
Le guide des décideurs pragmatiques pour comprendre et agir.
January 2024 - 1.1.4
Chers collègues, chers amis,
Il est de ces aventures qui ne sauraient aboutir sans la rigueur et le dévouement de quelques-uns. Vous avez été ces quelques-uns. En acceptant de lire et de relire ce manuscrit, en partageant vos critiques constructives, vos suggestions éclairées et au cours de nos échanges enrichissants, vous avez largement contribué à sa réussite.
À travers vos yeux experts, j’ai pu aiguiser chaque ligne, polir chaque mot. Votre soutien a été un pilier, une force silencieuse et indéfectible. Un grand merci pour votre temps, votre expertise et votre franche camaraderie.
C’est parce-que cet écrit est aussi en partie le votre que je souhaitais le marquer du nom des contributeurs les plus acharnés. Toutefois, dans le but de préserver votre anonymat, j’ai choisi de n’inscrire que vos initiales. Merci BA, FT, MR, FC, FP, NK, AB, AC, NP, NM, CH, EL, PB, AN et TF.
Ce livre inclut de nombreuses références et de nombreux liens Internet vers des personnes, produits, entreprises et organisations. Les opinions exprimées dans ce livre sont celles de l’auteur et ne reflètent en aucun cas les opinions des entités mentionnées.
L’auteur n’a aucune affiliation avec les entreprises mentionnées dans ce livre, que ce soit sous forme de partenariat, de parrainage ou de tout autre arrangement. Toute mention d’une entreprise ou d’un produit est strictement informative et ne doit être en aucun cas interprétée comme de la promotion.
La transparence me semble essentielle dans tout travail de recherche et d’écriture, et je souhaite que mes lecteurs soient informés de mon absence d’affiliation avec les organisations citées dans mon ouvrage.
![]()
L’incessante évolution des usages du numérique impose aux organisations de se réinventer. Elles se retrouvent contraintes de répondre toujours plus vite - et souvent sans augmentation de moyens - à leurs exigences opérationnelles. Les stratèges se mobilisent pour conserver une longueur d’avance, face à une concurrence toujours plus féroce.
De nombreuses organisations ont déjà entamé leur transformation numérique pour maîtriser la complexité de systèmes d’information interdépendants et fractionnés. Le DevOps constitue l’une des approches permettant d’atteindre cet objectif et de travailler plus efficacement.
Apparu en 2007, ce mouvement culturel et organisationnel permet aux parties prenantes d’une organisation de travailler plus efficacement pour atteindre plus rapidement ses objectifs.
Grâce à plusieurs méthodes théorisées, le DevOps constitue un moyen de répondre à cet enjeu d’efficacité. Chacune vise à améliorer la pertinence et la fiabilité des services proposés par l’organisation. Pour lui permettre d’être plus agile, le DevOps tire pleinement profit des technologies Cloud : pour la plupart ouvertes, éprouvées, normalisées et attractives.
Selon la société de conseil et de recherche Gartner, plus de 85% des organisations vont adopter une stratégie Cloud d’ici 20251. Pour l’éditeur logiciel Atlassian, 99% des entreprises questionnées estiment que le DevOps a un impact positif sur leur organisation2.
Plusieurs initiatives pour créer des plateformes Cloud souveraines prennent forme dans le monde. C’est par exemple le cas du MeghRaj en Inde (2014), le Bundescloud en Allemagne (2015), JEDI aux États-Unis (2017), Nimbus en Israel (2020), GAIA-X en Europe (2020), le Riigipilv en Estonie (2020), Outscale, Athea, et S3NS en France (2010, 2017 et 2021), le Government Cloud au Japon (2021), le National Strategic Hub en Italie (2022). Au cœur de ces infrastructures, un mode d’organisation fait l’unanimité pour unifier les pratiques et orchestrer ces technologies : le DevOps.
Plus largement employé dans le privé, les grands fournisseurs de services Cloud (Amazon Web Services, Google Cloud Platform, Microsoft Azure, Alibaba Cloud) pratiquent en interne ce mode d’organisation, le promeuvent et fournissent les technologies pour l’adopter.
La Corée du Sud favorise historiquement l’usage de technologies Cloud privées, en particulier depuis sa loi en 2015 facilitant la sous-traitance3. A cause de plusieurs investissements en doublons, de ses systèmes d’information vieillissants et du manque d’experts en cybersécurité sur son territoire, elle a su s’équiper dès 2007 de centres de données nationaux. Ils hébergent aujourd’hui les systèmes d’information de 45 agences gouvernementales4. Dès 2021 et suite à la crise du COVID-19, elle annoncera un plan de transformation numérique massif de son administration : le Digital Government Master Plan 2021-20255. Ce plan d’action fournit un cadre technique nommé “eGovFrame” utilisé pour le développement et la gestion des systèmes d’information gouvernementaux, dans l’objectif d’améliorer leur interopérabilité. Il inclut par nature des principes DevOps.
Dans une volonté de regain de souveraineté, d’autres gouvernements affichent une volonté claire d’adopter ces technologies et pratiques, sans nécessairement décrire en public leurs initiatives. Ces volontés prennent forme au sein de documents mentionnant la stratégie Cloud, IA ou data des pays.
À titre d’exemple, le Canada a publié son rapport “Objectif 2020”6 en 2013 pour moderniser la manière dont travaillent les services publics. Il publiera par la suite le “Cloud Adoption Strategy”7 en 2018.
Au Royaume-Uni, le Ministère de la Défense annonce en 2022 vouloir devenir une organisation “prête pour l’IA”, dans sa “Stratégie d’Intelligence Artificielle de Défense”8. Dans l’expression qu’elle fait de sa transformation, elle résume parfaitement les finalités du DevOps.
« Nous devons nous transformer en une organisation fortement orientée vers le logiciel, organisée et motivée à valoriser et exploiter les données, prête à tolérer des risques accrus, à apprendre par la pratique et à se réorienter rapidement pour trouver des succès et des gains d’efficacité. Nous devons être capables de développer, tester et déployer de nouveaux algorithmes plus rapidement que nos adversaires. Nous devons être agiles et intégrés (unifiés), […] » - Ministère de la Défense du Royaume-Uni, chapitre “Culture, Compétences et Politiques”, page 17.
Dès 2018, le Ministère de la Défense britannique lançait le programme NELSON9 pour s’équiper d’une plateforme big-data au profit de la Royal Navy. Cet environnement technique à base de technologies Cloud, inclut là encore des pratiques DevOps.
Outre-Atlantique, les États-Unis considéraient déjà en 2011 la nécessité de maîtriser l’information de manière unifiée et agile, accessible via un point d’accès unique (cf. chapitre “Zero trust”). Le Department of Defense (DoD) décrit cette vision dans sa “Stratégie et feuille de route des systèmes informatiques industrialisés au DoD”10.
« Les opérations militaires du XXIe siècle nécessitent un environnement informationnel agile afin d’obtenir un avantage stratégique pour les effectifs et les partenaires des missions. […] Pour relever ce défi, le DoD entreprend un effort coordonné pour unifier ses réseaux dans un environnement informatique unique qui améliorera à la fois l’efficacité opérationnelle et la posture de sécurité vis-à-vis des systèmes d’information. »
- Ministère des Armées des États-Unis, chapitre “Vision pour des systèmes d’information industriels plus efficaces et sécurisés au DoD”, page 13.
Il publiera en 2019 son premier guide de référence pour l’industrialisation des pratiques DevSecOps11 : une méthodologie mettant l’accent sur la sécurité (cf. chapitre “DevSecOps”). Destiné aux fournisseurs, acquéreurs et responsables de systèmes d’information modernes, ce guide institutionnel décrit des bonnes pratiques pour la mise en œuvre et la maintenance de ce type de systèmes. L’objectif affiché est de déployer des logiciels à la “vitesse des opérations”. Dans le milieu économique, le parallèle est celui de la “vitesse des marchés boursiers”.
Dans le privé, Microsoft lançait historiquement ses nouveaux produits tous les 3 à 4 ans (ex: Windows, Office). Dès 2014, son président-directeur général Satya NADELLA a mis en garde ses équipes sur le risque induit par la trop longue durée de ce cycle de développement. En poursuivant avec le même mode d’organisation, Microsoft allait devenir obsolète. Les équipes chargées du développement de chaque produit travaillaient indépendamment les unes des autres, avec leurs propres méthodes d’organisation et leurs propres outils. NADELLA a réorganisé l’entreprise en se basant sur la méthodologie DevOps. Il unifiera les outils et les pratiques des équipes, pour qu’elles rediscutent entre elles12.
Face à des compétiteurs économiques13 ou militaires14 toujours plus offensifs, se transformer relève d’une impérieuse nécessité pour rester dans la course et l’emporter lors des prochaines confrontations. Pour les institutions, il ne s’agit donc plus de savoir “si” mais “quand” elles devront se lancer dans une démarche de transformation, au risque de se retrouver déclassées.
Néanmoins, la majorité des organisations a encore du mal à instaurer ces nouvelles pratiques de façon pragmatique. L’obstacle principal est de trouver les talents capables de mettre en place les techniques et les outils appropriés à un fonctionnement en mode DevOps.
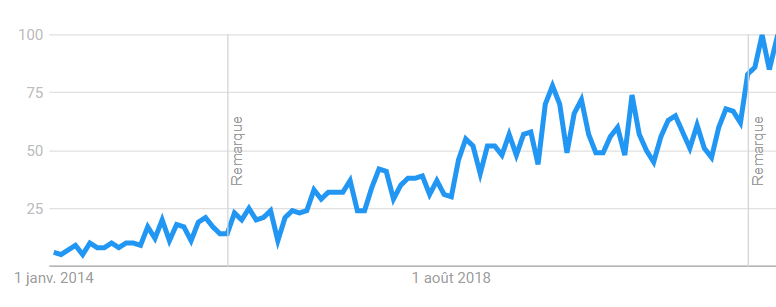
Il existe de nombreuses études auxquelles se référer sur le DevOps, qui se voit être avant tout un sujet de transformation culturelle des équipes techniques et du management. Ces études font référence à l’expérience de nombreux acteurs et nous permettent d’éviter les erreurs communes dans une démarche de transformation.
À titre d’exemple, le programme de recherche DORA15 de Google Cloud (DevOps Research & Assessment) s’est conduit depuis 2014 avec plus de 33 000 professionnels du secteur Cloud. Chaque année, son rapport sur l’état du DevOps dans le monde est publié. Ce domaine est donc loin d’être nouveau, le risque initial est maintenant beaucoup plus modéré pour les nouveaux entrants. Mais le secteur ne cesse de trouver des manières toujours plus efficaces de se transformer, pour tenir le rythme face à la cadence élevée des évolutions du secteur du numérique.
Ce livre a pour vocation de vulgariser les aspects organisationnels et techniques du DevOps. Ces notions sont accessibles à tous et vous permettront d’avoir une vue d’ensemble des enjeux du Cloud pour une transformation réussie. Il propose une ligne de conduite à tenir pour une première expérimentation DevOps, ou pour affiner une transformation déjà entammée.
Nous explorerons les raisons de l’émergence de cette méthodologie, son contenu et comment faire aspirer votre organisation à se transformer. Chaque structure a ses propres besoins, son propre niveau de maturité et il n’y a pas de recette unique. Néanmoins, les expériences successives du secteur ont abouti à la création de standards qui vous seront présentés au cours de cet ouvrage.
Aujourd’hui, l’experience engrangée par des entreprises pionnières dans le domaine permettent d’être assuré de la pertinence de ce mode d’organisation : les efforts investis sur le DevOps contribueront à faire de votre organisation une structure plus efficace, agile et perenne.
Selon la réputée entreprise américaine Atlassian16, le mouvement DevOps est né entre 2007 et 2008, à l’époque où les métiers du développement logiciel (ceux qui développent) et ceux de l’administration système (ceux qui déploient) s’inquiétaient respectivement de leur piètre capacité à collaborer. Ils considéraient cette situation comme un dysfonctionnement fatal, à cause de leur manque de proximité.
Initialement, le DevOps se concentrait sur la manière d’améliorer l’efficacité du développement et du déploiement des logiciels. Plus de dix ans plus tard, cette méthodologie a évolué et adresse désormais plusieurs autres domaines comme la sécurité, les infrastructures Cloud ou encore la culture d’entreprise. Autour de 2015, la méthodologie DevOps était principalement employée dans les grandes entreprises américaines de la technologie (GAFAM17 et NATU18) ou des entreprises employant déjà la méthodologie agile.
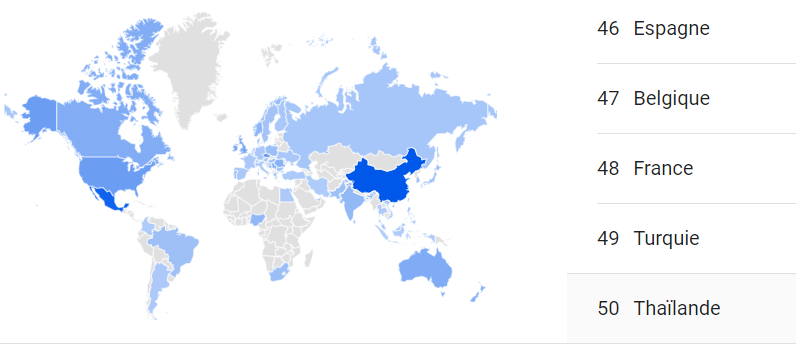
Bien répandue aujourd’hui, des organisations de toute taille utilisent la méthodologie DevOps partout dans le monde et dans tout type de secteur19 (santé, finances, transports, gouvernements, industries lourdes…).
Le terme DevOps est attribué à l’ingénieur belge Patrick DEBOIS. Consultant en 2007 pour le gouvernement belge, il lui avait été confié la migration d’un centre de données. Ayant passé un temps considérable à discuter avec les développeurs et les administrateurs système, il aura fait le constat de ce que les réputés ingénieurs Andrew CLAY SHAFER et Lee THOMPSON théoriseront deux années plus tard comme le “mur de la confusion”20. Une métaphore pouvant se résumer par des parties prenantes qui ne se comprennent pas.
La communauté mettait un mot sur un vrai phénomène qui entrave la communication et la collaboration entre les équipes, entraînant un manque d’efficacité et des retards. En suivra la rédaction de son livre en 2015 « Le manuel du DevOps : comment créer des organisations technologiques agiles, fiables et sécurisées »21. DEBOIS y décrit la manière dont les organisations peuvent augmenter leur rentabilité, améliorer leur culture d’entreprise et dépasser leurs objectifs grâce aux pratiques DevOps.
Google théorise cinq piliers du DevOps :
Pour bien comprendre en quoi le DevOps peut aider votre organisation, commençons par définir deux des termes les plus importants à connaître dans le domaine : le DevOps et la SRE.
C’est le lien qui unit le monde du développement et de la production.
« Dev » signifie « développement » quand « Ops » désigne l’administration des systèmes informatiques en production.
On qualifie de « DevOps » (Development and Operations) le mouvement organisationnel et culturel qui a pour but de fluidifier le cycle de développement et de déploiement logiciel.
Pour atteindre cet objectif, les ingénieurs pratiquant le DevOps ont pour mission de faciliter la communication et la collaboration entre les parties prenantes (développeurs, administrateurs système, équipes de sécurité, responsables projet et utilisateurs).
Ils définissent les pratiques et outils informatiques les plus pertinents pour une organisation et étudient leur mise en place. En équipe, ils garantissent la cohérence des développements avec les exigences du déploiement. Aujourd’hui, ces profils s’orientent principalement vers l’emploi des technologies Cloud.
Les pratiques DevOps s’inscrivent dans l’ensemble du panorama de la chaîne technique, en privilégiant l’usage de mécanismes automatisés pour le développement (cf. intégration continue), le déploiement (cf. déploiement continu) et la maintenance (cf. supervision). Les bénéficiaires sont à la fois les équipes internes et les clients. Les premiers collaborent plus efficacement et de manière sécurisée, tandis que les seconds obtiennent plus rapidement un logiciel de meilleure qualité.
Ce poste implique la responsabilité d’accorder toutes les parties prenantes sur une méthode de travail commune. Il est donc important de disposer d’excellentes compétences en communication et en pédagogie, en particulier dans les organisations en transformation.
L’ingénierie DevOps a pour rôle de sensibiliser l’ensemble de l’organisation aux problématiques de fiabilités des systèmes. Les ingénieurs les plus expérimentés arrivent à mettre en place les pratiques qui remplissent les exigences de résilience sans impacter la vélocité des développements.
L’enjeu principal réside dans la capacité à trouver un équilibre entre la complexité induite par les exigences de fiabilité et de sécurité, et le besoin de développer des nouvelles fonctionnalités.
Dans la suite de cet ouvrage, nous verrons que la mise en place du DevOps est propre à chaque organisation. Pour parvenir à ces objectifs, les méthodes et les outils s’adaptent en fonction du niveau de maturité technique de l’organisation. Il n’y a donc pas de “recette unique” mais des “bonnes pratiques” à connaître et suivre.
Tout comme il n’existe pas de recette unique, il n’existe pas de métier unique “d’ingénieur DevOps”. Nous évoquerons ce sujet dans le chapitre “Entre SRE et DevOps”.
Si le terme DevOps devient de plus en plus populaire et commence à devenir courant dans les offres d’emploi, celui de Site Reliability Engineering (SRE) est moins connu, en particulier en France.
L’ingénierie de la fiabilité des systèmes (Site Reliability Engineering ou SRE) est une discipline plus ancienne que le DevOps. Elle remonte à 2003 quand Ben TREYNOR SLOSS, alors ingénieur chez Google, fondait une équipe portant ce nom. Il sera le père fondateur de la SRE et des premières pratiques considérées “DevOps”.
Le Site Reliability Engineer ou “Ingénieur de la Fiabilité des Systèmes” a la charge de concevoir, déployer et maintenir l’infrastructure qui met à disposition les services de l’entreprise. Il s’assure du bon fonctionnement du socle technique sur lequel sont déployés les logiciels. Il en assure leur sécurité et garantit leur disponibilité auprès des clients.
L’équipe SRE a donc la responsabilité de votre infrastructure informatique, souvent composée de plusieurs environnements : développement, qualification, pré-production (ou staging) et production. Elle tente de répondre à la question “quelles sont les choses (outils, procédures, machines) que nous n’avons pas, et dont nous avons besoin pour atteindre notre objectif de résilience ?”.
Les SRE utilisent les pratiques du monde de l’ingénierie logicielle pour administrer leurs infrastructures. Ils développent et déploient l’outillage permettant d’atteindre un objectif de résilience. En ce sens, la SRE intègre de nombreux aspects du DevOps (cf. chapitre “Les 5 piliers du DevOps”) mais se concentre sur l’automatisation de l’administration, ainsi que sur la mesure de la fiabilité des systèmes.
L’entreprise les emploient principalement pour honorer son contrat de service (Service Level Agreement, cf. chapitre “Indicateurs de résilience”). Dans le secteur privé, si la disponibilité du service tombe sous la valeur stipulée dans le contrat (ex: sous les 99% de disponibilité mensuelle), l’entreprise est tenue de régler des pénalités.
De manière simplifiée, l’entreprise donne pour mission au SRE de rendre son infrastructure plus résiliente. C’est à dire toujours plus disponible, plus stable. Le SRE tente de répondre à la question suivante : “quelles sont les choses (outils, procédures, machines) que nous n’avons pas, et dont nous avons besoin pour atteindre notre objectif de résilience ?”.
Les pratiques DevOps sont un excellent moyen d’atteindre cet objectif. Voilà pourquoi les SREs les utilisent souvent au quotidien.
Les définitions diffèrent selon les interlocuteurs. Alors que certains leaders comme Google et AWS définissent officiellement le DevOps comme une “méthodologie” et le métier de SRE comme sa “mise en œuvre”22, la majorité des offres d’emploi du marché restent souvent titrées “Ingénieur DevOps” : un titre incomplet au sens propre de la définition historique.
Le fait est que les deux disciplines ont évolué et se chevauchent aujourd’hui sur de nombreux aspects : elles partagent l’objectif de déployer rapidement des logiciels fiables et efficaces.
Cependant elles ne se concentrent pas totalement sur les mêmes choses. Tandis que le DevOps est davantage axé vers l’efficacité du développement et la rapidité du déploiement (cf. CI/CD, tests automatisés, expérience développeur, collaboration interéquipes…), la SRE se concentre sur la fiabilité des systèmes en employant une approche plus méthodique (cf. SLI/SLO/SLA, budget d’erreur, déploiements blue/green, postmortems…).
Aujourd’hui, vous pouvez donc trouver des “Ingénieurs DevOps” qui ne font pas de SRE mais l’inverse reste rare. Le DevOps étant une philosophie, ce terme est à employer comme un adjectif. Par exemple : “Ingénieur logiciel DevOps” ou “Administrateur système DevOps”.
Regardons néanmoins ce qu’en dit le marché. En observant les offres d’emploi dans le domaine23, on remarque que celles titrées “Ingénieur DevOps” comportent des missions très variées. Elles peuvent être :
En réalité, tous ces rôles permettent de mettre en pratique le DevOps. Mais l’existence de chacun au sein d’une structure dépend de sa maturité et de ses moyens (fig.
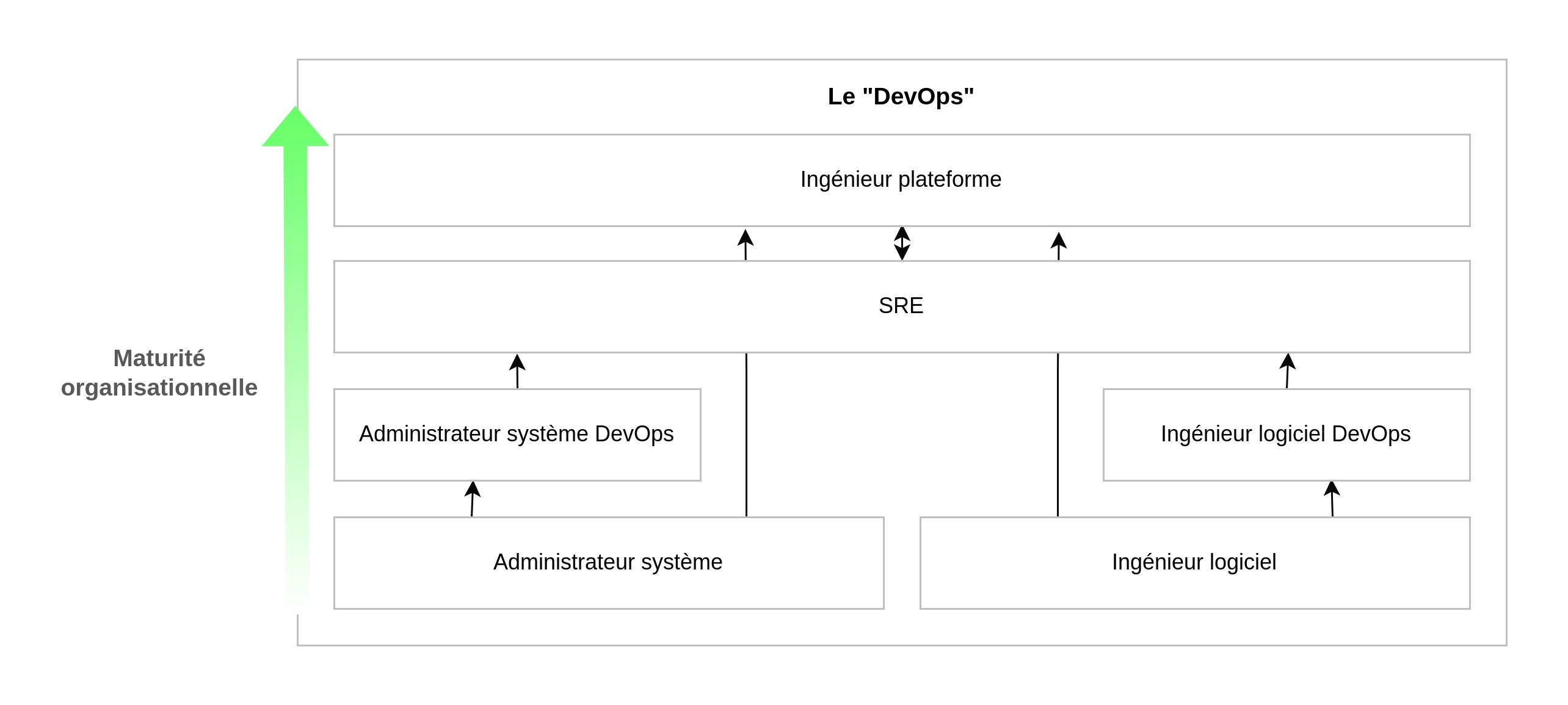
En résumé, on dit que la SRE utilise les méthodes DevOps25. Le DevOps et la SRE ne sont donc ni deux méthodes qui s’opposent, ni deux méthodes identiques, mais deux disciplines qui vous aideront à faire tomber les barrières entre vos équipes. Vous pourrez ainsi déployer plus rapidement et de manière plus sécurisée des services de meilleure qualité.
Vous découvrirez dans ce livre les meilleures pratiques de ces deux disciplines unifiées, décrites de manière adaptée aux institutions.
Le terme DevSecOps gagne en popularité. Il qualifie un mode d’organisation DevOps intégrant les équipes de Sécurité des Systèmes d’Information (SSI) dès la phase de conception du logiciel et tout au long de son cycle de vie.
Plus concrètement, il s’agit de garantir le respect des standards de sécurité imposés par l’organisation, au moyen de règles automatisées qui vérifient la conformité des logiciels développés.
Peut-être avez-vous déjà entendu parler de “shift left security” ? Cette expression évoque le fait d’intégrer au plus tôt les travaux de sécurité dans le projet logiciel (bonnes pratiques, analyses de vulnérabilités, audits).

