than its resilience. DORA report researchers subsequently posed a new question to organizations in 2021260. This led to the introduction of a fifth metric:
If you are starting your initiative from scratch, comparing yourself to industry performance might not be relevant. Keep them in mind to know what goals to aim for but don’t judge your success based on them. Gauge it based on the progression of your own measures over time. Everyone starts from an initial state with the aim to improve it.
The DORA 2022 report classified the surveyed organizations into three performance categories (low, medium, and high) for its four key measures:
| Measure | Low | Medium | High |
|---|---|---|---|
| Deployment Frequency | Between 1 and 6 every 6 months | Between 1 and 4 per month | On-demand (multiple times a day) |
| Lead Time for Changes | < 6 months | < 1 month | < 1 week |
| Time to Restore Service | < 1 month | < 1 week | < 1 day |
| Change Failure Rate | 46% - 60% | 16% - 30% | 0% - 15% |
GitLab even allows for real-time visualization of these metrics starting from version 12.3 (fig.
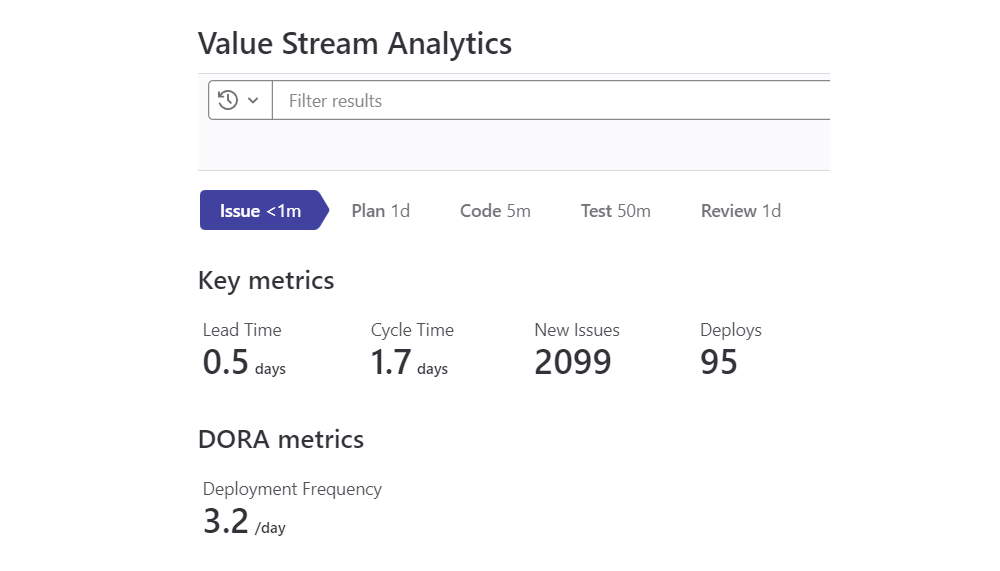
If you have a relatively recent version of GitLab or have set up continuous integration pipelines, you can measure most phenomena. Otherwise, ask your teams to record events on a collaborative interface (e.g., Google Sheets, Airtable, Atlassian Confluence, Baserow, NocoDB).
Added to these measurements is one I call the “resilient collaboration trend” (resilient collaboration trend or RCT). It captures the essence of a DevOps initiative in my view: succeeding in continuous innovation while maintaining low technical debt and providing the most available service possible. The following factors are multiplied to total the value of the resilient collaboration index (RCI):
We then observe and compare the trend of this index over time. It is this trend that can be compared to other projects.
For example, the GitLab project261 - one of the largest collaborative open-source projects - displayed a resilient collaboration index of 155 711 413 in Q2 2022, 188 809 628 (+17.5%) in Q3, and 202 865 477 (+7%) in Q4. The latter, with 4102 days since the creation of the git project (October 9, 2011 - January 1, 2023), 2474 contributors, 20 software releases, and an average availability of 99.95%262. The project was thus less agile in Q3 than in Q4 (-10.5%).
This index should be updated every quarter. This time interval can be shortened or extended depending on the maturity of your organization: the more confident you are in your ability to deploy regularly, the shorter your measurement interval can be. E.g., over a semester, a quarter, a month, or a week.
Unlike the SRE, which relies on specific measurements (e.g., “The 4 golden signals”, “Resilience indicators”), the DevOps lead has some freedom to choose the measurements that seem most relevant to them. That is, those that best assess the service they provide to internal teams. However, the modus vivendi between DevOps and SRE is the “deployment lead time”: both strive to make this parameter as satisfactory as possible.
Your organization is sometimes tasked with deploying software in environments as diverse as they are unique. If you’re lucky, these environments are few and connected. But things get complicated when the number starts to grow and they’re isolated. It becomes essential to find a standardized way to deploy updates while minimizing delays.
Built on Kubernetes, Apollo is the product used by Palantir to deploy and keep its services up to date across all its client bases. With hundreds of engineers, over 400 software products, and thousands of deployments every day, Palantir boasts deploying its services across a hundred different computing environments (AWS, GCP, Azure, classified private clouds disconnected from the internet, edge servers with intermittent connections…)263.
Driven by the constraint of regularly deploying on varied infrastructures, work on Apollo began in early 2015. It was progressively rolled out to its clients from 2017 and has been commercially available since the start of 2022, powering Palantir’s internal infrastructure. The product’s philosophy is to interface with your existing infrastructure and services (software forge, continuous integration engine, artifact registry…)264.
The company operates under the belief that software engineers and SREs each have their areas of expertise. On one hand, software engineers have a better understanding of how and when the software they develop should be updated. On the other, SREs are more familiar with the specifics and constraints of the environments in which they deploy265. Thus, software engineers develop the code, Apollo deploys it, and the SREs monitor to ensure everything went as planned.
That’s why Apollo’s interface primarily showcases two menus: “Environments” (SRE-oriented) and “Products” (software engineer-oriented).
Connected to git repositories, it allows tracking and approving any code modifications before deployment.
Lastly, Apollo offers centralized monitoring of the status of services deployed across all your environments from a single platform. Whether connected to your favorite observability service (e.g., Datadog, Prometheus, Pagerduty) or operating independently via the Apollo Observability Platform, it incorporates feedback of all sorts of measurements (logs, metrics, traces) to investigate incidents in detail.
With Apollo, Palantir introduces the concept of constraint-based continuous deployment266. Apollo deploys an agent in each environment, reporting the real-time status of that environment to determine how updates should be deployed. This means Apollo knows both the expected state of deployments on infrastructure and the real-time, up-to-date state of these deployments.