En terme organisationnel, cette méthode implique les équipes SSI au cœur des échanges entre les développeurs et les équipes de production. Ces équipes auront la charge d’appuyer les développeurs pour qu’ils puissent intégrer le plus facilement possible les exigences de sécurité de l’organisation à leurs logiciels.
Dès la phase de conception, les équipes SSI DevSecOps définissent et fournissent les outils contrôlant l’existence des fonctionnalités de confidentialité et de sécurité dans les logiciels. Par exemple, elles vérifieront l’existence des fonctionnalités RGPD26 dans un logiciel, ou le bon fonctionnement du mécanisme de “besoin d’en connaître” pour l’accès aux données. Cela peut aussi inclure la mise en place de détecteurs automatiques de vulnérabilités dans le code.
Nicolas CHAILLAN, ancien Directeur de l’Ingénierie Logicielle au sein de l’United States Air Force (USAF) le définit27 de manière plus générale avec les termes suivants :
« Le DevSecOps est l’évolution de l’ingénierie logicielle. C’est l’équilibre entre la vélocité de développement et le temps alloué aux considérations de sécurité. On veut que la sécurité soit intégrée pour être sûr qu’elle ne soit pas oubliée mais ajoutée au cycle de développement logiciel. C’est utiliser les procédés de cybersécurité modernes pour être sûr que le logiciel est à la fois performant et construit d’une manière sécurisée pour être sûr qu’il n’ait pas de problème au fil du temps. C’est ce qui va permettre aux sociétés et organisations de rester concurrentielles et d’avancer à l’avenir à la vitesse nécessaire face à leurs concurrents. »
Aujourd’hui, le terme “DevSecOps” est régulièrement favorisé dans le seul objectif de rendre plus attrayant la discipline. Cependant, il peut permettre de mieux faire comprendre aux équipes de Sécurité des Systèmes d’Information (SSI) et leurs responsables qu’elles ont un rôle concret à jouer dans ce type d’organisation. Il s’agit du “Sec” au centre du terme “DevSecOps”.
Mot de l’auteur : je considère la sécurité comme inhérente à tout système d’information et je vois donc le “Sec” de “DevSecOps” comme implicite. Voilà pourquoi je n’emploierai que rarement ce terme au cours de cet ouvrage.
Nous aborderons le paradigme de ce mode d’organisation et ses techniques de sécurité dans le chapitre “Sécurité : un nouveau paradigme avec l’approche DevOps”. Mais avant cela, apprenons-en plus sur les enjeux organisationnels du DevOps.
Une initiative DevOps est une transformation importante à l’échelle d’une organisation. Si cette dernière n’est pas encore passée au mode agile, elle implique toutes les strates de l’entreprise afin de fédérer des synergies communes.
Le DevOps ne rapproche pas que les “Dev” (ingénieurs-développeurs) et les “Ops” (administrateurs système), mais avant tout le management des équipes techniques. Ce dernier doit être aidé pour saisir les perspectives qu’offrent un changement souvent vécu comme difficile, car inconnu. Dans la plupart des cas, cette transformation nécessite une évolution significative des systèmes informatiques de l’organisation à terme, car elle implique l’usage de nouveaux outils.
L’empathie est l’aptitude clé pour réussir une transformation. Pour certains, ces nouvelles méthodes de travail et ces outils constituent un modèle opposé à leurs pratiques traditionnelles.
Voilà pourquoi il est important d’acculturer aussi souvent que possible sa hiérarchie à l’intérêt de passer en mode DevOps : lui faire des démonstrations, répondre à ses moindres questions et l’accompagner jusqu’à ce qu’elle en comprenne bien les enjeux.
Toute organisation a intérêt de savoir adresser les nouveaux défis technologiques. Face à une concurrence toujours plus moderne et rapide, votre structure ne dominera pas en restant sur ses acquis.
Des rapports de recherche appuient la théorie selon laquelle les bénéfices des efforts investis en SRE se révêlent sur le moyen-terme28.
Selon eux, pratiquer la SRE n’affecte pas la résilience de l’entreprise avant d’avoir acquis un certain niveau de maturité. C’est à dire qu’il est nécessaire d’atteindre une masse critique, avant d’être en mesure de tirer les bénéfices de ces outils et ces pratiques (fig.