Considering modern applications often rely on external services, this mechanism helps avoid incompatibilities between different versions of an app deployed across varied environments.
For instance, if application foo version 1.1.0 requires the service bar to be deployed at version 1.1.0, Apollo won’t update foo:1.1.0 until bar:1.1.0 is available and deployed. The deployment of a new version of an application, dependent on a specific version of another, is often manually managed, even if continuous deployment is in place. Teams first ensure the dependent service (bar:1.1.0) is available and deployed before deploying its new version (foo:1.1.0). These dependencies are recorded in a specific file within the same project as the application’s source code.
Another example is database schema migration. By declaring a database schema version compatible with a specific application version, Apollo prevents deploying an app incompatible with a database yet to be updated. For instance, if foo:1.1.0 only supports the V2 schema of bdd:V1, foo:1.1.0 will only be deployed once bdd:V1 has migrated to V2. This way, Apollo knows which version of an application is eligible for deployment in which environment.
In 2016 surveys, 47% of organizations claimed to adopt a DevOps approach. This number rose to 74% in 2021267.
From 2019 to 2022, the distribution of DevOps initiatives by industry remained roughly the same268: primarily dominated by the tech sector (~40%), followed by the financial sector (~12%) and e-commerce (~8%). The institutional sector accounted for 2% to 4% of these initiatives, indicating ample room for innovation in this domain.
Here’s a breakdown of companies practicing DevOps in 2022269:
The 2019 crisis accelerated digital transformation initiatives, leading to a 23% growth in DevOps team sizes270 during that period.
In 2022, the geographical distribution of organizations adopting DevOps practices is still challenging to pinpoint. However, North America seems to be a major hub, accounting for about 33% of DevOps initiatives. Europe and Asia follow closely with approximately 33% each271 (with India at 21%). In 2019, North America accounted for 50% of these initiatives, Europe 29%, and Asia 9%. This indicates a growing interest in the subject among Asian countries. The average size of DevOps teams remains small, averaging around 8 members272.
This positions DevOps as a methodology primarily adopted by companies that have reached a critical mass and is yet to gain traction in non-tech businesses.
Transforming an organization, regardless of its size, is a complex task involving significant political, technical, and human challenges. Should this transformation fail, the consequences can be severe. At the same time, it’s crucial for your organization to consider the long-term implications of continuing with its current model. DevOps aims to minimize these risks through standardized methodologies and tools.
Research and the experience of thousands of businesses today allow us to understand the challenges related to transitioning organizations to the Cloud. Having proven its effectiveness, institutions are gradually shifting their focus to DevOps, although few have fully embraced it yet (see chapter “Distribution of initiatives”). One major hurdle remains in sourcing talent in this area, but the foremost challenge is to persuade the leadership.
Several strategies can be adopted depending on your hierarchical and technical position. The most common is to start with a pilot project that addresses internal needs (e.g., deploying software co-developed with your business teams). This can attract initial internal partners (see chapter “Internal team model”).
Provide services promptly to demonstrate the efficiency of your approach compared to traditional methods (e.g., software better suited to needs, streamlined deployment, quick response to incidents…). Once the early adopters are convinced, have them testify during your presentations to decision-makers. Business teams often agree to do this, feeling indebted for the services you’ve provided. With such a powerful impact, you can gradually rally a community to elevate your vision (see chapter “How to convince and keep faith”).
Facilitating change is primarily about minimizing risks undertaken. Starting small and iterating is the best approach to success. Moreover, by understanding the psychological and technical realities behind a transformation project, you’ll have all the tools and arguments for a quicker and less perilous transition (see chapter “Initiatives within organizations”). Presenting Cloud technologies and DevOps as evolutionary rather than disruptive techniques is an effective way to persuade.
Like major corporations that constantly invest in new technologies, every organization must be willing to take risks to remain competitive. Your executive committee should remain open to surprising perspectives and encourage experimentation.
For instance, it’s vital not to underestimate the potential of employees deemed challenging to manage. Some might be the visionaries that will define your future. Seriously considering the impact of their ideas is essential, lest you miss critical opportunities for the organization’s future (see chapter “Breaking down organizational silos”).
While business teams you assist see immediate benefits, this value is often more abstract for the leadership. As the instigator of a transformation, you need to invest time in familiarizing organizational decision-makers. Don’t hesitate to start with basic Cloud concepts and gradually clarify the implications of DevOps for stakeholders. It’s crucial to provide examples of how you’ve addressed internal dysfunctions with your approach.
The initiator should always be prepared to answer the following questions:
With the leadership convinced and granting you both technical and political resources, the journey is only beginning! Don’t advertise capabilities you don’t yet master. Start by providing access only to a subset of willing users and establish your procedures (management, administration, incidents).
Your initiative will inevitably face challenges initially. Welcome feedback graciously and enhance your services. Once confident in the service reliability, expand its deployment and communicate extensively.
You’ll soon notice that operational or business priorities often sideline infrastructure work (Cloud/DevOps) in favor of product developments (software). Yet, research shows that structuring around these proven methods enhances long-term efficiency (see chapter “Why DevOps?”). Ensure you allocate time for resilience work in your engineers’ schedules.
A DevOps infrastructure realizes its full potential once connected to your organization’s main network. This is when it can deploy frequent updates, respond quickly to incidents, and consolidate your teams’ work. If your project began on an isolated platform, focus now on connecting where your users are present (see chapter “The pillars of devops in practice”).
Measuring the effectiveness of one’s initiative over time is critical: both to ensure that one is moving in the right direction without dogmatism, and to provide quantifiable arguments to superiors or teams that still need convincing. Make sure to maintain a clear dashboard of these indicators (see chapter “Measuring the success of your transformation”).
Tools such as ChatGPT based on LLMs offer as many new opportunities (e.g., GitLab Duo, GitHub Copilot) as they introduce new threats (internal skills, deepfakes). Concurrently, security standards will continue to evolve at a breakneck pace. This advocates for a transformation of organizations towards a more agile digital universe. The future is shaping today, and the companies that will succeed best are those that manage to leverage the latest technologies and integrate them into their software development cycle (see chapter “Refusing the technological lag”).
Beyond the speed at which technology evolves and as with any area of expertise, this type of infrastructure requires the maintenance of the skills necessary to administer it.