Le rapport DORA 2022 fait constat du besoin d’adopter une quantité substantielle de pratiques SRE avant d’en récolter des bénéfices “significatifs” en terme de résilience29. Ce phénomène peut être un frein pour les décideurs, à l’idée de se transformer en mode DevOps.
Là où l’intérêt se confirme, c’est que les bénéfices engendrés par le DevOps dépassent les coûts engendrés une fois les investissements initiaux conscentis.
C’est bien dans cette tendance que le DevOps trouve tout son intérêt : quand bien même les infrastructures traditionnelles ne nécessitent initialement que peu d’investissement pour rendre un service, le coût (RH, financier) de leur maintenance augmente proportionnellement au nombre de services déployés. Cela rend leur gestion insoutenable à long terme. Le DevOps lui, propose un investissement initial supérieur mais offre la possibilité de maîtriser une activité exponentielle, avec un coût à tendance logarithmique (fig.
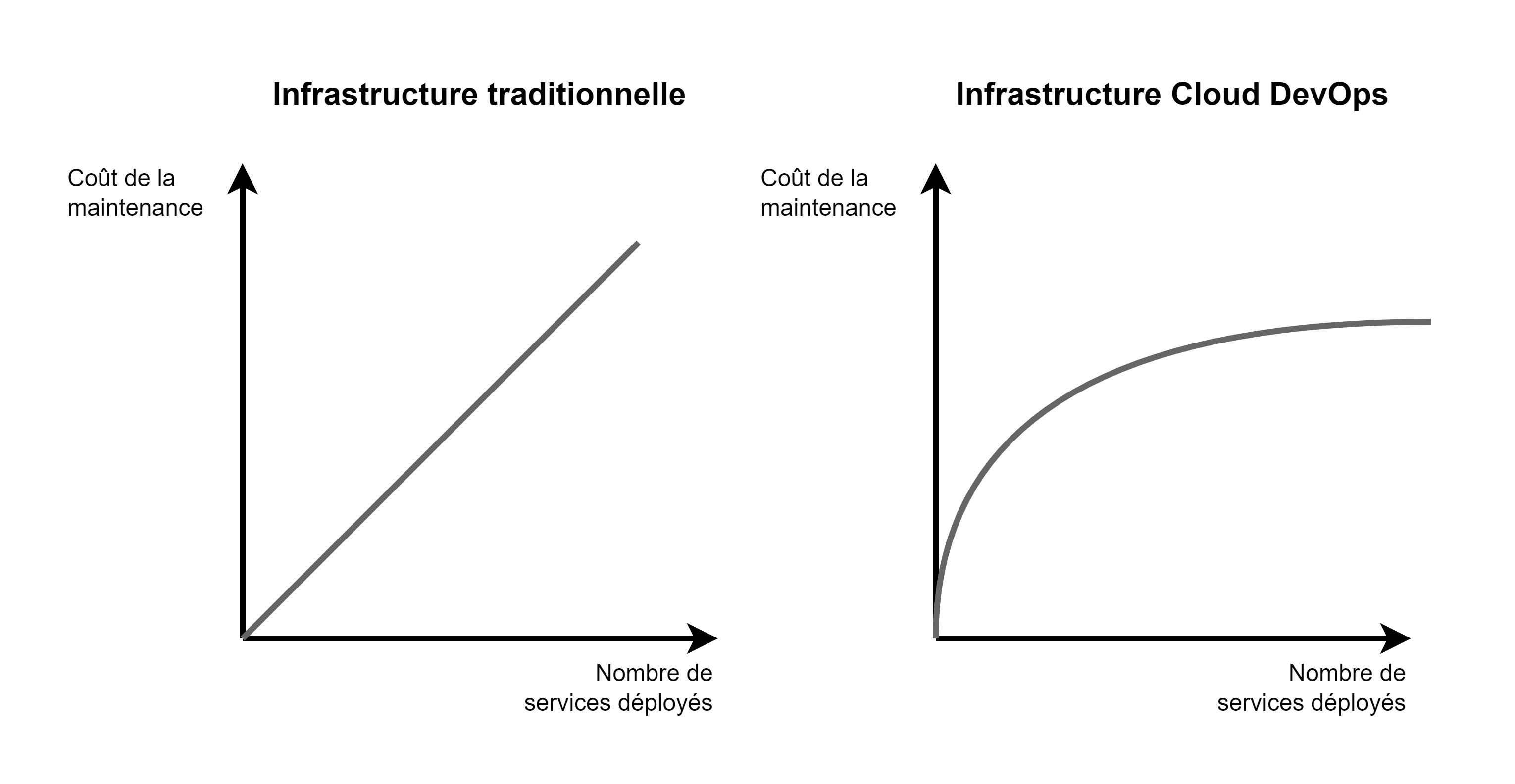
Ce mode d’organisation vise à rendre les infrastructures plus fiables, réduire les tâches manuelles pour tirer meilleur parti du temps de ses ingénieurs, déployer plus rapidement vos logiciels et in fine, rendre un service de meilleur qualité.
Le DevOps est aux infrastructures traditionnelles ce que la construction à la chaîne est à l’artisanat : en construisant à la chaîne, on réduit les coûts et on répond à la demande. L’avantage supplémentaire dans le domaine logiciel est qu’il est possible d’ajuster en quelques heures le produit que l’on souhaite livrer. Cette action peut être réitérée plusieurs fois par jour !
Si les pratiques historiques ont le mérite d’avoir permis de faire fonctionner des systèmes d’informations pendant des années, d’autres méthodes plus agiles existent aujourd’hui30. Pour militariser le propos : les arcs et les flèches ont servi, mais depuis les armées ont inventé l’AR-1531.
Tout l’enjeu d’une transformation est de réussir à faire adhérer votre hiérarchie à cet investissement initial (non-négligeable mais nécessaire), alors que les bénéfices peuvent être au départ difficiles à voir émerger. C’est un défi courant que nous verrons comment adresser dans le chapitre “Comment convaincre et garder la foi”.
Les entreprises sont généralement conscientes du changement qu’elles doivent opérer. Mais elles n’osent ou ne peuvent pas immédiatement consentir aux efforts nécessaires pour réaliser cette transformation.
Les plus sceptiques ou les plus optimistes pensent même s’en sortir en démarrant une initiative à moindre frais :
« Je n’ai besoin que d’un ingénieur SRE/Cloud/DevOps »
Navré, non.
Prenons un exemple pour illustrer ce scénario. Vous commencez avec une équipe de 2 personnes qui développent un logiciel. Plusieurs problèmes sont d’ores-et-déjà identifiés, en particulier si vous travaillez dans un secteur réglementé :
Si vous ne comptez que sur vos ingénieurs logiciels pour gérer l’infrastructure, ils finiront par générer de la dette technique puisque ce n’est pas leur métier. Cette dette représente des coûts et des efforts en maintenance, qui empireront à mesure que votre équipe croît. Les développeurs ne se concentreront pas sur le développement et s’éparpilleront sur des tâches incombant au SRE. Cette situation nécessite déjà au moins 1 ingénieur SRE/DevOps.
Et si vous recrutiez et que votre équipe comptais désormais 6 ingénieurs ? Il faut à présent leur fournir des machines et les configurer. Certains rencontrent des bugs, d’autres vous demandent de mettre à jour des librairies… Si en plus vous avez des impératifs en termes de sécurité (ex : homologation, journaux d’évènements), il faut prendre le temps de correctement configurer les outils et l’infrastructure. Cela demande au moins 1 ingénieur SRE/DevOps supplémentaire.
Deux ingénieurs quittent maintenant votre structure ? Vous devez hélas toujours maintenir l’infrastructure qui a évolué, pour répondre aux besoins de vos 4 ingénieurs et pour maintenir les X machines ou serveurs que vous avez installés.
Comprenez que vous devez atteindre une masse critique de profils SRE/DevOps pour maintenir un socle robuste. Ce dernier constitue les fondations permettant à vos ingénieurs d’être outillés pour travailler correctement. Cette masse critique doit évoluer en fonction du nombre de collaborateurs et vous ne pouvez pas en retirer sans essuyer de lourdes difficultés d’exploitation.
Nous en revenons souvent au débat “faut-il de la qualité ou de la quantité ?”. L’histoire des conflits armés dans le monde démontre qu’il faut souvent les deux32. Les armées doivent s’équiper d’une masse critique de soldats et de matériel pour imposer des rapports de force favorables, et compenser les pertes pour continuer à avancer. Bien qu’un matériel de qualité puisse en faire davantage, il ne pourra pas tout faire en même temps. C’est la même chose pour une équipe d’ingénieurs. Aussi brillants soient-ils, il faut une masse critique pour répondre au besoin initial d’un service efficace et résilient.
Par exemple, Google - employant plusieurs dizaines de milliers d’ingénieurs - maintient son ratio de SRE vis-à-vis des développeurs à environ 10%33. Ce ratio SRE/développeurs et les coûts engendrés tendent à être élevés au début de votre initiative, puis se lissent à mesure que le nombre de services déployés croit. Cela est dû aux forts besoins en infrastructure lors de la constitution de votre initiative, qui réduisent à mesure les tâches d’administration soient automatisées.
Il est avéré que transformer une structure traditionnelle en mode DevOps demande un investissement substantiel. Mettre en place le socle permettant d’en voir les avantages prend également un certain temps. Mais gardez en tête que l’intérêt des pratiques DevOps est de réussir à maîtriser une activité exponentielle avec un coût à tendance logarithmique (cf. chapitre “Pourquoi le DevOps ?”).
L’échec d’un projet s’explique souvent par une mauvaise définition de son périmètre, avec des objectifs trop exigeants ou une planification confuse. De cette mauvaise gestion découle une augmentation des délais et des coûts de manière incontrôlée. Il est alors courant de devoir trouver une « solution intermédiaire » en attendant que la première vienne hypothétiquement au jour.
Une initiative DevOps se bâtit avec l’existant au sein de votre institution : il faut réussir à commencer petit pour correctement saisir les besoins des métiers et embarquer toute l’organisation dans l’aventure. C’est la méthode Kaizen, née au Japon dans les années 50 au sein des usines Toyota. Elle est connue en France sous le nom de “stratégie des petits pas”.
Ayez l’audace de commencer petit et d’itérer à mesure que vous et votre institution vous acculturez aux enjeux et défis de ces nouvelles technologies. Veillez à ce que chaque équipe soit à son tour évangélisatrice de votre initiative. Nous aborderons les théories derrière cette préconisation dans le chapitre “Comment convaincre et garder la foi”.
Changer la culture d’une organisation prend du temps, mais prendre des raccourcis risquera de heurter les sensibilités, démotiver vos équipes et in fine, de faire échouer votre projet. Le DevOps étant basé sur le principe d’itérations successives, vous prendrez moins de risques.
Votre hiérarchie est convaincue par votre initiative de transformation et vous accorde tous les moyens requis ? Dans ce cas, passez au prochain chapitre. Si ce n’est pas le cas, tentons de mieux comprendre pourquoi.
Il peut arriver que des décideurs nouvellement affectés, demandent à leurs subordonnés de trouver “rapidement” des solutions clef-en-main aux problèmes qu’ils découvrent. Au lieu d’adopter une démarche investigatrice, l’urgence d’obtenir un résultat immédiat les incite à prendre une orientation précipitée. Après tout, on attend du chef qu’il trouve rapidement et en toute situation une solution peu coûteuse et efficace. La plupart du temps néanmoins, des initiatives - plus ou moins matures - existent déjà au sein de l’organisation.
Les solutions techniques sont faciles à concevoir et à déléguer. Plutôt que de prendre en compte les propositions historiques, acheter des technologies “sur l’étagère” ou lancer un tout nouveau projet peut sembler plus efficace. Mais opter pour une solution, en faisant fi des contraintes inhérentes à l’organisation (maturité organisationnelle et technique, ressources humaines et matérielles, dette technique, courbe d’apprentissage…) peut être risqué.
D’ailleurs, ces contraintes sont souvent déjà connues et exprimées depuis des années par l’expertise interne. Elles provoquent la naissance de projets pris à l’initiative des employés, face au besoin qu’ils observent ou à l’exaspération qu’ils éprouvent. Au lieu de les encourager à trouver une solution, ils sont souvent réprimandés, au titre d’insubordination. En réalité, ces projets se perdent souvent dans les strates intermédiaires et ne remontant que rarement jusqu’au décideur qui a le pouvoir de les pérenniser.
En effet, les décideurs ont rarement le temps de rencontrer chacune de leurs équipes. Ils ont par conséquent tendance à privilégier leur propre avis ou à solliciter celui de leur adjoint, en lieu et place de celui de leurs experts. La décision prise est donc celle relevant de la sensibilité d’une seule personne, isolée des réalités métiers. Plus il existe de strates hiérarchiques, plus l’isolation est prononcée. Ce phénomène résulte en une concentration des efforts vers des projets peu étudiés et peu fédérateurs. Accompagnés d’une communication par nature peu impactante, il produit inévitablement de la frustration dans l’entreprise.
L’exemple de l’U.S. Department of Defense (DoD) en est une bonne illustration. Ce ministère a lancé une nouvelle initiative DevSecOps nommée Vulcan34 4 ans après l’initiative Platform One35, dont la finalité était identique. Au delà d’avoir provoqué des frustrations au sein des équipes de Platform One36, le programme Vulcan accuse des retards et des surcoûts37.
Dans d’autres cas, la méfiance de certains responsables les mènent à remettre en doute les propositions faites par leurs experts internes. À outrance, cet état d’esprit balaye l’intérêt d’embaucher des experts en contact quotidien avec les sujets de l’entreprise. L’expert externe (ex: une société de conseil, une autorité tierce) apparaît alors indispensable, considéré comme objectif et impartial38.
Face à des responsables n’ayant pas une vision alignée avec la notre, on peut s’indigner et partir. Ou essayer de comprendre les réactions et d’améliorer les pratiques. En tant que meneur d’une initiative interne, vous devez comprendre la crainte des décideurs : confier un projet ambitieux transcendant les pratiques organisationnelles a plusieurs risques.
Si votre organisation est grande et qu’elle existe depuis longtemps, c’est qu’elle a jusqu’à présent répondu à un besoin. Si les responsables en viennent à penser qu’elle doit se transformer (ou si vous l’anticipez) et que rien n’a été entamé, l’organisation se trouve peut-être face au dilemme de l’innovateur.
Théorisé par Clayton M. CHRISTENSEN39 en 1997, ce dilemme décrit la situation dans laquelle une entreprise pionnière, en essayant de maintenir son avantage concurrentiel, est inévitablement amenée à passer à côté d’une innovation majeure. Un concurrent insoupçonné la propose alors et renverse les parts de marché. Par exemple en 2023, Microsoft a surpris tout le monde en sortant avant Google un ChatGPT intégré à son moteur de recherche. Google est pourtant à ce moment le pionnier de la recherche sur internet et investit chaque année des milliards d’euros dans la recherche en intelligence artificielle. Comment est-ce que Google a pu laisser un concurrent lui damer le pion ?
La réponse est simple : le risque qu’a Google - 84% des parts de marché sur les moteurs de recherche40 - à sortir un produit non abouti - qui retourne de fausses informations par exemple41 - est bien plus important que celui d’une startup comme OpenAI ou de Bing pour Microsoft - 9% des parts de marché sur les moteurs de recherche. Preuve en est qu’au moment de la rédaction de ce chapitre, peu d’articles en ligne remettent en cause le lancement de Bing Chat par rapport à Bard, malgré des problèmes identiques42. En résumé : Microsoft a tout à gagner quand Google a tout à perdre.
Ceci dit, Google a perçu les écueils d’une absence de prise de risque et travaille depuis un moment sur un concurrent, Bard43. Pour éviter de se retrouver devant ce dilemme, l’organisation doit :
Plus pragmatiquement, si vous décidez de monter votre propre équipe, il se peut que certains membres quittent votre structure à tout instant. Au vu de la maturité des réflexions qu’ils entreprenaient, ils risquent alors de laisser derrière eux un travail fastidieux à reprendre. Voilà pourquoi beaucoup d’organisations préfèrent faire appel à une tierce partie, avec un cahier des charges bien définit pour que le décideur soit certain d’obtenir un résultat (au travers de l’obligation contractuelle de la tierce partie). Nous verrons dans le chapitre “Être au plus proche du métier” que cette pratique peut avoir des conséquences néfastes à long terme pour l’organisation.
Les évolutions organisationnelles impliquent toujours un changement culturel qu’il faut savoir appréhender. Ce fossé culturel est parfois trop difficile à surmonter pour l’organisation toute entière et cela indique qu’il est probablement encore trop tôt pour exposer votre plan. Acculturez-la au moyen de présentations et d’exemples de réussites. Le décideur doit comprendre clairement l’impact que peut avoir cette transformation et les risques associés : rupture de service, changement de stratégie RH, formation du personnel ou encore achat de matériel. Aidez vos responsables à se projeter pendant que vous travaillez à construire vos preuves.
Nous verrons dans la suite de ce livre comment appréhender la psychologie du changement pour faire aboutir votre projet.
« Une de plus ! » s’exclameront vos plus fidèles collaborateurs. Combien de réorganisations a déjà subi votre structure ? Pratiquées à outrance, elles brouillent le message et alimentent la confusion pour vos équipes.
Dans la plupart des cas, des équipes techniques existent déjà au sein de votre structure. Elles répondent déjà à des besoins métier qui nécessitent leur présence.
Les responsables ayant une connaissance limitée des enjeux métiers et techniques sont souvent tentés de vouloir changer les activités de certaines équipes. Ils le font au profit d’un nouveau projet, en raison des compétences y étant actuellement présentes. Or, une équipe se constitue toujours autour d’un projet qui a su former sa culture, et qui aujourd’hui la rend si performante pour l’entreprise. Les décideurs doivent considérer cet aspect avant d’envisager de rompre cette culture durement acquise, en imposant une transformation.
Le risque de changer considérablement les missions d’une équipe implique que vous soyez particulièrement disposé à la soutenir : c’est rarement le cas, vous n’en avez probablement pas le temps. Leur méthode de fonctionnement actuelle est déjà le fruit de plusieurs restructurations, qui ont probablement déjà impacté leurs idéaux, ainsi que la raison qu’ils ont eu de rejoindre votre organisation.
Changer les missions d’une équipe sans considérer sa culture et son passif revient à risquer de perdre des collaborateurs : soit ils seront démotivés par votre projet, soit ils démissionneront. Vous devez leur proposer une vision claire, les convaincre avec des arguments étayés mais surtout les impliquer.
Du fait de leur passif au sein de votre structure, la connaissances de vos équipes vous permettra de saisir des notions que vous n’avez pas encore totalement bien appréhendées. Soyez ouvert à leurs recommandations et leurs remarques pour comprendre en quoi réorganiser au mieux cette équipe - et seulement si nécessaire - en fonction de ses aspirations. Un excellent moyen d’obtenir l’adhésion de son équipe et de mieux comprendre ses enjeux est d’effectuer pendant quelques jours son travail. Cela peut se faire au moment de l’arrivée du décideur dans la structure.
Si vous estimez ne pas avoir les ressources en interne, ne craignez pas de recruter. Il est risqué d’impacter les équipes historiques si elles répondent à un besoin exprimé par votre organisation. Le propre d’une transformation est d’assurer la continuité du service tout en changeant ses pratiques.
Soyez plus subtil que d’annoncer un “grand plan de transformation”. Ces pratiques frustrent à coup sûr bon nombre de collaborateurs, ne permet pas d’obtenir l’adhésion de toutes vos équipes et risque de vous décrédibiliser. Elles peuvent également vous rendre otage de votre prédécesseur en associant votre personne aux précédentes transformations ayant échoué.
Comme évoqué dans le chapitre “Too big, too soon”, adoptez la stratégie des petits pas et développez progressivement votre intuition sur qui vous devez réorganiser. Obtenez l’adhésion des équipes, en illustrant le champs des possibles pour leur donner envie. Puis laissez-les convaincre leurs pairs à votre place. Nous détaillerons ces stratégies dans le chapitre “Comment convaincre et garder la foi”.
« C’est normal, nous aurons toujours du retard ici. »
Si vous avez l’impression d’avoir déjà entendu cela, ces paroles ont probablement suscité chez vous un sentiment de consternement.
Il est compréhensif d’accumuler des retards selon la taille, les moyens et les exigences de sécurité de son entreprise. Mais l’organisation ne doit pas tolérer un retard. En aucun cas l’affirmation “c’est normal ici” ne doit devenir une réponse acceptable.
Si le locuteur est sincère, cet état d’esprit ne résulte que d’un manque de connaissance sur les moyens d’atteindre l’objectif. Dans le cas contraire, il peut s’agir d’un manque de courage, voire de paresse intellectuelle.
Si la majorité des collaborateurs d’une entreprise en viennent à penser qu’elle a du retard, il y a un sérieux problème. Maintenir le statu quo sur cette situation mène inévitablement au déclin de l’organisation et en la perte irrémédiable de crédibilité, de la part de ses employés et de ses partenaires.
Dans l’un de ses articles44, le conférencier et expert en transformation Philippe SILBERZAHN prend l’exemple d’un homme qui attend son train prévu à 9h30. L’écran affiche “A l’heure” bien qu’il soit déjà 9h35 à sa montre. L’homme songe à prendre en photo le panneau mais se demande “à quoi bon”. De nombreux observateurs minimiseraient cet écart de cinq minutes, montreraient de l’irritation ou attribueraient simplement la faute à un dysfonctionnement de l’affichage. “Après tout, personne n’y peut rien”, concluraient-ils. C’est avec ce genre de comportement que Philippe SILBERZAHN affirme que les organisations déclinent : elles s’habituent à la médiocrité.
Alors qu’au début le dysfonctionnement est considéré inadmissible, il devient avec le temps de plus en plus acceptable par l’organisation, sans qu’elle se rende compte que cette situation lui coûte du temps et de l’argent. L’effort pour corriger le problème devient de moins en moins justifiable et le silence devient le choix par défaut pour conserver son énergie. Jusqu’à ce qu’une situation irrémédiable se produise (ou qu’un groupe de quelques courageux secouent la structure!).
Mais il faut également savoir quand dévoiler ses innovations. Preston DUNLAP, premier directeur technique (CTO) de l’USAF, décrit dans sa lettre publique Défier la Gravité combien les “forces bureaucratiques” peuvent nuire à l’innovation si on la présente trop tôt.
« Certains m’ont demandé quelle fut ma recette pour réussir durant ces 3 dernières années. Je n’en ai pas beaucoup parlé parce-que je savais que si je révélais les éléments trop à l’avance, les forces naturelles de la bureaucratie reviendraient de plus belle, pour rejeter à chaque occasion tout le potentiel de l’innovation. » - Preston DUNLAP, Défier la Gravité (Defying Gravity) 45
Pour éviter le retard technologique, les dirigeants d’une organisation peuvent adopter plusieurs pratiques :
Avoir conçu le meilleur des services (une méthode, un logiciel, un outil) ne vous permettra pas d’aider votre organisation tant que vous n’y donnerez pas facilement accès, sans interruption de service et en fournissant du soutien. Le DevOps vous permettra de structurer et maintenir cette source de valeur.
Ce livre n’exigera même pas de votre équipe qu’elle soit particulièrement grande, ni même que vos responsables soient déjà convaincus. Néanmoins il exigera que votre équipe, elle, soit convaincue qu’elle peut porter son projet. Bien entendu, avec le temps, l’appui d’autres équipes dans votre organisation constituera un argument précieux pour illustrer le succès de votre initiative.
Un responsable ne demande qu’à être convaincu par une initiative de ses subordonnés. Aidez-le à se projeter et à comprendre la plus-value de ce que vous lui proposez.
Cela vous demandera de présenter régulièrement l’avancée de votre projet : à la fois pour qu’il se souvienne et pour qu’il comprenne. Il est toujours risqué d’estimer qu’un projet est compris dès la première présentation, surtout quand il s’agit d’un nouveau paradigme que l’on souhaite introduire.
Projetez de monter une équipe interne : il y aura toujours des bugs à résoudre, des configurations à adapter et des fonctionnalités à ajouter. Développées en interne ou par un prestataire, vous subirez le phénomène d’érosion des logiciels46. Ce dernier qualifie les problèmes qu’un logiciel peut subir au cours du temps quand il est laissé à l’abandon (mises à jour de sécurité critiques, espace disque plein, processus qui cessent de fonctionner…).
Ne croyez pas qu’un prestataire pourra résoudre tous vos problèmes : vous perdrez de l’argent et vous n’atteindrez pas vos objectifs. Le résultat d’un prestataire ne sera que le produit de votre capacité à synthétiser vos problématiques. Or dans une phase de transformation, vous allez prendre connaissance de nouveaux enjeux chaque semaine. Contrairement à vous et votre équipe, le prestataire ne connaît pas nécessairement l’histoire de votre organisation, et ne pourra probablement pas être présent en permanence en son sein pour capter tous les enjeux des parties prenantes.
Amorcer son initiative DevOps demande de se projeter dans le recrutement de plusieurs profils :
Que vous soyez un haut responsable ou un chargé de mission dont l’objectif est d’améliorer les services que votre organisation fournit, vous devrez motiver votre initiative vis-à-vis de votre hiérarchie et du reste de votre organisation. Il est donc nécessaire de comprendre comment communiquer efficacement pour que chacun adhère à votre projet. Voyons dans le prochain chapitre quelques pistes pour le faire.
Premièrement, il ne s’agit pas de convaincre. Vous ne pouvez pas arriver devant quelqu’un et lui dire “vous avez tord, j’ai raison”. Vous devez plutôt donner envie à vos interlocuteurs d’adhérer à votre vision, votre projet. Ainsi, ils se convaincront d’eux-mêmes.
Faire adhérer sa hiérarchie ou des collègues de travail à une initiative n’est pas toujours simple. William MORGAN - dirigeant d’une startup réputée dans les technologies - préconise 4 règles à suivre47 :
Selon William MORGAN, une fois qu’on atteint un certain niveau d’ingénierie technique, les métiers de “commercial” et “d’ingénieur” se confondent : “Un travail d’ingénierie suffisamment avancé est indiscernable d’un travail de commercial”.
Voici comment ces règles pourraient être appliquées aux équipes de sécurité et de management :
La théorie des modèles mentaux48 nous permet de mieux comprendre le processus de prise de décision (ex: que quelqu’un adhère ou pas à une initiative). Chaque représentation que l’on se fait des choses (c’est à dire un modèle mental), diffère selon l’individu. Or se transformer, c’est se mettre d’accord ensemble sur un modèle mental alternatif49.
Quand bien même le DevOps peut s’appuyer sur des études et s’avère une évidence dans le privé, les initiatives institutionnelles ne sont pas encore assez nombreuses50. Vous êtes donc dans une situation où vous avez la certitude de la direction à prendre, mais vous n’êtes pas entièrement capable de la justifier par des chiffres ou des exemples. Face à votre proposition de transformation avant-gardiste, le décideur est par conséquent face à un risque. Or, question de survie :
« Il vaut mieux avoir tord avec le groupe, qu’avoir raison contre le groupe. »
Pour aider le décideur à prendre sa décision, vous devez travailler à réduire ce risque. Mais comment ? L’idée est de ralier à votre cause de premiers expérimentateurs (early adopters) à votre projet, sans l’annoncer au collectif.
« Le 1er qui fait le pas prend un risque énorme. Le 150ème n’en prend plus. »
En plus d’améliorer votre proposition de valeur, vous obtiendrez des exemples à citer et du soutien : vous ne serez plus le “1er” à prendre le risque et votre organisation non plus.
« L’initiative est la forme la plus élaborée de la discipline. » - Général LAGARDE
Opérer en coulisse (ne pas annoncer votre projet au collectif) implique d’en comprendre les hypothétiques répercussions. Bien que vous souhaitiez améliorer les choses en toute bonne foi, vous pourriez mal percevoir la situation d’ensemble de votre organisation. Ainsi, votre projet viendrait perturber des jeux de pouvoir établis, vous rendant indésirable aux yeux de certains.
Par exemple, une équipe en manque de moyens vient vous demander de l’aide. Constatant sa détresse, vous lui concevez un tout nouvel outil développé rapidement grâce à votre plateforme DevOps. Vous omettez d’en informer votre hiérarchie, car elle risquerait de refuser cette innovation (cf. chapitre précédent).
Ce que vous ne savez pas, c’est que l’équipe que vous appuyez ne fait plus le travail demandé par la direction depuis plusieurs semaines. Alors que les dirigeants tentent de rééquilibrer la situation, un soudain protagoniste (votre équipe) vient fournir des services à l’équipe fautive.
En apprenant la nouvelle, les dirigeants se retrouvent dans une situation désagréable : ils comprennent l’appui que vous fournissez (il est vertueux en toute bonne foi) mais vous en veulent d’avoir interféré dans leurs affaires.
Et voilà que votre initiative s’enferme dans un cercle vicieux (fig.