We can easily imagine that a fighter pilot maintains his or her flying skills. Why would it be any different for engineers who maintain critical software vital to the institution’s operation? You and your teams must continue to stay ahead by training regularly (see chapter “Continuous training”).
In DevOps mode, organizations can afford to fail faster, with controlled risk, to innovate ahead of their competitors.
Now that you understand the array of challenges in DevOps, it’s insightful to explore some terms that one might come across in the field.
You’ve probably already heard numerous terms suffixed with “Ops”: in industrial proposals, job offers, or online services. All these terms describe specialties in computer system operations using various techniques and methodologies. Let’s define a few:
The emergence of these terms denoting specialties or practices in IT infrastructure administration is likely tied to the maturity the industry has achieved thanks to Cloud services. These services have greatly streamlined infrastructure administration, paving the way for advanced optimization discussions.
Each of these specialties is a way to optimize your DevOps practices and should adapt to the maturity of the company. Don’t rush to implement all of them before you’ve thoroughly understood and practiced DevOps in your organization.
This chapter lists examples of job descriptions in the field of DevOps.
To avoid wasting time and minimize poor hiring decisions, your organizational goal must be clearly defined.
If it’s not well-defined, the job description may become a catch-all for technical tasks that could occupy an entire team of engineers. You then run the risk of appearing as an immature organization and may deter top candidates.
You need to make the effort to define the scope of the job you are looking to fill, or acknowledge the fact that your environment is so unique that it requires frequent (or even “tactical”) adjustments. Except in the fields of security and defense, you should not consider your operation as such.
The sample job descriptions below are indicative and should be adapted to your situation (team and organizational maturity and size). Adjust the context and tasks you wish to assign to your future engineer. Also, tailor the skills you wish to highlight according to your current project.
The requirements for the positions are described based on the technical maturity of the company (beginner, intermediate, advanced) and the level of experience expected of the candidate (junior, intermediate, or senior).
A “Education or Experience” section is also provided to give you an idea of the courses the candidate might have taken to qualify for the position. However, consider in IT that a degree becomes irrelevant after 5 years of professional experience. It’s the latter and the projects undertaken by the candidate that determine their expertise level.
| Job Level | Intermediate to senior277 (depending on responsibilities assigned to the candidate). Apprentice or junior possible if experienced personnel in the team. |
| Organizational Maturity | Beginner to intermediate |
| Approximate Remuneration (October 2023) | >90k$/year (beginner), >115k$/year (senior) |
As part of our organization’s digital transformation and supported by our management, you will help define new development, deployment, and administration processes.
You will implement tools and practices to benefit our developers’ productivity and guide internal teams in adopting DevOps practices.
From the technologies currently in use by our teams, you will contribute to strategic discussions and decisions regarding technologies to be adopted for our organization’s future.
Acting as a bridge between our development teams and within our SRE team of X members, you will be responsible for:
Skills:
Education or Experience:
If you have at least 5 years of professional experience, we prioritize it and don’t consider your degree.
This position can lead to roles such as System Engineer, SRE, or DevOps Security Engineer.
| Job Level | Intermediate or Senior (depending on responsibilities to be assigned to the candidate). Apprentice or Junior possible if there are experienced personnel on the team. Internship not considered (too short). |
| Organization Maturity | Intermediate to Advanced |
| Approximate Compensation (October 2023) | >95k$/year (beginner), >120k$/year (senior) |
At the core of our organization’s smooth operation, you will be responsible for ensuring the availability, reliability, and resilience of our information systems. You will strive to sustain the infrastructures while balancing the velocity of developments and system stability.
Within our SRE team of X individuals, your responsibilities will include:
Skills:
Education or experience:
If you have at least 5 years of professional experience, we prioritize that and do not focus on your degree.
This position can lead to roles such as Infrastructure Manager, DevOps Security Engineer, or System Engineer.
| Job Level | Junior to Senior (depending on responsibilities to be assigned to the candidate) |
| Organization Maturity | Intermediate to Advanced |
| Approximate Compensation (October 2023) | >95k$/year (beginner), >125k$ (senior) |
As part of our organization’s digital transformation and supported by management, you are the “Sec” in our “DevSecOps” mode. Your role is to ensure security best practices without hindering development velocity.
Integrated within our SRE team, you will be responsible for securing the entire software development and deployment chain. Based on our security policies and legal constraints, you will translate these documented rules into code (within CIs) or via tool implementation, ensuring their adherence. You will define security practices for the present and future of our organization.
Acting as the interface between our development teams and our SRE team, your tasks will be:
Skills:
Education or experience:
If you have at least 5 years of professional experience, we prioritize that and do not focus on your degree.
This position can lead to roles such as System Engineer or SRE.
| Job Level | Intermediate to Senior |
| Organization Maturity | Advanced |
| Approximate Compensation (October 2023) | >100k$/year (beginner), >130k$/year (senior) |
With a background in software engineering or system administration and proven skills in software engineering, you will be responsible for the development and maintenance of tools that enhance our software development and deployment cycle on a daily basis.
Within the SRE team, you will develop or integrate administrative tools to make the lives of our developers and SREs easier.
You will participate in the establishment of a data-lake as part of the government initiative data.gov.
Skills:
Education or Experience:
Have at least 5 years of professional experience? We prioritize it and don’t consider your degree.
Gartner. Gartner Says Cloud Will Be the Centerpiece of New Digital Experiences. 2021.↩︎
Atlassian; CITE Research. “2020 DevOps Trends Survey”. 2020.↩︎
National Assembly Law Information (South Korea). “Cloud Computing Act”. 2015.↩︎
National Information Resource Service (South Korea). “History (of NIRS)”. nirs.go.kr.↩︎
Downloadable document: links.berwick.fr/SPnDtI↩︎
Government of Canada. “Objective 2020”. 2013.↩︎
Government of Canada. “Government of Canada Cloud Adoption Strategy”. 2018.↩︎
Ministry of Defence (United Kingdom). “Defense AI strategy”. 2022.↩︎
Details of the call for tender and the NELSON program available on digitalmarketplace.service.gov.uk.↩︎
Department of Defense (United States). “DoD IT Enterprise Strategy and Roadmap”. 2011.↩︎
Department of Defense (United States). “DoD Enterprise DevSecOps Reference Design”. 2019.↩︎
WANG, Abel (DevOps Lead at Microsoft). “Enterprise DevOps Transformation” (YouTube video). 2020.↩︎
For example, the affair of the AUKUS defense pact↩︎
AUDINET, Maxime; LEMONIER Kevin. “Russia’s informational influence system in French-speaking sub-Saharan Africa: a flexible and composite ecosystem, Questions de communication, 41 | 2022, 129-148” .↩︎
GAFAM: Large American technology companies (Google, Facebook, Amazon, Apple, Microsoft). Synonyms: FAANG, NATU, MAMMA, MANAMANA.↩︎
NATU: Other large American technology companies, more recent in use (Airbnb, Tesla, Uber, Netflix).↩︎
Multiple use cases and testimonials from companies from all types of domains on cloud.google.com/transform.↩︎
InfoQ. Podcast “Andrew Clay Shafer on Three Economies, the Wall of Confusion, and the Origin of DevOps”. 2020.↩︎
KIM, Gene; DEBOIS, Patrick; WILLIS, John; HUMBLE, Jez; ALLSPAW, John. The DevOps handbook: how to create world-class agility, reliability, and security in technology organizations. 2015.↩︎
“SRE is the practical implementation of DevOps.” (chapter “SRE compared to DevOps”). aws.amazon.com/what-is/sre.↩︎
See the micro-study “DevOps and SRE Definitions” of this project: github.com/flavienbwk/book-devops/studies/devops-sre.↩︎
BERWICK, Flavien. QA basics: Medium article “Keep your code and documentation fresh”. 2023.↩︎
Google. Chapter “How SRE Relates to DevOps”, SRE Book. sre.google.↩︎
PAUPIER, François; CHAILLAN, Nicolas. Postmortem #19: DevSecOps at the U.S. Air Force. 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Context matters”, page 6. 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Acknowledge the J-Curve”, page 28. 2022.↩︎
In 2021, 74% of organizations reported adopting a DevOps approach. Statistics by Redgate. “The 2021 State of Database DevOps”. 2021.↩︎
The AR-15 is a lightweight semi-automatic rifle produced by the American company ArmaLite.↩︎
Revue Défense Nationale. “The challenges of”high intensity“: strategic or capability issue?” . 2020.↩︎
DevSecOps Program Vulcan of the American Defense Information Systems Agency (DISA). 2022.↩︎
Platform One is a platform launched in 2018 by the US Air Force allowing software collaboration in a DevSecOps approach, at scale of the United States Department of the Armed Forces.↩︎
LinkedIn post from Nicolas CHAILLAN (creator of Platform One) declaring having proposed to DISA to collaborate on Platform One, in reaction to the DISA announcement saying they want to create a DevSecOps platform. 2022.↩︎
Breaking DEFENSE. Article “Learning from Ukraine, DISA extends Thunderdome to include classified SIPRNet”. 2022.↩︎
Phenomenon of the subject supposed to know, according to which an individual will give credit to an external expert by the simple fact that he thinks him more legitimate than himself or than the internal expert, yet the only ones to know the real needs of the organization. Theory of Jacques LACAN. “Seminar The four fundamental concepts of psychoanalysis. The foundations of psychoanalysis”.↩︎
CHRISTENSEN MAGLEBY, Clayton. Book “The innovator’s dilemma: when new technologies cause the failure of large companies”. 1997.↩︎
Sources statista.com: fr.statista.com/statistiques/559394↩︎
Reuters. “Alphabet shares dive after Google AI chatbot Bard flubs response in ad”. 2023.↩︎
CNN. “Microsoft’s Bing AI demo called out for several errors”. 2023.↩︎
PICHAI, Sundar. “An important next step on our AI journey”. 2023.↩︎
SILBERZAHN, Philippe. The duck syndrome: how declining organizations get used to mediocrity (FR). 2022.↩︎
DUNLAP, Preston. Defying gravity. 2022.↩︎
WIGGINS, Adam. The New Heroku (Part 4 of 4): Erosion-resistance & Explicit Contracts. 2011.↩︎
MORGAN, William. How to get a service mesh into production without getting fired (conference). 2018.↩︎
Reference to the Theory of Mental Models introduced by JOHNSON-LAIRD in 1983 (cf. THEVENOT C, PERRET P. The development of reasoning in problem solving: the contribution of the theory of mental models. Développements. 2009).↩︎
SILBERZAHN, Philippe. Mental model strategy (FR). 2022.↩︎
DevOps Institute. Global Upskilling IT report, chapter “Industry” (page 162). 2022.↩︎
Popular theory on innovation, inspired by the speech of Nicholas KLEIN, lawyer for the first American textile union (the Amalgamated Clothing Workers of America), in 1918.↩︎
“This technique was imagined by Louis Renault in 1898 and implemented by Henry Ford in 1913”. Source: fr.wikipedia.org/wiki/Ligne_de_montage↩︎
VANCE, Ashlee. Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic Future. page 83. 2016.↩︎
Speech by Elon MUSK on the occasion of the controlled landing of Falcon 9, a reused rocket, on the SpaceX video replay “It’s been 15 years to get to this point… This is a great day… in proving that something could be done that many people said was impossible” March 30, 2017.↩︎
Central idea or main message that the speaker wishes to communicate to his audience, usually with the goal of them taking an action.↩︎
Levels of military strategy, defining different times and spaces of action. Source: fr.wikipedia.org/wiki/Military_Strategy↩︎
“(The Scientific Council) assists Public Health France in its mission of contributing to the development and implementation of national and European public health policies.”. santepubliquefrance.fr. 2022.↩︎
Artificial intelligence models: algorithms trained to solve a task, most of the time without supervision↩︎
GPU Drivers: libraries allowing accelerated calculation on graphics card↩︎