Le problème est avant tout culturel : l’organisation n’est pas formée à soutenir l’innovation et il est donc difficile d’innover. Les innovateurs doivent alors trouver des moyens détournés pour changer les choses. D’un autre côté, les innovateurs sont souvent peu acculturés aux structures où on leur demande d’innover. Cela dénotte le besoin de former ces profils pour qu’ils comprennent mieux comment fonctionne l’organisation. En mettant en place les 5 piliers du DevOps, vous aiderez votre organisation à transformer sa culture et favoriser l’innovation (cf. chapitre “Les cinq piliers du DevOps”)
Veillez donc à bien saisir la situation politique entre l’équipe dirigeante et vos premiers expérimentateurs avant d’agir dans l’ombre, au risque de compliquer votre progression.
Gardez en tête que si les choses sont telles qu’elles le sont aujourd’hui, c’est qu’il existe bien des raisons : vous n’avez pas obligatoirement une connaissance exhaustive de ces causes passées (temps alloué aux projets, moyens RH/financiers, jeux de pouvoir…) et n’êtes pas là pour en blamer les acteurs.
Restez également conscient que pendant une transformation, les dirigeants doivent assurer les mêmes services qu’avant. Le décideur doit alors maîtriser l’environnement en transformation en parallèle de l’environnement actuel, sans que le premier tue le second.
Enfin, ne vous découragez pas devant la première personne réticente. Toute innovation à ses débuts fait objet d’une moquerie morale et passe par trois phases : ridicule, dangereuse puis évidente51. L’ayant vécu, je peux attester de la véracité de ce phénomène, mais des exemples historiques existent :
Si vous rencontrez une opposition frontale, vous allez devoir retravailler votre communication (cf. chapitre suivant “Adapter son discours”). Commencez alors par les points de vue opposés. Si vous ressentez que certains veulent délibéremment couper court aux discussions, considérez les approches suivantes.
Une transformation réussie demande de la part de son instigateur une communication irréprochable. Il est important de savoir comment présenter selon le public visé, tout en gardant en tête certains phénomènes organisationnels communs.
« Pourquoi ne semblent-ils pas convaincus ? »
Après l’une de vos présentations, peut-être vous êtes-vous déjà retrouvé dans cette situation ? Validée par nombre de vos pairs, après répétition, et alors même qu’elle vous semblait parfaitement adaptée, cette dernière n’a visiblement pas eu l’effet escompté. La personne en face de vous ne posait pas les bonnes questions, ou semblait ennuyée, voire irritée.
Présenter à différents publics nécessite d’adapter son style de présentation, ses exemples et arguments en fonction de leurs rôles, contraintes et besoins. N’attendez de personne qu’elle comprenne le so what55 de votre présentation, sans avoir compris vous-même l’intérêt qu’elle avait d’y assister. En général, deux présentations suffisent : l’une pour les métiers (ou “clients”) et l’autre pour les hauts responsables (ou “politiques”).
Il est néanmoins important de distinguer les hauts responsables (ou executives) des responsables de proximité (ou managers). Ces derniers ont souvent un lien plus fort avec leurs collaborateurs, leur permettant d’être sensibles aux arguments métiers. Les hauts responsables opèrent quant à eux à l’échelon stratégique56, où ils définissent la vision de l’organisation et fixent les grandes orientations. Les considérations opératives, tactiques et techniques sont déléguées. Le message alors transmis du bas à travers les niveaux hiérarchiques peut s’en retrouver altéré ou déformé.
C’est pourquoi il ne faut pas considérer que les responsables soient nécessairement au courant de tout ce que vous observez à votre niveau. N’hésitez pas à rappeler à votre audience l’effort requis pour les tâches même les plus communes. Par exemple, rappelez-lui que 80% du travail de n individus est dévolu à telle tâche. Et que grâce à votre approche, vous pourriez faire gagner x temps par jour à chaque employé, ce qui représente y euros d’économies ou z fois plus de production.
Le décideur attend des arguments qu’il pourra utiliser pour convaincre à son tour. Essayez de bien cerner les directives auxquelles lui-même doit répondre pour lui fournir les clés de communication qu’il pourra réutiliser. Par exemple, le chef d’une multinationale sera plus sensible aux arguments de rentabilité économique, quand le haut responsable politique considérera davantage l’impact social. Mais tous deux porteront un vif intérêt à s’aligner avec la politique de leur organisation (stratégie de l’entreprise ou priorités du parti / du gouvernement).
Tout comme vous, le décideur qui découvre un sujet ne peut retenir que quelques informations clés. Veillez donc à limiter à 2 ou 3 maximum le nombre d’idées que vous souhaitez lui faire passer. Terminez la présentation par un appel à l’action. Il devra lui permettre de comprendre comment il peut vous aider à réaliser ce projet.
Résumons les intérêts respectifs de nos deux profils :
| Objet | Métiers | Décideurs |
|---|---|---|
| Niveau de détail | Informations pratiques détaillées. | Vue d’ensemble. |
| Termino-logie | Jargon métier et outils spécifiques. | Stratégique, orientée sur les plus-values pour l’organisation elle-même ou la communauté dans laquelle elle s’inscrit. |
| Données et preuves | Exemples pratiques, études de cas. | Métriques d’impacts en temps, en argent, en rayonnement. |
| Objectif | Instruire, informer, solliciter des retours. | Convaincre, obtenir l’approbation. |
| Style de présen-tation | Interactifs, pratiques. | Formel, concis, direct. Orienté vers l’effet final recherché. |
Prenons l’exemple d’une entreprise dont les employés ont besoin d’acquérir un logiciel de traduction performant. Le fournisseur d’une solution vient la présenter au directeur de l’organisation. Voici les arguments à aborder pour chaque profil :
| Objet | Employés | Directeur |
|---|---|---|
| Niveau de détail | A quel point l’outil facilite le travail, comment l’utiliser et quelles sont ses fonctionnalités spécifiques. | Pourquoi l’organisation a-t-elle besoin de cet outil, quel impact il aura. |
| Termino-logie | Termes techniques liés à la traduction et au fonctionnement de l’outil. | Discours axé sur la stratégie, l’efficacité organisationnelle et l’amélioration des performances des collaborateurs. |
| Données et preuves | Démonstration de l’outil en action, comparaisons avant/après, études de cas. | Vue d’ensemble des fonctionnalités. Statistiques d’augmentation de la productivité, retour sur investissement. RETEX d’usages internes. |
| Objectif | Découvrir la plus-value métier (vitesse et qualité de traduction). Comment utiliser l’outil et ses limites. | Comprendre l’impact positif de l’outil sur l’organisation et les investissements qu’il requiert. |
| Style de présen-tation | Pratique, interactif avec démonstrations et questions/réponses. | Synthétique. Axé sur les plus-values organisationnelles avec appel à l’action et fiche synthèse à la fin. |
Enfin, vous ne pouvez pas totalement écarter l’hypothèse selon laquelle votre interlocuteur serait en conflit avec d’autres acteurs dans votre organisation. Cela le freinerait à l’idée de prendre certaines décisions d’un intérêt incontestable, dans l’objectif de conserver son statut ou de protéger sa carrière. Dans ce cas-là, tentez de trouver des relais d’influence de niveau équivalent ou supérieur, qui porteront votre vision parmi les décideurs. Une fois votre message porté par plusieurs hauts dirigeants, il sera difficile pour le concerné de refuser ce que le reste de l’organisation considère comme essentiel.
Une communication peu impactante reste souvent le fruit d’un interlocuteur ayant mal compris, plutôt que d’une personne de mauvaise foi. A défaut d’en être certain, partez du principe que le problème n’est pas la personne en face de vous.
En connaissant les techniques pour appréhender les situations courantes d’opposition au changement, nous pouvons progresser avec davantage de confiance. Examinons désormais comment structurer notre démarche et renforcer nos arguments pour lancer efficacement notre initiative.
Dans le chapitre “Refuser le retard technologique”, j’évoque l’innovation interne comme moyen pour éviter le déclin d’une organisation. Mais il est aussi important de préciser en quoi le développement interne, au delà d’être efficace, s’avère une condition si la structure souhaite rester compétitive.
Quelle entreprise responsable d’un gros projet informatique pourrait se permettre de dire “Nous n’avons pas besoin d’expert informatique” ? En raison du manque d’acculturation technique ou des phénomènes psychologiques évoqués précédemment, les décideurs ont parfois recours aux sociétés de conseil de manière chronique.
A l’instar d’organisations d’envergure mondiales comme l’Organisation Mondiale de la Santé (OMS) ou les Nations Unies (UN), des organisanismes nationaux comme le Centre National de la Recherche Scientifique (CNRS), l’Education Nationale et l’agence Santé publique France intègrent un conseil scientifique interne57. Ils leurs permettent de rester à jours sur les dernières connaissances scientifiques pour que les décideurs puissent prendre des décisions éclairées. Dans le privé, c’est le rôle du Directeur Technique (CTO en anglais) et de ses cadres supérieurs (VPs en anglais).
Bien qu’un conseil scientifique puisse aider l’organisation à rester à la pointe des connaissances scientifiques, il ne suffit pas à la rendre innovante. D’autant plus si ses membres ne sont pas renouvelés périodiquement. Pour innover, il faut pratiquer.
Si vous souhaitez répondre efficacement aux enjeux auxquels fait face votre organisation, seule une équipe interne qui pratique les technologies liées à vos sujets pourra vous y aider. Ainsi, avoir l’audace de monter sa propre équipe technique offre de nombreux avantages. Le contact quotidien avec les métiers ou les clients permet de concevoir des outils sur-mesure et finement adaptés pour répondre efficacement à leurs exigences.
Cette proximité immédiate avec le demandeur facilite également le service d’une assistance en temps réel, éliminant les coûts supplémentaires et les délais habituellement associés à un soutien externe. Cela permet de réaliser des cycles d’amélioration plus courts et d’assurer une livraison plus rapide des demandes.
En ayant la feuille de route des projets sous leur contrôle direct, les décideurs peuvent s’assurer que les développements correspondent parfaitement à leurs besoins et leur vision. Cette gestion interne permet de réduire significativement les coûts, grâce à la mutualisation des investissements au profit de plusieurs projets en simultané.
L’une des forces majeures d’une équipe interne réside dans la sécurité des données, celles-ci restant strictement confinées aux infrastructures de l’organisation et ne sont accessibles qu’aux membres autorisés. Cela limite ainsi le risque de fuite de données.
De plus, une équipe interne possède une capacité unique à évaluer rapidement et avec pertinence les innovations technologiques, en les plaçant dans le contexte des enjeux métiers de l’organisation. Elle est également en mesure de favoriser l’assimilation de ces nouvelles technologies au sein de l’organisation, grâce à des présentations adaptées à tous les niveaux.
Compter uniquement sur une ressource externe pour effectuer vos projets informatiques mènera inévitablement à des coûts prohibitifs. Sans expertise interne, vous êtes à la merci des talentueuses équipes commerciales d’entreprises qui ne manqueront pas de vous vendre des services dont votre organisation n’aura jamais l’usage.
La raison principale de la frilosité des décideurs à l’égard des développements internes est la maintenance. Ils ont raison : payer un prestataire peut coûter cher, mais ce dernier est tenu d’honorer sa prestation par un contrat. Ce même contrat est souvent accompagné d’une prestation de maintenance. Un seul développeur interne - peu outillé car peu soutenu - risquerait d’échouer à la même tâche. Cela mettrait finalement en cause la responsabilité du décideur.
Ainsi, embaucher deux ou trois ingénieurs ne suffira pas pour pérenniser vos développements. Pour réussir à proposer une solution utile, qui puisse être une véritable alternative maintenable et crédible pour votre hiérarchie, vous devrez monter une équipe plus conséquente.
En outillant cette équipe d’un véritable environnement de développement (cf. “Usine logicielle”) et en incluant de bonnes pratiques DevOps, elle aura le temps de s’attarder sur la qualité de vos logiciels. Bien que cela demande un investissement en temps et puisse être une étape éprouvante avec votre hiérarchie, celle-ci ne réalise pas encore à quel point cette avancée lui sera précieuse à l’avenir ! Gardez le cap.
Dans l’une des entreprises pour laquelle j’ai travaillé, le développement interne d’un logiciel par un ingénieur a permis d’économiser plusieurs millions d’euros. Les programmes industriels équivalents n’avançaient pas et les métiers restaient démunis. Il a fallu un seul ingénieur - certes brillant - pour résoudre un problème qui durait depuis plus de 6 ans.
Grâce aux règles DevOps exigeant des standards de qualité logiciel, plus de dix développeurs au cours des trois dernières années ont pu contribuer à ce projet pour le maintenir et l’améliorer. Il reçoit encore aujourd’hui de nombreuses mises à jour hebdomadaires.
Au delà d’apporter une solution pragmatique à un problème, cet ingénieur a surtout permis d’acculturer l’ensemble de la hiérarchie aux notions de développement moderne et de techniques de machine learning. Convié devant les prestataires externes traditionnels aux grandes réunions stratégiques, il est devenu le référent machine learning de l’organisation. Sans lui, personne en interne ne serait en mesure de spécifier un besoin ou d’évaluer une solution de machine learning en toute connaissance de cause.
Nombreuses sont les organisations qui ont souhaité stimuler leurs organisations en montant des « équipes innovation ». Et nombreuses sont celles qui n’ont pas vraiment réussi à déployer en production ce qui y était développé.
Les cas d’usage tournent souvent autour de la data et de l’intelligence artificielle. Les buzz-words « data-scientists », « deep learning » et « intelligence artificielle » ont procuré de nombreux faux espoirs : beaucoup d’organisations ont recruté des profils data-science qui se sont retrouvés incapables de mettre en production leurs algorithmes dans une interface à l’attention d’opérateurs non-experts.
Le problème n’est pas les data-scientists, mais bien les décideurs qui jusqu’à récemment ne comprenaient pas ce qu’impliquait la réponse au besoin métier : un socle de développement fiable, des données propres, des données massives, du suivi de modèles58 (MLOps), une équipe de mise en production. En somme, beaucoup pensaient (et continuent de penser) que « l’IA » peut résoudre n’importe quel problème avec quelques lignes de code. Ces personnes n’ont pas conscience de l’infrastructure et du soutien technique qu’impliquent ces technologies.
L’exemple typique de la data-science vis-à-vis du DevOps est le besoin de puissance de calcul, de capacité de stockage et de services pour développer et suivre l’entraînement de ces modèles. Or la plupart des data-scientists ne seront pas en mesure d’installer seul leur machine, leurs drivers GPU59 et leur environnement Jupyter Notebook60. En particulier dans des environnements complexes propres aux grandes organisations (contraintes réglementaires).
Ce qui permettra à votre équipe de se différencier, c’est l’appui que vous fournissez à vos opérateurs. Par rapport aux équipes de développement traditionnelles ou aux prestataires externes, votre avantage est la possibilité d’être en forte proximité avec les métiers de votre organisation.
C’est la fameuse méthodologie « agile » à l’opposé du « cycle en V » (ou méthodologie waterfall).
Dans de nombreuses organisations, on travaille encore en « V » : le prestataire vient rencontrer l’équipe métier qui a émis un besoin, produit un PowerPoint 1 mois après, puis dévoile le résultat du développement entre 6 mois et 6 ans. Dans le domaine logiciel, le produit livré est déjà périmé et les équipes en ayant fait la demande ont parfois déjà changé.
Dans le domaine industriel - tel que la conception d’un navire de guerre par exemple - il est légitime de s’assurer que son bâtiment va correctement flotter et que son gouvernail l’orientera correctement avant de le mettre à l’eau. Les caractéristiques du navire sont d’ailleurs souvent fixées : son autonomie, la portée de ses missiles, son temps de service… On ne va pas changer la composition de la coque au dernier moment ou modifier le palier de ligne d’arbre. Le cycle en “V” est alors adapté.
Cependant en logiciel, il est possible d’adopter une approche plus agile. Le comportement d’un programme informatique est évaluable et peut être simulée en quasi temps-réel. Cela permet d’adapter un logiciel à tout moment, en s’assurant qu’il remplisse correctement les objectifs fixés (fig.
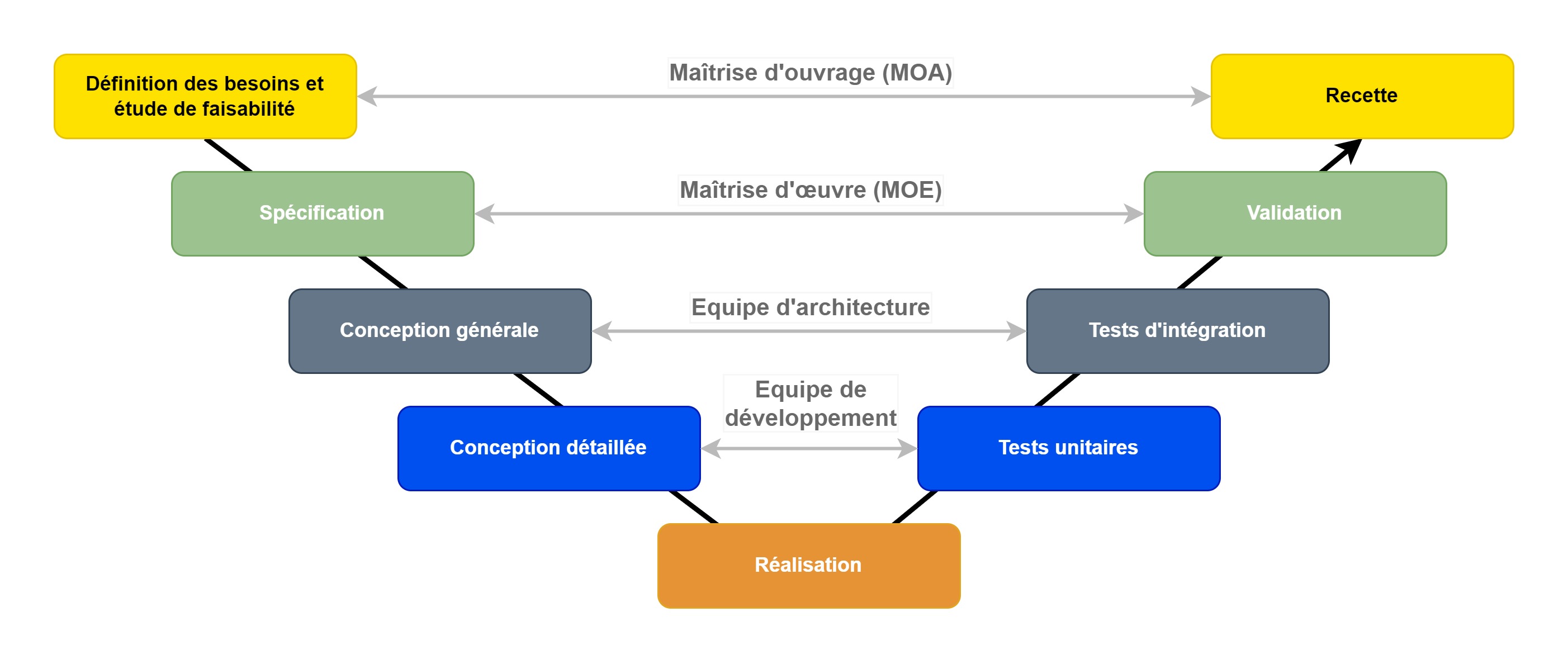
Ainsi, au sein d’un programme d’armement, l’informatique embarquée à bord d’un navire (ex: capteurs, systèmes d’information) peut être pilotée par la méthodologie agile, quand la production du porteur61 peut être régie par la méthodologie en “V”. Alors que la coque subira peu de changements, les logiciels peuvent être renouvelés à la vitesse exigée par les opérations62.
Au-delà de la solution technique que vous leur apporterez, vos métiers constateront que votre mode d’organisation - plus agile - est efficace pour eux. Ils soutiendront par conséquent votre initiative. En tant que chef d’équipe, votre objectif doit être de pouvoir faire témoigner, lors de présentations importantes, des représentants d’équipes métiers que vous avez aidé grâce à vos outils. Ces représentations permettront d’asseoir votre crédibilité et d’éviter que vos équipes soient reconnues comme de simples « prestataires de développement technique ».