Jupyter Notebook: popular development tool among data scientists↩︎
The “carrier” describes the structure, machinery and heavy equipment of a boat.↩︎
Wishes from Army Chief of Staff Thierry BURKHARD. “…leaders must adapt to the acceleration of our world if necessary by taking calculated risks.”. 2022.↩︎
Henrik Kniberg’s blog. blog.crisp.se/author/henrikkniberg.↩︎
ANSSI’s “common criteria” certification requires the definition of a version of the audited software.↩︎
Google Cloud. Announcing the 2022 Accelerate State of DevOps Report: A deep dive into security. 2022.↩︎
Qualification: It is the recommendation by a State of a proven and approved cybersecurity product or service. It attests to their compliance with regulatory, technical, and security requirements promoted by a State’s cyberdefense agency (e.g., ANSSI in France, CISA in the U.S.), providing a guarantee of the product’s robustness. It enables the product to access regulated markets.↩︎
It is the attestation of a product’s robustness, based on a compliance analysis and penetration tests conducted by a third-party evaluator under the authority of the State’s cyberdefense agency. It allows access to regulated markets and ensures a certain level of trust. The process lasts between 6 and 24 months.↩︎
Agreement for the mutual recognition of IT certifications between members. More at commoncriteriaportal.org/ccra/index.cfm↩︎
Similar programs to FedRAMP can be found. For instance: SecNumCloud in France, G-Cloud in the UK, GC-CSRMAP in Canada, C5 in Germany or ENS in Spain.↩︎
ATO: Authority to Operate. Authorization granted through FedRAMP to provide government agences with Cloud services.↩︎
A contribution qualifies any modification made to a code base. This could be adding a line of code, documentation, deleting a file or even adding an issue.↩︎
AWS CodePipeline. aws.amazon.com/codepipeline.↩︎
GitLab required approvals documentation. GitLab.com.↩︎
Scripts that analyze source code to report programming errors, bugs, stylistic errors, and suspicious code constructs. The goal of linting is to enforce a consistent code style and find potential errors before code execution.↩︎
BIDEN Administration. FACT SHEET: President Signs Executive Order Charting New Course to Improve the Nation’s Cybersecurity and Protect Federal Government Networks. 2021.↩︎
BIDEN Administration. Executive Order on Improving the Nation’s Cybersecurity. 2021.↩︎
BIDEN Administration. National Security Memorandum. 2022.↩︎
OWASP DevSecOps Maturity Model (DSOMM). dsomm.owasp.org.↩︎
DataDog DevSecOps Maturity Model. datadoghq.com.↩︎
AWS Security Maturity Model. maturitymodel.security.aws.dev.↩︎
GitLab DevSecOps Maturity Assessment. about.gitlab.com.↩︎
National Telecommunications and Information Administration’s SOFTWARE BILL OF MATERIALS. ntia.gov.↩︎
The CIS Benchmarks are a set of rules and best practices for IT configurations. They are published by the American association Center for Internet Security (CIS).↩︎
Source Code Analysis Tools. owasp.org.↩︎
Vulnerability Scanning Tools. owasp.org.↩︎
Free for Open Source Application Security Tools. owasp.org.↩︎
Not to be confused with software frameworks like ReactJS or Symfony, a framework can designate simple documentation, bringing together a set of rules and specifications governing the use of technologies to respond to a problem (e.g. securing security). software supply chain).↩︎
Supply chain Levels for Software Artifacts (SLSA, pronounced “salsa”) is a set of security rules recommended to secure its software development and deployment chain.↩︎
Google Cloud. Binary Authorization for Borg (BAB). 2022.↩︎
FRSCA project GitHub project: github.com/buildsec/frsca.↩︎
GitHub project of the SLSA project. github.com/slsa-framework/slsa.↩︎
SSCSP GitHub Project: github.com/cncf/tag-security/blob/main/supply-chain-security/supply-chain-security-paper↩︎
GitHub project of the CNCF security technical advisory group: github.com/cncf/tag-security↩︎
CNCF. Announcing the Refreshed Cloud Native Security Whitepaper. 2022.↩︎
NIST. Secure Software Development Framework version 1.1, doi:10.6028/NIST.SP.800-218. 2022.↩︎
OWASP Software Component Verification Standard. scvs.owasp.org.↩︎
A commit is a change made to a file in a codebase. This can be documentation, computer code, or even a configuration file.↩︎
US Department of Defense Chief Information Officer Online Library: dodcio.defense.gov/library↩︎
The CVE list is overseen by MITRE, an organization funded by the Cybersecurity and Infrastructure Security Agency (CISA) which is part of the United States Department of Homeland Security.↩︎
Iron Bank presentation from Platform One’s Big Bang. US department of defense.↩︎
Website of the Platform One project. p1.dso.mil.↩︎
Iron Bank Hardening guide overview. docs-ironbank.dso.mil.↩︎
GLENN, Eddie. How to secure your software build pipeline using code signing. 2021.↩︎
WITHOUT. SANS 2022 Security Awareness Report: “Human Risk Remains the Biggest Threat to Your Organization’s Cybersecurity”. 2022.↩︎
OKTA. State of zero trust report. 2022.↩︎
What is the castle-and-moat network security model? cloudflare. com.↩︎
BCG; ANDRH. Study “The future of work seen by HR managers - 2nd edition”. 2022.↩︎
CASB / Cloud Access Security Broker: intermediary service authorizing or not access to an application by a user.↩︎
Zero Trust Network Access (ZTNA) is a category of technologies that provides secure remote access to applications and services based on defined access control policies. Definition by paloaltonetworks.com.↩︎
SASE / Secure Access Service Edge: combination of multiple network security features to enable dynamic access to an organization’s resources↩︎
ANSSI. The zero trust model. 2021.↩︎
RORY, Ward; BEYER, Betsy. “BeyondCorp: A New Approach to Enterprise Security”. 2014.↩︎
NIST’s Implementing a zero trust architecture website: nccoe.nist.gov/projects/implementing-zero- trust-architecture↩︎
US Department of Defense. Cloud Native Access Point specifications. 2021.↩︎
Codespaces is a GitHub product allowing you to launch an ephemeral development environment directly in GitHub: github.com/features/codespaces.↩︎
Coder is a tool similar to Codespaces for on-premise, allowing you to instantiate a development environment running on a remote machine: github.com/coder/coder.↩︎
Development environment providing an IDE on a Kubernetes pod. github.com/eclipse/che.↩︎