Cette proximité avec les métiers permettra à vos équipes de se sentir davantage impliquées dans les missions de votre organisation. C’est une dynamique gagnante à la fois pour vos ingénieurs et vos clients. Chacun se nourrit ainsi de la connaissance de l’autre : l’ingénieur découvre le fond du sujet, comprend mieux le problème, pendant que l’opérateur spécifie son besoin le plus précisément possible.
L’illustration de Henrik KNIBERG63, coach agile, nous permet de bien cerner l’intérêt de la méthodologie agile : on préfère livrer à chaque étape quelque chose qui fonctionne - bien que non abouti - pour récolter les retours utilisateur et itérer (fig.
Vous avez dû probablement vous en rendre compte au cours de votre carrière : le client a souvent du mal à exprimer ce qu’il veut exactement. La méthodologie agile et ultimement la méthodologie DevOps permettent de s’adapter aux réalités du métier au cours du temps, pour mieux les comprendre et livrer un produit qui répond réellement à ses besoins.
En automatisant les procédés rébarbatifs, les techniques DevOps vous permettront de libérer du temps pour en passer davantage avec votre client, mieux comprendre son besoin et mieux traiter ses retours ou suggestions.

Mettre au contact profils techniques et métiers est un enjeu de fidélisation au-delà de la plus-value d’une réponse plus rapidement et précise aux problématiques internes. Rappelez-vous : vos équipes sont en quête de sens. Elles ne viennent pas au travail le matin pour répondre à l’ordre de leur supérieur, mais pour concevoir grâce à leur expertise la solution technique qui répondra le mieux au problème du métier. L’aboutissement du travail d’un ingénieur est de voir le métier utiliser la création qu’il a conçu.
L’un des piliers du DevOps est de réduire les silos. Cela inclut l’accès aux données.
Si vous souhaitez que vos équipes techniques répondent du mieux possible à votre besoin, elles ont besoin d’un accès privilégié aux données de votre entreprise.
Lorsque le cadre juridique vous le permet, abandonnez les « échantillons anonymisés ». Les ingénieurs ont besoin de comprendre précisément de quoi est composée la donnée qu’ils sont censés traiter. Tenter de développer un outil sur des données « anonymes » revient à développer un outil qui ne répond que partiellement à un cas d’usage.
Autrement, vous êtes certain qu’un bug se produira dès lors qu’une donnée « inconnue » passera dans le logiciel (cf. edge cases). Fournissez à vos équipes les données de production qui ont vocation à être utilisées dans les outils : vous perdrez moins de temps en résolution de bugs et améliorerez la qualité du service fournit par vos logiciels.
Si vous ne disposez pas des autorisations nécessaires, il n’est peut-être pas nécessaire d’embaucher des personnes en interne. Un prestataire pourra tout aussi bien construire le logiciel à partir de données en source ouverte. Considérez néanmoins les risques de procéder ainsi (cf. Être au plus proche du métier).
L’idée selon laquelle le DevOps permet de rapprocher les différents métiers pour collaborer n’est pas simple à mettre en pratique. Les métiers historiques de la sécurité des systèmes d’information (SSI) se sont vu imposer des pratiques auxquelles ils n’étaient pas habitués et qu’ils n’ont parfois pas eu le temps d’appréhender.
Dans les grandes organisations, les règles de l’entreprise ou bien la loi elle-même imposent que des versions bien précises d’un logiciel soient définies pour qu’il soit qualifié64 ou homologué. Imaginez alors avoir la responsabilité de faire respecter ces conditions quand les méthodes DevOps impliquent des dizaines de mises à jour logicielles chaque jour : il y a de quoi prendre peur ! Il est donc nécessaire de bien comprendre de quoi est composée une infrastructure cloud, pour correctement définir ce qu’implique sa “sécurité”.
La sécurité affecte tous les piliers du DevOps. Ce chapitre se concentre sur une description haut-niveau des notions de la sécurité dans une approche DevOps.
Dans ce mode d’organisation, les pratiques de sécurité sont automatisées pour être vérifiées systématiquement. L’objectif est d’éviter au maximum la sécurité dite “documentaire” en faveur de règles programmées. En effet, le fait d’user de technologies standardisées (cf. conteneurs, Kubernetes) permet de faciliter la mise en pratique des règles de sécurité pour obtenir la garantie qu’elles soient appliquées.
Le rapport DORA65 “State of DevOps 2022”66 se concentre sur les enjeux de sécurité dans les initiatives de transformation des entreprises en mode DevOps. Il fait état du fait qu’une entreprise favorisant la confiance et la sécurité psychologique est 60% plus susceptible d’adopter des pratiques de sécurité innovantes. Il ajoute que cette culture permet de réduire de 40% le nombre de burnouts67 et augmente les chances qu’un collaborateur recommande son entreprise.
La sécurité a toujours été une affaire de culture. La méthodologie DevOps vient cependant apporter toutes les techniques qui permettront à une organisation de ne plus passer à côté des bonnes pratiques, autrefois négligées ou oubliées dans des archives volumineuses et indigestes.
L’essentiel est de comprendre qu’en mode DevOps, nous travaillons dans un principe de cycle d’amélioration itératif. Les projets ne sont jamais figés en terme de technologie utilisée et les déploiements sont continus sans interaction humaine. Cela permet de ne pas nuire à la vélocité des innovations et de toujours répondre le plus justement possible au besoin du client.
Mais ce n’est pas la loi de la jungle : il existe des standards technologiques et des procédés qui permettent de contrôler ce qui est déployé, selon les standards de sécurité exigés par votre organisation.
Nous détaillerons plus en détail les aspects culturels de la méthodologie DevOps dans le chapitre “Accepter l’échec”.
Il existe trois manières de gérer le risque lorsque l’on doit faire un choix technique vis-à-vis des caractéristiques de sécurité d’une technologie. L’ANSSI définit les termes suivants de cette manière :
La certification/qualification concerne un produit. L’homologation concerne le déploiement de ce produit dans un environnement (un système d’information). Alors que la certification n’est pas une obligation légale, l’homologation peut l’être selon que vos règles SSI ou la loi l’imposent (ex: si vous êtes un OIV71). Elle représente l’acceptation du risque face aux bénéfices que l’installation apporte. En ce sens, elle peut être validée par une autorité SSI indépendamment de la certification/qualification d’un produit.
Les qualifications, certifications et homologations sont en l’état assez peu adaptées aux pratiques de déploiement continu, car elles figent le risque à l’instant T. Or les menaces s’imposent au jour le jour : une faille dans une librairie peut par exemple être détectée un jour après l’approbation d’une homologation. Bien que l’homologation soit temporaire, la faille va quand même persister pendant ce temps, au risque d’être exploitée. Faut-il encore qu’elle soit détectée et que la personne ayant subit l’aventure administrative que représente l’homologation ait envie de réitérer l’expérience.
La sécurisation d’un système d’information est meilleure si l’on part du principe qu’une faille de sécurité risque à tout moment de survenir ou d’être déployée, mais que les procédés mis en place permettent de réagir rapidement à cette menace pour l’inhiber. Pour ce faire, il est recommandé de mettre en place des techniques d’intégration continue.
L’intégration continue permet de contrôler automatiquement une modification apportée à un logiciel ou une infrastructure.
Dès que la moindre ligne de code est modifiée, des tests se lancent. Si une modification du code ne satisfait pas les standards de sécurité définis, la contribution72 est refusée. Le développeur est automatiquement informé dans son usine logicielle (ex: GitLab). En se rendant sur la page concernée, il peut visualiser un message d’erreur lui expliquant le problème. Ainsi, il est immédiatement en mesure d’effectuer les modifications pour se conformer.
C’est ici qu’on attend l’expertise des responsables de la sécurité. Ces profils doivent expliquer aux ingénieurs DevOps et aux SRE ce qui concrètement doit être contrôlé. Ces règles sont ensuite transcrites en code qui formera des tests automatisés, dans une chaîne d’intégration continue utilisée par tous les projets de l’entreprise.
Ces règles versionnées sous forme de code deviennent des tests automatisés. Elles pourront être mises à jour à souhait et impacteront immédiatement l’ensemble des projets.
Elles peuvent se composer d’une analyse antivirus, d’une analyse de failles dans les images Docker utilisées, ou encore s’assurer qu’il n’y ait pas de mots de passe laissés dans un fichier public par inadvertance.

Dans l’illustration ci-dessus (fig.
Un point d’exclamation signifie que le test n’est pas passé mais qu’il n’était pas considéré critique (ex: une dépendance logicielle dépréciée mais sans faille de sécurité).
Pour les ingénieurs, le Graal est de voir son projet accompagné d’une coche verte, signifiant que tous les tests ont été passés avec succès.

Dans une approche DevOps, les développeurs ne partent pas d’un projet vide. Ils partent d’un modèle (template en anglais)73 qu’ils copient et qui intègre - en plus des fichiers pour le développement - toutes les règles de sécurité. Veillez à ce que les équipes de sécurité co-contribuent à ces modèles pour que tout nouveau projet intègre vos standards de sécurité (cf. chapitre “Intégration continue et sécurité”) pour faire gagner du temps à tout le monde.
Les chaînes d’intégration continue ne se limitent pas à des tests de sécurité. Voyez les comme des scripts lancés automatiquement à chaque modification du code. Bien que le déclencheur traditionnel soit la “modification du code”, les hébergeurs Cloud comme AWS peuvent aussi proposer leurs propres déclencheurs (ex: l’ajout d’un fichier dans un bucket S3)74. Nous verrons plus en détails le fonctionne de l’intégration continue dans le chapitre “Intégration Continue (CI)”.
Dans un monde idéal, toute vérification est automatisée. Néanmoins, il est parfois compliqué de “coder” des vérifications de sécurité avancées et il est possible que vous ne soyez pas dimensionné en RH pour les développer.
En DevOps, on pratique la méthodologie GitOps : tout est basé sur le code (logiciel, infrastructure, schémas d’architecture, présentations etc…).
Chaque développeur travaille sur sa propre branche et développe sa fonctionnalité. Il teste si tout fonctionne comme attendu, puis crée une “demande de fusion” (communément appelée merge request ou pull request) dans la branche principale. Ce processus est détaillé dans le chapitre “Workflows git”.
La revue de code se passe à ce moment-là. Elle est l’occasion pour les ingénieurs d’approuver les modifications des autres, en apportant un regard extérieur avant qu’elle soit fusionnée sur la branche principale. C’est à ce moment que les différentes personnes impliquées dans la vérification de la qualité d’une contribution peuvent écrire leurs commentaires (fig.
L’objectif est de vérifier que le développeur n’ait pas fait de grosse erreur dans le fonctionnement du code, ou de s’assurer qu’il n’ajoute pas de dette technique. Par exemple chez Google, une merge request requiert l’approbation d’au moins deux ingénieurs avant de pouvoir être validée.

La publication d’une nouvelle version d’un logiciel en production est le moment idéal pour que les équipes de sécurité auditent le code. Cette pratique s’appelle la “revue de sécurité”. Toute nouvelle version d’un logiciel est soumise aux règles d’intégration continue précédemment citées avec des tests automatisés de sécurité supplémentaires et optionnellement la validation de l’équipe de sécurité.
Pour les équipes des sécurité, la revue de code a pour objectif de vérifier que le maximum de critères de sécurité sont respectés. Par exemple :
GitLab permet par exemple d’obliger l’approbation d’une merge request par des équipes spécifiques75 (ex: l’équipe de sécurité), avant qu’une contribution puisse être fusionnée dans la branche principale (fig.
Des outils comme ReviewDog, Hound ou Sider Scan permettent d’assister les ingénieurs lors de la revue de code. Par exemple, ces outils font passer des linters76 et ajoutent automatiquement des commentaires à la ligne concernée.
Pour simplifier la compréhension des notions abordées, le terme “chaîne logicielle” est employé à la place de “chaîne de développement et de déploiement des logiciels” (software supply-chain en anglais).
En mai 2021, la Maison Blanche a fait paraître un décret décrivant de nouvelles pistes pour “améliorer la cybersécurité du pays”. Parmi 7 priorités77 décrites, la volonté d’améliorer la sécurité de la chaîne logicielle est citée. Il stipule qu’il est “urgent de mettre en œuvre des techniques plus rigoureuses, permettant d’anticiper plus rapidement, pour garantir que les produits (logiciels achetés par les gouvernements) fonctionnent en toute sécurité et comme prévu”78. Cette volonté a été renouvelée en janvier 2022 lors de la signature par Joe BIDEN du mémorandum sur la sécurité nationale des États-Unis79.
Les guides de montée en maturité DevSecOps (DevSecOps * Models) comme ceux de OWASP80, DataDog81, AWS82 ou GitLab83 présentent des techniques générales pour améliorer ses pratiques DevSecOps. Ils permettent de découper la montée en maturité de l’organisation en plusieurs étapes plus accessibles, pour atteindre de meilleures pratiques de sécurité.
Dans un premier temps, nous découvrirons les techniques et outils utilisés pour sécuriser sa chaîne logicielle. Nous verrons ensuite comment ils s’intègrent grâce aux frameworks. La vaste majorité des outils cités dans ce chapitre sont lancés au sein de chaînes d’intégration continues, dans l’intérêt de valider toutes les règles de sécurité de son organisation à chaque modification du code.
Les pratiques SSI au sein des grandes organisation requièrent souvent que tout logiciel déployé soit homologué. Le document d’homologation doit lister les dépendances utilisées dans le logiciel : les librairies tierce partie sur lesquelles il se base. Cette liste se nomme le Software Bill of Materials (SBOM84) ou “Nomenclature du logiciel” en français.
Le SBOM permet de rapidement répondre à des questions comme “Sommes-nous affectés ?” ou “Où est utilisée cette librairie dans nos logiciels ?”, lorsqu’une nouvelle faille est découverte. Dans une approche DevOps, les librairies utilisées dans un logiciel changent au cours du temps. Une librairie ou une technologie utilisée un jour sera peut-être remplacée demain. Vous ne pouvez donc pas demander aux développeurs de lister manuellement ces centaines (voire milliers) de dépendances utilisées dans leurs logiciels.
Le SBOM fait partie des techniques de Software Component Analysis (SCA) ou “Analyse des composants logiciel”. La SCA regroupe les techniques et outils pour déterminer quels sont les composants des logiciels tiers d’un logiciel (ex: les dépendances, leur code et leurs licences), pour s’assurer qu’ils n’introduisent pas de risques de sécurité ou de bugs.
L’avantage de la méthodologie DevOps est que l’ensemble du code est centralisé au sein de l’usine logicielle. Cela nous permet d’utiliser des outils pour analyser de quoi chaque projet est composé et prévenir les failles de sécurité.
Il est possible de générer le SBOM de son logiciel grâce à des outils comme Syft, Tern ou CycloneDX. Le format standard d’un fichier SBOM est SPDX, mais certains outils comme CycloneDX ont le leur. La pratique veut que vous stockiez ce fichier dans un artéfact signé par votre forge logicielle, à chaque nouvelle version du logiciel que vous souhaitez déployer.
L’objectif reste de savoir si une librairie utilisée est vulnérable, pour la mettre à jour ou la remplacer. Hormis pour répondre à des contraintes réglementaires, laisser ce fichier à l’état de simple document n’est pas très utile. Voilà pourquoi il faut désormais analyser le SBOM.
Un outil léger d’analyse comme OSV-Scanner pourra s’intégrer facilement à vos chaînes d’intégration continue et fournir un premier niveau de protection. Néanmoins, il ne permettra pas d’avoir une vue d’ensemble sur tous les logiciels affectés au sein de votre infrastructure. Des outils comme Dependency Track (fig.

Des logiciels comme Renovate ou GitHub Dependabot permettent de détecter les dépendances comportant des vulnérabilités, et d’automatiquement proposer une mise à jour dans la forge logicielle en ouvrant une merge request (cf. chapitre “Revues de code”).
En résumé : Au lieu de simplement lister les dépendances, il s’agit de mettre en place une détection continue des librairies utilisées, pour tous les projets. Il faut pouvoir alerter au plus tôt des menaces et refuser les contributions pouvant apporter des risques, avant qu’elles soient déployées en production.
Alors que les outils de SCA vous permettront d’analyser de quoi est composé votre projet (ses dépendances et logiciels utilisés), les outils de SAST ont pour vocation d’analyser le code du logiciel que vous développez. Néanmoins, les outils de SAST prennent également en charge des fonctionnalités du SCA. Les deux se regroupent dans le domaine de la Source code analysis ou “Analyse de code source”.
Le Static Application Security Testing (SAST) ou “Test statique de la sécurité des applications” en français, concentre les techniques et les outils ayant vocation à trouver des vulnérabilités dans votre code source avant qu’il ne soit lancé. Ils constituent une forme de test en boîte blanche. Par exemple, les outils de SAST vont identifier des configurations non sécurisées, des risques d’injection SQL, des fuites mémoire, des risques de traversée de chemins ou des situations de concurrence.
Voici une liste d’outils SAST accompagnés de leur description pour bien comprendre leur variété :
Une vaste liste d’outils open-source et commerciaux d’analyse de code est disponible sur le site de la fondation OWASP86.
Le SAST permet d’améliorer significativement la sécurité de sa chaîne logicielle, mais il ne se substitue pas aux autres pratiques de sécurité. En effet, les analyses statiques peuvent produire des faux positifs ou manquer des vulnérabilités qui ne se manifestent qu’à l’exécution du programme. Il est donc recommandé de compléter le SAST par d’autres techniques comme le DAST (Dynamic Application Security Testing) ou l’IAST (Interactive Application Security Testing). Nous les verrons dans les chapitres suivants.
En résumé : Le SAST est une approche dite “proactive” de la sécurité, qui permet d’identifier et de corriger les vulnérabilités avant même qu’elles ne puissent être exploitées. Intégré au sein du processus de développement, il permet de réduire les risques de sécurité et d’assurer une meilleure qualité du code. L’objectif est de garder un œil attentif sur la sécurité du code source, tout au long de son cycle de vie, pour éviter des erreurs qui pourraient être exploitées en production par des acteurs malveillants.
Le Dynamic Application Security Testing (DAST) ou “Test de sécurité dynamique des applications” en français, est une technique d’analyse qui se concentre sur la détection des vulnérabilités dans une application en cours d’exécution.
Il s’agit en quelque sorte d’un test d’intrusion automatisé en mode black box qui permet d’identifier de potentielles vulnérabilités que les attaquants pourraient exploiter une fois le logiciel en production. Ces vulnérabilités peuvent être des injections SQL, des attaques de Cross-Site Scripting (XSS), ou des problèmes sur les mécanismes d’authentification.
L’un des intérêts du DAST est qu’il ne nécessite pas d’accéder au code source de l’application. Utilisé en complément du SAST, il offre une couverture de sécurité plus complète. En effet, le DAST peut détecter des vulnérabilités qui seraient passées inaperçues lors d’une analyse statique, et vice versa.
De nombreux produits dont les fonctionnalités se recoupent existent. Ils permettent généralement de scanner des vulnérabilités de manière automatisé comprenant : du fuzzing (entrées aléatoires), de l’analyse de trafic entre navigateur et API, de l’attaque par force brute ou encore de l’analyse de vulnérabilités dans le code Javascript. L’outil de DAST incontournable est OWASP ZAP (fig.