OVH Shadow is a Cloud service allowing remote access to machines via the Internet. shadow.tech.↩︎
Microsoft; Sogeti. Securing Enterprise DevOps Environments, chapter “Control the developer environment with a cloud environment” page 9. 2022.↩︎
IDE: Integrated Development Environment. Code entry and management interface. E.g: Visual Studio Code (VSCode), Atom, JetBrains IDEs.↩︎
The Public Key Infrastructure (PKI) or Key Management Infrastructure (IGC) are technologies (software and/or hardware) making it possible to manage the life cycle (creation/revocation) of security certificates of a infrastructure. Non-exhaustive uses: electronic signature, data encryption, “HTTPS” certificates.↩︎
Active Directory (AD) is a directory service in which system administrators can manage access controls to different infrastructure resources. It runs on Microsoft Windows Server.↩︎
ANSSI. Security recommendations for Docker container deployments. 2020.↩︎
A sidecar is a separate container that runs alongside an application container in a Kubernetes pod.↩︎
Helm is a technology standardizing and simplifying the deployment of applications in Kubernetes. helm.sh.↩︎
Example operating system: Debian, Ubuntu, Alma Linux, Microsoft Windows 10, Apple MacOS. English: operating system (OS).↩︎
Open Source Initiative; Perforce. “State of Open Source survey”. 2022.↩︎
OpenForum Europe; Fraunhofer ISI. “Study on the impact of Open Source for the European Commission”. 2021.↩︎
McALLISTER, Neil (The Register). “Redmond top man Satya Nadella: ‘Microsoft LOVES Linux’”. 2014.↩︎
WARREN, Tom (The Verge). “Microsoft has some old bad habits the community needs to trust won’t happen again”: Here’s what GitHub developers really think about Microsoft’s acquisition. 2018.↩︎
LARDINOIS, Frederic (Techcrunch). “Four years after being acquired by Microsoft, GitHub keeps doing its thing”. 2022.↩︎
Techcrunch. “Protestware on the rise: Why developers are sabotaging their own code”. 2022.↩︎
BIRSAN, Alex. “Dependency Confusion: How I Hacked Into Apple, Microsoft and Dozens of Other Companies”. 2021.↩︎
BERWICK, Flavien. “Top 10 Cloud Technologies Predictions (according to Google VPs), point 2”. 2022.↩︎
GitLab. “Security at GitLab”. about.gitlab.com/handbook/security.↩︎
ARHIRE, Ionut. “Google Boosts Bug Bounty Rewards for Linux Kernel Vulnerabilities”. 2022.↩︎
The definition and guide of the Open Source Program Office is available on GitHub. github.com/todogroup/ospodefinition.org.↩︎
CLIMENT, Jesus (systems engineer at Google Cloud). Shrinking the time to mitigate production incidents. 2019.↩︎
“A role-playing game for incident management training”: github.com/dastergon/wheel-of-misfortune↩︎
“Fun, gamified, hands-on learning: AWS Gameday”. aws.amazon.com/gameday.↩︎
IDE: Integrated Development Environment. Code entry and management interface. E.g: Visual Studio Code (VSCode), Atom, JetBrains IDEs.↩︎
Sonatype Nexus is a software platform for hosting and managing its artifacts, binaries, packages and files used in its software supply chain. sonatype.com/products/nexus-repository.↩︎
JFrog Artifactory is a software platform to host and manage all artifacts, binaries, packages, files, containers and components used in its software supply chain. jfrog.com/artifactory.↩︎
Distribution is software for storing and distributing container images. Formerly “Docker Registry”. github.com/distribution/distribution.↩︎
Software forge developed and hosted in France. froggit.fr.↩︎
git is a “version control” system created in 2005, tracking modifications made to files in a project (management of file history, merging of contributions, accountability of actions). It is the most used in the world. Historical and less popular alternatives exist: Apache Subversion (SVN), Mercurial.↩︎
“Markdown is a lightweight markup language created in 2004 by John GRUBER, with the help of Aaron SWARTZ, with the aim of providing an easy-to-read and easy-to-write syntax.” Source: fr.wikipedia.org/wiki/Markdown.↩︎
markdown-slides is a tool for creating presentations from Markdown files. github.com/dadoomer/markdown-slides.↩︎
Slides is a tool for creating presentations in a terminal from Markdown files. github.com/maaslalani/slides.↩︎
Remark is a tool for creating presentations from Markdown files. github.com/gnab/remark.↩︎
Remark is a tool for creating presentations from HTML files. github.com/hakimel/reveal.js.↩︎
S3 (Amazon S3) is a distributed S3 object file storage technology created by Amazon. aws.amazon.com/s3.↩︎
MinIO is a distributed S3 object file storage technology. min.io.↩︎
Hadoop Distributed File System (HDFS) is a distributed file storage technology in the Hadoop ecosystem. hadoop.apache.org.↩︎
CephFS is a distributed file storage technology. ceph.com.↩︎
Distributed Cloud-native block storage for Kubernetes. longhorn.io.↩︎
Data Version Control (DVC) is a system for versioning massive data (e.g.: artificial intelligence models), based on Cloud storage technologies (e.g.: S3) and allowing it to be referenced in a git project. dvc.org.↩︎
Platform One is a platform launched in 2018 by the US Air Force allowing software collaboration in a DevSecOps approach, at scale of the United States Department of the Armed Forces.↩︎
NATO. The NCI Agency’s Software Factory: a new way to collaborate with industry. 2019.↩︎
IDE: Integrated Development Environment. Code entry and management interface. E.g: Visual Studio Code (VSCode), Atom, JetBrains IDEs.↩︎
HAMMANT, Paul. “Trunk based development: Game changers”. trunkbaseddevelopment.com.↩︎
GitHub project of git-flow: github.com/nvie/gitflow.↩︎
“Gitflow has fallen in popularity in favor of trunk-based workflows, which are now considered best practices for modern continuous software development and DevOps practices.” - Atlassian Tutorials (atlassian.com)↩︎
POTVIN, Rachel. “Why Google stores billions of lines of code in a single repository”. 2016.↩︎
MORRIS, Ben. “Why trunk-based development isn’t for everyone”. 2019.↩︎
Scrum.org. “What is Scrum? A better way to work together and get work done.”. scrum.org.↩︎
Atlassian. “What is Kanban?”. atlassian.com/agile/kanban.↩︎
Google. “Code Review Developer Guide”. google.github.io/eng-practices/review.↩︎
Full resolution illustration of Flexible Flow. links.berwick.fr/flexible-flow.↩︎
WIGGINS, Adam. The New Heroku (Part 4 of 4): Erosion-resistance & Explicit Contracts. 2011.↩︎