Une vaste liste d’outils open-source et commerciaux d’analyse de code est disponible sur le site de la fondation OWASP87.
Cependant, le DAST n’est pas une solution miracle : les tests peuvent parfois produire des faux positifs ou des faux négatifs, il ne peut pas détecter de vulnérabilités ou des mauvaises pratiques au niveau du code source et il peut demander des connaissances avancées pour configurer les tests. Les outils de DAST doivent donc être utilisés en combinaison avec d’autres techniques de sécurité, comme le SAST et l’IAST.
En résumé : Le DAST englobe les outils permettant d’analyser les applications en temps réel pour détecter de potentielles vulnérabilités. Il complète l’analyse statique (SAST). En intégrant le DAST dans sa chaîne logicielle, il est possible d’assurer la sécurité de ses applications tout au long du cycle de vie du logiciel : en développement et en production.
Le Interactive Application Security Testing (IAST) ou “Test interactif de sécurité des applications” en français, regroupe les outils qui identifient et diagnostiquent les problèmes de sécurité dans les applications, qu’elles soient en cours d’exécution ou pendant la phase de développement.
Selon OWASP88, les outils IAST sont aujourd’hui principalement conçus pour analyser les applications Web et les API Web. Mais certains produits IAST peuvent également analyser des logiciels non-Web.
Les IAST ont accès à l’ensemble du code de l’application - tout comme les outils SAST - mais peuvent également surveiller le comportement de l’application pendant son exécution - comme le font les outils de DAST. Cela leur donne une vue d’ensemble plus complète de l’application et de son environnement, leur permettant d’identifier des vulnérabilités qui pourraient être manquées par les SAST et DAST.
« Les IAST sont fantastiques ! Je peux donc mettre mes outils de SAST et DAST à la poubelle ? »
Bien entendu, non. Chacun ont leurs avantages et leurs inconvénients :
DAST ou IAST, les outils nécessitent généralement une solide connaissance de l’application pour réaliser les bons tests et les interpréter. Cela repose souvent sur des ingénieurs ayant une expertise poussée du logiciel à tester, et plus généralement de bonnes connaissances en sécurité. Enfin, très rares sont les solutions open-source dans le domaine, ce qui va nécessairement engendrer des coûts. Ces deux types d’outils sont donc intéressants mais demandent un certain investissement en temps, en ressources humaines et en argent.
Dans une infrastructure DevSecOps mature, les approches de SAST, DAST et IAST se combinent. Des logiciels tout-en-un dédiés à la sécurisation du cycle de développement et intégrés aux sein des forges logicielles existent. Snyk, Acunetix, Checkmarx, Invicti ou encore Veracode en sont des exemples.
Aujourd’hui, des standards décrivent la manière dont il est possible de correctement sécuriser sa chaîne logicielle. Ils sont regroupés au sein de ce que l’on appelle des frameworks de sécurité89.
Chacun des frameworks présentés dans ce chapitre (SLSA, SSCSP, SSDF) contient une liste de recommandations, sur les techniques de sécurité à mettre en place au sein de sa chaîne logicielle. Ils induisent l’usage des techniques et outils de SCA, SAST, IAST et DAST.
Le framework Supply-chain Levels for Software Artifacts (SLSA90, prononcé “salsa”) se concentre sur l’intégrité des données et des artéfacts, tout au long du cycle de développement et déploiement logiciel.
Le SLSA est né des pratiques internes de Google. L’entreprise a développé des techniques pour veiller à ce que les employés, en agissant seuls, ne puissent pas accéder directement ou indirectement aux données des utilisateurs - ni les manipuler de toute autre manière - sans autorisation et justification appropriées91.
En développant des logiciels, vous utilisez et produisez des artéfacts (artifacts en anglais). Ces derniers peuvent qualifier une librairie de développement utilisée dans votre code, un binaire de machine learning ou encore le produit de la compilation de votre logiciel (un .bin, .exe, .whl…). Le SLSA part du principe que chaque étape de la création d’un logiciel implique une vulnérabilité différente et que ces artéfacts sont un vecteur privilégié de menace (fig.
Ses règles tournent autour de la vérification automatique de l’intégrité des données manipulées. Quelques exemples des vulnérabilités auxquelles le SLSA répond :
En fonction de la maturité technique de son équipe, il est possible d’appliquer les règles SLSA selon 4 niveaux de sécurité et de complexité. L’idée est de pouvoir progressivement améliorer la sécurité de sa chaîne logicielle au cours du temps.
Le SLSA se compose de deux parties :
Le projet FRSCA92 est un exemple pragmatique d’une usine logicielle mettant en œuvre les pré-requis SLSA. Des intégrations au sein de chaînes d’intégration continue de GitHub sont aussi disponibles comme avec la “SLSA Build Provenance Action”.
La documentation du SLSA est régulièrement mise à jour par la communauté93 et disponible sur son site officiel.
Les spécifications du Software Supply Chain Security Paper (SSCSP ou SSCP) de la réputée Cloud Native Computing Foundation (CNCF) sont complémentaires aux SLSA. Elles couvrent historiquement un panel plus large de sujets, mais beaucoup de recommandations se recoupent aujourd’hui.
Bien que le SLSA propose une documentation plus interactive, bien illustrée (avec des exemples d’outils à utiliser ou de menaces pour chaque règle) et presque rendu ludique grâce à ses “badges de niveau de sécurité”, les spécifications SSCSP semblent permettre - au moment de l’écriture de ce livre - de donner une vision plus haut-niveau sur les menaces au sein d’une chaîne logicielle.
Mot de l’auteur : Plus accessible pour débuter, je recommande de démarrer son projet de sécurisation d’usine logicielle avec le SSCSP, puis de progresser avec le SLSA.
Ce document est également contributif94 et fait plus largement partie des standards95 adoptés par l’équipe des conseillers techniques en sécurité (TAG) de la CNCF. Ces derniers rédigent différents documents de référence ayant vocation à améliorer la sécurité de l’écosystème cloud96.
Le Secure Software Development Framework (SSDF97) est un document rédigé par le National Institute of Standards and Technology (NIST) de l’US Department of Commerce à l’attention de tout éditeur et tout acquéreur de logiciels, indépendamment de leur appartenance ou non à une entité gouvernementale.
Le travail du NIST est à saluer par la variété et la qualité des rapports produits sur des technologies et techniques à l’état de l’art. Leurs travaux sont la plupart du temps le fruit d’une réflexion menée en concertation avec de nombreuses institutions et entreprises du privé. On y retrouve par exemple Google, AWS, IBM, Microsoft, le Naval Sea Systems Command ou encore le Software Engineering Institute.
Plus complet que les deux précédents, le SSDF agit comme un annuaire regroupant les recommandations issues de dizaines d’autres frameworks (ex: SSCSP, OWASP SAMM, MSSDL, BSIMM, PCI SSLC, OWASP SCVS98). Il les classe en 4 grands thèmes : préparer l’organisation, protéger les logiciels, produire des logiciels bien sécurisés, répondre aux vulnérabilités.
Le framework répertorie des notions générales associées progressivement à des règles plus concrètes. Chacun des thèmes regroupe des grandes pratiques à suivre, qui incluent elle-mêmes des tâches contenant des exemples, associés à des références aux frameworks concernés.
Par exemple pour le thème “protéger les logiciels”, la pratique “protéger toutes les formes de code contre l’accès non autorisé et la falsification” propose d’utiliser la “signature numérique des commits99” en référence au SSCSP dans son chapitre “Sécuriser le code source”.
Ce document est à retrouver sur le site Internet du NIST. La bibliothèque en ligne du directeur de l’information100 (CIO) de l’US Department of Defense est également une excellente source d’inspiration.
GitHub est la plateforme de partage de code la plus populaire sur Internet. Elle héberge plus de 100 millions de projets avec plus de 40 millions de développeurs. Pillier dans le domaine de l’open-source, elle propose des outils de sécurité nativement intégrés à sa plateforme.
L’objectif de GitHub est de faire en sorte que protéger son code ne nécessite que quelques clics pour activer les outils opportuns.
L’entreprise a opéré un virage stratégique en faisant l’acquisition en 2019 de Semmle, un outil d’analyse des vulnérabilités dans le code. Depuis, elle propose plusieurs moyens de sécuriser sa base de code :
SCA et SAST : outils d’analyse automatisée de vulnérabilités dans le code source et ses dépendances (ex: injections SQL, faille XSS, erreurs de configuration et autres vulnérabilités communes). GitHub inclut également une marketplace permettant d’ajouter des analyseurs de code provenant de tierces-parties. Vous pouvez ajouter vos propres règles en écrivant des fichiers CodeQL. Vous pouvez mettre en place ces outils sur votre infrastructure, par exemple avec GitHub Code Scanning (fig.

Analyseur de secrets : analyse, détecte et alerte sur de potentiels mots de passe ou tokens laissés par erreur dans le code source. Alternative open-source : Gitleaks.
Dependabot : outil d’analyse dynamique des risques liés aux dépendances utilisées (ex: vulnérabilités, librairie non maintenue, risques légaux). Dependabot ouvre automatiquement une proposition de modification du code (pull-request) sur le projet et suggère la mise à jour de la dépendance ou bien une alternative (fig.
Toutes les failles de sécurité liées à un projet sont centralisées au sein d’une vue d’ensemble, permettant de facilement détecter les menaces et y remédier (fig.

GitHub se base sur le référentiel international des CVEs101 (Common Vulnerabilities and Exposures) pour reconnaître les failles, une liste de vulnérabilités identifiées dans les systèmes informatiques et décrites sous un format précis. Vous pouvez ajouter des mécanismes de vérification supplémentaires grâce aux GitHub Actions, le mécanisme d’intégration continue de GitHub.
Pour limiter les risques, il est possible de baser les logiciels développés sur des ressources pré-approuvées mises à disposition des développeurs. Chaque brique externe qui constitue le logiciel est vérifiée. Il peut s’agir de paquets Python, NPM, Go ou encore d’images Docker qui ont été analysés et pour lesquels les équipes de sécurité se sont assurées qu’il n’y avait pas de faille.
C’est le cas par exemple du service Iron Bank102 mis en place par l’U.S. Department of Defense au sein de Platform One103. Les images Docker doivent passer par une rigoureuse procédure de validation avant d’être approuvées. Ces étapes combinent des vérifications manuelles et automatiques mais peuvent déjà faire, dans un premier temps, l’objet de procédures seulement automatisées. Les actions manuelles sont nécessaires pour justifier de l’intérêt d’ajouter une nouvelle image. C’est ce que les équipes de Platform One nomment “l’homologation continue d’images approuvées”104 (fig.

Dans les organisations traitant de données très sensibles (c’est à dire des données pouvant mettre en péril la sécurité ou la crédibilité d’un pays si elles sont dévoilées), la politique par défaut est de n’autoriser que l’utilisation de librairies et d’images pré-approuvées (hardened images). Veillez néanmoins à considérer l’impact d’un tel choix sur la vélocité des développements. Soyez certain que vos équipes de sécurité et SRE puissent suivre le rythme de la mise à disposition des librairies.
Comme il est inenvisageable d’analyser “à la main” chaque librairie de développement pour s’assurer qu’elle ne comporte pas de faille, les usines logicielles peuvent se baser sur la signature des fichiers. Les éditeurs de confiance signent chacune de leur librairie105, pour que les chaînes d’intégration continue ou les administrateurs systèmes puissent vérifier qu’elle n’a pas été altérée au cours du transfert. Chaque éditeur de confiance émet un certificat que l’équipe SRE peut intégrer dans ses chaînes d’intégration continue pour vérifier que les paquets téléchargés n’ont pas été altérés.
Une méthode plus simple est de n’utiliser que la clé de hachage des fichiers. Chaque fichier est identifié par une chaîne de caractères nommée hash, que l’ordinateur peut facilement calculer.
Exemple de hash : a21c218df41f6d7fd032535fe20394e2.
Si lors de l’installation, la dépendance téléchargée dispose d’un hash différent de celui de référence (récupéré depuis Internet sur le site de l’éditeur), le lancement du logiciel est refusé. Ce mécanisme est la plupart du temps déjà intégré aux gestionnaires de paquets des langages de programmation (ex: package-lock.json pour NPM, poetry.lock pour Python).
L’humain est le premier vecteur de risques de sécurité106. Pour éviter au maximum l’erreur ou la compromission volontaire d’un système, les infrastructures modernes sont déployées sous forme de “code”.
C’est à dire que pour opérer l’infrastructure au quotidien (en dehors d’un cas d’urgence), toute action d’administration est codée, publiée et vérifiée dans l’usine logicielle avant d’être déployée. Cela permet de pouvoir normaliser (“standardiser”), documenter, rejouer et optimiser les actions d’administration au cours du temps.
Le domaine englobant les techniques de gestion de la production en code est communément appelé Infrastructure as Code (IaC). Cette notion et sa pertinence sont décrites dans le chapitre “Infrastructure as Code”.
La figure prod-fr-zone-c-server-18.

L’exemple ci-dessus est simple mais l’IaC peut aller jusqu’à décrire la manière dont des machines peuvent être instanciées et configurées. Une configuration d’Iac peut entièrement configurer une machine vierge (paramètres réseau, certificats de sécurité, ajout d’utilisateurs, installation des drivers d’une imprimante, configuration des favoris du navigateur…). L’idée est encore une fois d’éviter au maximum l’intervention humaine pour éviter les erreurs.
Le concept zero trust se résume en une expression : “Ne jamais faire confiance, toujours vérifier”. Cette pratique s’impose aujourd’hui avec 55% des entreprises qui répondaient avoir mis en place une initiative zero trust en 2022 contre 24% en 2021107.
Traditionnellement, la sécurité des réseaux était basée sur la définition d’un “périmètre de confiance” tracé autour des logiciels et des données d’une organisation. Elle mettait ensuite en place une variété d’outils et de technologies pour les protéger. Cette architecture réseau - aussi nommée “castle-and-moat”108 ou “périmétrique” - reposait sur l’hypothèse que toute activité à l’intérieur du périmètre est digne de confiance et par réciprocité, que toute activité à son extérieur ne l’est pas (ex: accès réseau via un VPN ou sur base de l’adresse MAC d’une machine).
Le zero trust part du principe qu’aucun utilisateur n’est “de confiance” par défaut, qu’il se trouve à l’intérieur ou à l’extérieur du périmètre. Pour accéder aux données et aux logiciels, les utilisateurs doivent être authentifiés et autorisés. Leur activité doit être surveillée et enregistrée. Cette approche est plus efficace pour protéger les systèmes d’information contre les attaques sophistiquées, car elle ne repose justement pas sur l’hypothèse que toute activité à l’intérieur du périmètre est digne de confiance. Ce modèle de sécurisation des réseaux s’est particulièrement développée en raison du recours massif au télétravail109.
Prenons un exemple : Sophie est une employée que vous côtoyez depuis 3 ans. Elle présente son badge à l’entrée et s’installe comme tous les jours à son poste de travail. Vous apprenez quelques jours après que Sophie a été licenciée depuis 1 mois. Il se peut qu’elle ait eu accès à des informations stratégiques sur votre entreprise. Des informations qu’elle utilisera dans son nouvel emploi, chez une société concurrente. Ici, sur le simple fait d’avoir “l’habitude” de voir ce collaborateur, l’entreprise s’est faite dérober des informations précieuses. Les technologies zero trust fournissant des moyens de gestion des accès centralisés, Sophie n’aurait pas pu se connecter à sa session.
Trois piliers constituent une architecture réseau zero trust (fig.

L’idée est qu’en zero trust, chaque requête implique une nouvelle vérification de ces critères de sécurité. C’est l’intermédiaire de confiance (trust broker ou CASB110) qui vérifie ces critères (cf. OpenID, Active Directory, PKI, SAML).
Les CASB sont intégrés aux technologies dites “Zero Trust Network Access” (ZTNA) pour mettre en place une architecture zero trust. Cloudflare, Cato, Fortinet ou encore Palo Alto sont des exemples de technologies ZTNA111. Voyez-les comme des serveurs proxy avancés, qui vérifient en permanence plusieurs critères de sécurité définis par votre organisation. Si vous souhaitez mettre en place une initiative zero trust, reportez-vous au framework SASE112.
En raison du nombre d’outils à configurer, le modèle zero trust est moins simple à mettre en place qu’une sécurité périmétrique, mais il permet de surpasser ses limites113.
Au delà d’un besoin impératif de mieux sécuriser l’accès aux ressources, l’architecture zero trust contribue à la sécurisation d’une infrastructure et procure de la sérénité. Elle permet tout autant de simplifier l’administration des postes d’exploitation et des matériels réseau (administration centrale des flux réseau et des accès, plutôt qu’une configuration de chaque poste), de réduire les coûts (temps de maintenance, machines mutualisées) et de normaliser les interfaces de gestion d’identité et de droits utilisateur.
L’innovation technologique implique de s’adapter rapidement. Le zero trust permet aux organisations de s’adapter rapidement et en toute sécurité aux changements de leur environnement, sans avoir à revoir leur posture de sécurité.
Des documents de référence tels que le papier de recherche Beyondcorp de Google114, ceux du NIST115 ou de l’US Department of Defense116 donnent les spécifications pour déployer un réseau zero trust à l’état de l’art.
Dans le cadre d’un environnement de développement (R&D), le sujet se complique. Pour rester innovantes, vos équipes ont besoin de flexibilité. Elles utilisent des librairies de dernière génération, installent les derniers drivers GPU pour faire des expérimentations de machine learning ou encore testent les performances de leur logiciel en consommant totalement les ressources de leurs machines.
En résumé, vos équipes ont besoin d’un accès complet à la configuration de leur machine pour efficacement développer.
Cependant comme citée plus haut, la 3ème règle d’une architecture zero trust est de s’assurer que la machine de l’utilisateur est sécurisée. Si vous laissez les droits d’administration à un développeur, il sera toujours tenté de désactiver les paramètres de sécurité de sa machine. Donc que faire ?