Sticky sessions, or “session affinities”, are a technique used for load balancing to ensure that a client’s requests are constantly sent to the same server during a session.↩︎
WIGGINS, Adam. “Applying the Unix Process Model to Web Apps”. 2009.↩︎
Google Cloud. DORA 2022 report, chapter “Technical practices and CD” , page 33. 2022.↩︎
GELLER, Anna (Prefect). “What is a Community Engineer in an Open-Source-Product Company”. 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Burnout”, page 40 .2022.↩︎
D. Kuryazov, D. Jabborov and B. Khujamuratov, “Towards Decomposing Monolithic Applications into Microservices” 2020 IEEE 14th International Conference on Application of Information and Communication Technologies (AICT), Tashkent, Uzbekistan, 2020, pp. 1-4, doi: 10.1109/AICT50176.2020.9368571.↩︎
AB Raharjo, PK Andyartha, WH Wijaya, Y. Purwananto, D. Purwitasari and N. Juniarta, “Reliability Evaluation of Microservices and Monolithic Architectures”. 2022 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 2022, pp. 1-7, doi: 10.1109/CENIM56801.2022.10037281.↩︎
An API (application programming interface) is a set of rules that allow two applications to communicate with each other.↩︎
The Horizontal Pod Autoscaling feature of Kubernetes allows you to automatically adjust the number of microservices launched accordingly user load.↩︎
Examples of FaaS technologies: GCP Cloud Functions, AWS Lambda, Azure Functions.↩︎
Example of serverless computing technologies: GCP Cloud Run, AWS Elastic Beanstalk, Azure App Service↩︎
Example of database technologies managed by Cloud hosts: AWS DynamoDB, GCP Firestore, Azure Cosmos DB, AWS S3↩︎
Example of queue technologies managed by Cloud hosts: AWS SQS, GCP Pub/Sub and Azure Service Bus↩︎
Proprietary lock-in is a situation where a supplier has created a deliberately non-standard feature in the software sold, preventing its customer from using it with another supplier’s products. This also prevents him from modifying the software or accessing its features to modify it. Source: fr.wikipedia.org.↩︎
Amazon Prime Video. Scaling up the Prime Video audio/video monitoring service and reducing costs by 90%. 2023.↩︎
FOWLER, Martin. Microservice prerequisites. 2014.↩︎
DEHGHANI, Zhamak. How to break a Monolith into Microservices. 2018.↩︎
WESTRUM, Ron. “A typology of organizational culture”, doi:10.1136/qshc.2003.009522. 2004.↩︎
Google Cloud. Developing a Google SRE Culture, module 4. coursera.org.↩︎
MALLE, Bertram; GUGLIELMO, Steve; MONROE, Andrew. A Theory of Blame. Psychological Inquiry. 25. 147-186. doi:10.1080/1047840X.2014.877340. 2014.↩︎
UK’s Royal Society for Arts, Manufactures and Commerce. Video “Brené Brown on Blame” on YouTube. 2015.↩︎
Decision making tools. Mindtools.com.↩︎
Project management tools. Mindtools.com.↩︎
CLET, Étienne; MADERS, Henri-Pierre; LEBLANC, Jérôme; GOLDFARB, Marc. The job of project manager, Éditions Eyrolles. 2013.↩︎
PIOT, Ludovic; Les Compagnons du DevOps. The DevOps System Administrator | In Aside #12, Radio DevOps, at 33 minutes and 30 seconds. 2022.↩︎
A “persona” is a fictional and detailed representation of a target user, created to help development and project management teams understand the needs, experiences, behaviors, and interests of potential customers.↩︎
“(the RCA CloudRCA tool) saves SREs +20% of the time spent on troubleshooting over the last twelve months and significantly improves service reliability.”. ZHANG, Yingying et al. “CloudRCA: A Root Cause Analysis Framework for Cloud Computing Platforms”. 2021.↩︎
Pilot tests: “type of software test verifying all or part of a system under real operating conditions (in production)”. Source: guru99.com↩︎
Google Cloud. Developing a Google SRE Culture, module 3. coursera.org.↩︎
Postmortem template to be found on atlassian.com/incident-management/postmortem/templates↩︎
Excelsior. YouTube video “Le Canap’ - Ui designer, youtuber and streamer: Basti UI launches "teletralive"”. 2022.↩︎
BERGGREN, Erik; BERNSHTEYN, Rob. “Organizational transparency drives company performance”. Journal of management development 26, no. 5 411-417. 2007.↩︎
Blog where Cloudflare publishes its postmortems: blog.cloudflare.com/tag/postmortem↩︎
STAMBLER, Kimberly S; BARBERA, Joseph A. “Engineering the Incident Command and Multiagency Coordination Systems” Journal of Homeland Security and Emergency Management 8, no. 1. 2011.↩︎
Google. Chapter “Incident Command System”, SRE Book. sre.google.↩︎
Datadog. 2023-03-08 Incident: A deep dive into our incident response. 2023.↩︎
Yann COUDERC. “Did Sun Tzu invented the nonconforming cases ? (FR)”. 2013.↩︎
US Department of Defense. “MIL-P-1629 – Procedures for performing a failure mode effect and critical analysis. Department of Defense (US). MIL-P-1629”. 1949.↩︎
STEPHEN, Elliot. “DevOps and the cost of downtime: Fortune 1000 best practice metrics quantified”, International Data Corporation (IDC). 2014.↩︎
History of the development of Windows NT: en.wikipedia.org/wiki/Windows_NT_3.1↩︎
“No-code is an approach to software development that allows you to create and deploy software without writing computer code.” Source: fr.wikipedia.org.↩︎
PAUPIER, François; CHAILLAN, Nicolas. Postmortem #19: DevSecOps at the U.S. Air Force. 2022.↩︎
SIEBEN, Inge. “Does training trigger turnover - or not?: The impact of formal training on graduates’ job search behavior. Work, Employment and Society”. 2007.↩︎
Im, GHI PAUL; Richard, L. BASKERVILLE. “A longitudinal study of information system threat categories: the enduring problem of human error.” ACM SIGMIS Database: the DATABASE for Advances in Information Systems 36.4 (2005): 68-79. 2005.↩︎
GitHub project available at links.berwick.fr/todevops-2↩︎
CUNLIFFE, Stuart. Illustration of the article “Red Hat Ansible: A 101 guide”, ibm.com/blogs . 2020.↩︎
WIGGINS, Adam. The New Heroku (Part 4 of 4): Erosion-resistance & Explicit Contracts. 2011.↩︎
Based on the book by Kent BECK. Test-Driven Development by Example. 2002.↩︎
Dogša, T., Batič, D. “The effectiveness of Test-driven development: an industrial case study”. Software Qual J 19, 643–661, doi:10.1007/s11219-011-9130-2. 2011.↩︎
TDD reduces complexity by 31% and increases code quality by 21%, compared to TLD: KHANAM, Z; AHSAN, MN. Evaluating the effectiveness of test driven development: Advantages and pitfalls. International Journal of Applied Engineering Research. 2017.↩︎
Atlassian. “What is code coverage?”. atlassian.com.↩︎
MOE, Myint Myint. “Comparative Study of Test-driven development TDD, Behavior-Driven Development BDD and Acceptance Test–Driven Development ATDD”. International Journal of Trend in Scientific Research and Development. 2019.↩︎
Scripts that analyze source code to report programming errors, bugs, stylistic errors, and suspicious code constructs. The goal of linting is to enforce a consistent code style and find potential errors before code execution.↩︎
Istio’s testing framework documentation on github.com. 2022.↩︎
SRIDHARAN, Cindy. “Distributed Systems Observability”. 2018.↩︎
ANSSI. “Security recommendations for the architecture of a logging system” version 2, Appendix D: legal and regulatory aspects. 2022.↩︎
Thanks to its service mesh, Lyft has rewritten the headers of requests that pass through its network to add or propagate tracing information.↩︎
RELP (Reliable Event Logging Protocol) is a protocol developed to ensure that an emitted log has arrived at its destination. Source: connect.ed-diamond.com.↩︎
“OpenTelemetry defines semantic conventions […] that specify common names for different types of operations and data.”. Source: opentelemetry.io.↩︎
Search Engine Optimization: Optimization techniques aimed at improving your website so that it rises in search results.↩︎
The uptime (uptime) is the time the service is on over a given period. Availability indicates whether the service is accessible and returns valid responses. For example, an API can be started (uptime) without being available to return a valid response (availability; service inaccessible, saturated or unwanted HTTP 500 errors).↩︎
Google. Chapter “Service Level Objectives”, SRE Book. sre.google.↩︎
Istio Dashboard documentation. istio.io.↩︎
Istio access logs documentation. istio.io.↩︎
Istio Distributed traces documentation. istio.io.↩︎
Weaveworks. Introduction to Kubernetes Service Mesh. 2019.↩︎
Official website of the Buoyant Linkerd project: linkerd.io.↩︎
Official website of the Hashicorp Consul project: consul.io.↩︎
Custom Resource Definition (CRD): mechanism for adding feature extensions within a Kubernetes cluster.↩︎
Helm is a technology standardizing and simplifying the deployment of applications in Kubernetes. helm.sh.↩︎
The term “Cloud Native” refers to an application that was designed from the ground up to be operated in the Cloud. Cloud Native projects involve cloud technologies such as microservices, container orchestrators, and autoscaling.↩︎
Sealed Secrets allows you to manipulate secrets without being able to access their content in plain text, allowing you to go so far as to “push” a secret. A security certificate manages the decryption of these secrets within the Kubernetes cluster. GitHub project: github.com/bitnami-labs/sealed-secrets.↩︎
GAFAM: Large American technology companies (Google, Facebook, Amazon, Apple, Microsoft). Synonyms: FAANG, NATU, MAMMA, MANAMANA.↩︎
French Interministerial Digital Department.↩︎
French National Institute of Statistics and Economic Studies.↩︎
Official project web page: 10pourcent.etalab.gouv.fr↩︎
Google begins to reimburse its Google Workspace customers below 99.9% availability. workspace.google.com/terms/sla.html.↩︎
AWS instance-level SLA. The first reimbursements start at 99.5% availability. aws.amazon.com/compute/sla.↩︎
Procter & Gamble Co. 2021 Form 10-K, chapter Property, Plant and Equipment. 2021. <+> SPINELLIS, Diomidis; LOURIDAS, Panos; KECHAGIA, Maria. Software evolution: the lifetime of fine-grained elements. 2021.↩︎
POORTVLIET, Jos. German Federal Administration relies on Nextcloud as a secure file exchange solution . 2018.↩︎
POORTVLIET, Jos. EU governments choose independence from US cloud providers with Nextcloud. 2019.↩︎
Google Cloud. DORA 2022 report, chapter “Technical DevOps Capabilities”, page 30. 2022.↩︎
Google Cloud DORA’s 4 key metrics for measuring DevOps performance.↩︎
SMITH, Dustin (DORA Research Lead). “2021 Accelerate State of DevOps report addresses burnout, team performance” . 2021.↩︎
Historical Service Level Availability: about.gitlab.com/handbook/engineering/monitoring↩︎
Video from the Platform Engineering channel on YouTube. Palantir’s GitOps Journey with Apollo, with Greg DeArment. 2022.↩︎
Palantir. Palantir Apollo Whitepaper. 2022.↩︎
Palantir Blog on medium.com. Why Traditional Approaches to Continuous Deployment Don’t Work Today. 2022.↩︎
Palantir (blog.palantir.com). “Palantir Apollo Orchestration: Constraint-Based Continuous Deployment For Modern Architectures”. 2022.↩︎
In 2021, 74% of organizations reported adopting a DevOps approach. Statistics by Redgate. “The 2021 State of Database DevOps”. 2021.↩︎
DevOps Institute. Global Upskilling IT report, chapter “Industry” (page 162). 2022.↩︎
Within the meaning of French company categories defined by INSEE. 2020.↩︎
DevOps Institute. Global Upskilling IT report, chapter “DevOps Remains a Driving Force in IT Transformation” (page 16). 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Region”, page 63 .2022.↩︎
Google Cloud. DORA 2022 report, chapter “Team size”, page 65. 2022.↩︎
KREUZBERGER, Dominik; KÜHL, Niklas; HIRSCHL, Sebastian. MLOps: Overview, Definition, and Architecture. 2022.↩︎
git is a “version control” system created in 2005, tracking modifications made to files in a project (management of file history, merging of contributions, accountability of actions). It is the most used in the world. Historical and less popular alternatives exist: Apache Subversion (SVN), Mercurial.↩︎
18 DataOps principles of The DataOps Manifesto.↩︎
CAPIZZI, Antonio; DISTEFANO, Salvatore; MAZZARA, Manuel. From DevOps to DevDataOps. 2019.↩︎
Google Cloud. DORA 2022 report, chapter “Years of experience”, page 61. 2022.↩︎
Disaster and Recovery Testing (DiRT) is a training for infrastructure teams at Google, aimed at pushing production systems to their limit and inflicting real failures. The objective is to see how the teams react and if they are correctly equipped to respond to an incident.↩︎
Supply chain Levels for Software Artifacts (SLSA, pronounced “salsa”) is a set of security rules recommended to secure its software development and deployment chain.↩︎
Presentation page of ANSSI’s “Master of digital security”. ssi.gouv.fr (“Training” tab).↩︎