Les postes de développement (fig.
Nous faisons face ici un dilemme. Nous pouvons accepter de laisser les droits complets à nos développeurs, au risque de les voir désactiver nos mesures de sécurité. Ou alors nous restreignons ces droits mais ralentissons la vélocité de leurs développements et leur possibilité d’innover, tout en devant passer plus de temps à les former à un environnement de travail atypique (puisque contrôlé).
Tout dépend de ce dont on veut se prémunir. Il faut prendre en compte les facteurs suivants :
Il existe plusieurs moyens d’adresser la problématique des environnements de développement. En voici 6 classés selon leur flexibilité pour l’utilisateur, leur complexité de mise en place et le risque qu’ils impliquent :
| Méthode | Flexibilité | Complexité | Risque |
|---|---|---|---|
| Bring Your Own Device | Maximale | Aucune | Haut |
| Machines partiellement contrôlées | Maximale | Plutôt faible | Moyen |
| Machines entièrement contrôlées avec env. de dev. cloud | Moyenne | Moyenne (Codespaces) à Haute (Coder) | Faible |
| Machines entièrement contrôlées avec VM de dev. distante | Moyenne | Moyenne | Faible |
| Machines entièrement contrôlées avec VM de dev. locale | Plutôt haute | Haute | Très faible |
| Machines entièrement contrôlées et outillées | Haute | Très haute | Très faible |
Plus l’on souhaite faire baisser le risque tout en augmentant la flexibilité (augmenter la sécurité tout en favorisant l’innovation), plus les équipes d’infrastructure auront du travail ou engendreront des coûts (ex: externalisation). Prenez en compte les facteurs inhérents à votre organisation et son mode de fonctionnement de sorte à choisir la solution qui lui correspond le mieux.
Les administrateurs d’une infrastructure manipulent régulièrement des “secrets” : des mots de passe ou des tokens. Il est courant d’avoir à se les échanger entre administrateurs. Dans d’autres cas, nous pouvons avoir besoin de partager le mot de passe d’un compte à la personne concernée. Les gestionnaires de mot de passe sont un excellent moyen pour centraliser et partager ces ressources.
Vous pouvez y gérer vos mots de passe et les partager granulairement à d’autres utilisateurs. Chacun dispose de son compte pour accéder aux secrets qu’il a le droit de voir. Il est recommandé d’en faire l’usage autant que possible.
Travailler en réseau vous permet de faire l’usage de ces outils. Voici quelques services de gestion collaborative de mots de passe : Vaultwarden, Bitwarden, Lastpass.
Le socle d’une infrastructure informatique constitue l’ensemble des technologies qui permettent d’y déployer des logiciels. Y sont souvent associés des services “cœur” communs et vitaux pour le bon fonctionnement de l’infrastructure : une PKI123, un serveur d’authentification centralisé (ex: LDAP), un serveur de temps NTP ou encore un Active Directory124.
Pour les ingénieurs ayant la charge de déployer des logiciels, le socle fournit des services communs pour éviter d’en déployer avec chacun des logiciels. Ces services étant centralisés, les tâches d’administration sont simplifiées. Dans un socle Cloud, cette idée est poussée plus loin que dans un socle traditionnel. Cela est rendu possible par l’usage de technologies standardisées qui simplifient l’interaction avec les logiciels déployés (ex: conteneurs Docker, Kubernetes).
Comparons un socle traditionnel à un socle Cloud pour mieux comprendre la plus-value de ce dernier.

Dans un socle traditionnel (fig.
La robustesse de ce type de socle n’est plus à prouver et se voit encore largement utilisé aujourd’hui parmi les grandes institutions. L’isolation est très efficace.
Néanmoins, les besoins en maintenance de ce type de socle augmentent proportionnellement au nombre de logiciels déployés. Chaque logiciel dispose de ses consignes d’installation, auxquelles s’ajoutent de la documentation de conformité au socle. L’installation et la configuration sont souvent manuelles. Or, les organisations ont tendance à installer de plus en plus de services au cours du temps, afin de continuer de répondre aux besoins métiers.
En résumé, on force ici le logiciel déployé à s’adapter au socle. Ce qui génère de la dette technique. Qui plus est, des services socle centralisés comme ceux pour gérer logs ou les métriques, n’existent pas toujours.
Ce type de socle est efficace avec un nombre raisonnable de services déployés, mais il passe difficilement à l’échelle sans une RH dimensionnée en proportion.
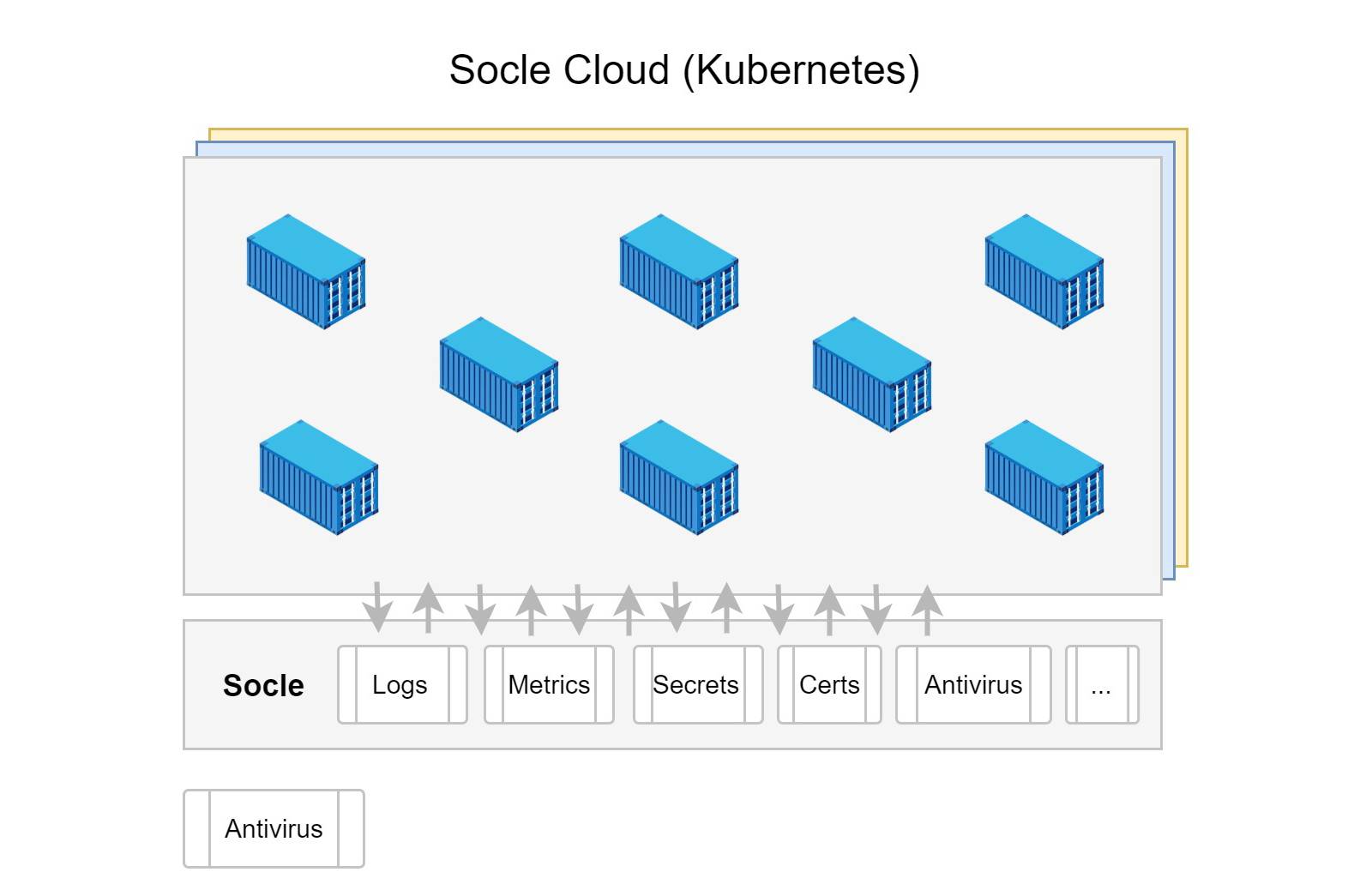
Dans un socle Cloud (fig.
Par exemple, les logs applicatifs ou les métriques de performance peuvent automatiquement être récupérés et capitalisés dans un outil central, pour ensuite configurer des alertes. Un antivirus vérifiant de manière continue la présence de menaces dans un conteneur peut être installé. C’est le mécanisme de sidecars126 dans Kubernetes qui permet de rendre ces capacités possibles.
Les flux de données entre conteneurs peuvent par défaut être chiffrés (cas d’usage: deux services qui tournent sur des serveurs différents). Les secrets (mots de passe, token) peuvent être fournis par le socle sans qu’un administrateur ne doive les voir. Les données persistantes (volumes) sont gérées de manières unifiées et leurs sauvegardes peuvent être automatisées.
L’intérêt de ce type de socle est de permettre d’intégrer tous ces services automatiquement, sans jamais toucher au code de l’application, ni même que l’intégrateur ait connaissance de votre infrastructure. Ainsi vous avez la garantie que tous les logiciels déployés se conforment à vos exigences en matière de supervision et de sécurité. C’est donc le socle qui s’adapte aux logiciels déployés.
Les mécanismes d’installation étant standardisés par Kubernetes (cf. manifests Kubernetes, Helm127), vous n’avez qu’à lancer quelques commandes pour que votre logiciel soit déployé. Kubernetes se chargera automatiquement d’instancier de nouveaux conteneurs ou des nouveaux nœuds si la charge utilisateur est trop importante. Nous approfondirons ce sujet dans le chapitre “Des extensions pour simplifier l’infrastructure”.
Si votre organisation se compose de personnels déjà formés aux technologies ESXi, ou si les règles SSI de votre organisation ne sont pas prêtes pour accueillir un socle Cloud, il reste possible de poser un cluster Kubernetes sur votre infrastructure ESXi traditionnelle. Cela peut s’envisager dans un plan de transformation au prix d’une dette technique temporairement plus importante pendant que vos équipes historiques se forment aux technologies Cloud.
En terme de sécurité, les interfaces des technologies conteneurisées sont standardisées. Il ne s’agit donc plus de devoir vérifier le contenu du conteneur car l’infrastructure s’en charge elle-même. Il s’agit de s’assurer de la sécurité de la technologie de conteneurisation (ex: Docker, CRI-O), ainsi que de celle des technologies d’orchestration (ex: Kubernetes, Rancher, OpenShift).
Par exemple, peut-être vous êtes-vous assuré que Microsoft Word était sécurisé via une homologation ? Pour autant, chaque fichier Word n’a pas besoin d’être homologué à son tour. C’est la même chose pour une application conteneurisée : qu’elle soit codée en Python, en Go, en PHP ou qu’elle embarque des librairies de dernière génération, c’est l’enveloppe qui la fait tourner qui doit être homologuée : le conteneur.
En conclusion, vous devez traiter votre socle comme un produit au service de vos ingénieurs. Plus vous mutualiserez et automatiserez le recours aux services de ce socle, moins vous devrez entretenir de dette technique (cf. chapitre “Tirer parti de l’automatisation”). À la fin, ce travail se traduit par une meilleure disponibilité des services pour vos clients.
Les micro-services étant au cœurs des infrastructures Cloud DevOps, le conteneur paraît comme la solution ultime pour déployer. Il n’y a plus besoin de machines virtuelles, puisque l’orchestrateur (ex: Kubernetes) peut s’installer directement sur la machine. C’est ce que l’on nomme une installation “baremetal”. Dans le cadre d’une transformation, il est néanmoins inoportun de mettre les VMs directement au placard.
Rares sont les cas où vous pourrez transformer du jour au lendemain votre infrastructure de production vers une infrastructure Cloud. Si vos équipes sont habituées à administrer des VMs, il leur faut le temps de se former à ces nouvelles technologies. Pour les applicatifs, il faut le temps de les faire migrer vers un format compatible.
Pour avancer, fixez-vous un objectif pour réduire l’usage des VMs. Par exemple : “dans 1 an, au moins 80% de nos logiciels devront tourner sous forme de conteneurs”. Ou encore : “tout nouveau logiciel doit être conteneurisé pour être déployé”. Cela implique de mettre en place les pré-requis évoqués au chapitre “Prérequis” ainsi qu’un outillage DevOps : une usine logicielle, des registres d’images de conteneurs ou encore un environnement de déploiement conteneurisé.
Voici plusieurs situations complémentaires où les VMs restent utiles :
Néanmoins, gardez en tête que maintenir cette couche d’abstraction (les VMs) pour n’administrer que Kubernetes dessus ajoute de la complexité à votre infrastructure. Si les pratiques évoluent dans votre organisation, envisagez de supprimer ces couches. Mais conservez la flexibilité de pouvoir en instancier au besoin.
Au sein d’une infrastructure Cloud DevOps, il est possible d’utiliser des outils comme KubeVirt ou Virtlet pour instancier des VMs dans son cluster Kubernetes. Cela peut permettre de migrer en douceur vos applicatifs historiques, tout en faisant manipuler à vos équipes les technologies Cloud. Des outils plus visuels comme OpenStack peuvent aussi aider à faire la transition vers cet écosystème, plus simplement que par les traditionnelles lignes de commande dans un terminal.
Les technologies open-source (en français : “technologies libres”) représentent 77% des librairies utilisées dans les logiciels propriétaires (ou “closed-source”)129. Parmi les 100 000 sites web les plus populaires, Linux - un système d’exploitation open-source - est utilisé dans près de 50% des cas.
Un rapport de l’Union Européenne130 indique qu’en 2018 les contributions des européens à GitHub - la plus grande plateforme de contributions open-source au monde - représentaient l’équivalent de 16 000 équivalents temps-plein. Soit près d’un milliard d’euros pour les entreprises du vieux continent. Ces contributions portent un ratio coût/bénéfice de 1 pour 4 : elles permettent aux entreprises de rester à l’état de l’art, de développer du code de meilleure qualité ou encore de réduire les efforts de maintenance.
Par exemple le navigateur Firefox, le langage de programmation Python ou le système d’exploitation Android n’existeraient pas sans l’open-source. Même le symbole du logiciel propriétaire, Microsoft, débute ses contributions open-source au kernel de Linux dès 2009. En 2014, Satya NADELLA - son nouveau CEO - annonce “Microsoft aime Linux”131. Malgré les critiques132, l’entreprise finira même par acquérir GitHub en 2018 et semble continuer de donner satisfaction à la communauté133. Elle poursuit ses contributions au profit de nombreux projets libres référencés sur son site opensource.microsoft.com.
Bien que l’usage de l’open-source soit courante dans le secteur privé, les équipes techniques de grandes organisations rencontrent parfois la méfiance de certains responsables de projet. Ces derniers expriment des préoccupations quant à la sécurité des technologies open-source utilisées par ces équipes.
Cette méfiance n’est pas dénuée de sens. L’idée d’importer la librairie d’une tierce partie au sein de son système d’information sans même regarder ce qu’elle contient est risquée. Ces risques peuvent être les suivants :
Il s’agit donc de trouver l’équilibre entre la productivité apportée par les librairies/logiciels open-source et la confiance qu’on leur accorde (sécurité).
Evitons néanmoins le piège de s’abandonner à croire qu’acheter le logiciel à une entreprise permettra de le rendre sécurisé135. Bien que la responsabilité soit déléguée, le mal - s’il se produit - sera fait. La solution se trouve donc peut-être entre l’usage de l’open-source et le recours à un tiers. Par exemple, les responsables de l’ingénierie chez Google pensent que d’ici 2025, 80% des entreprises utiliseront des technologies open-source maintenues par des personnes payées pour le faire136 (cf. GitHub Sponsors).
Jusqu’à présent, la politique officielle pour approuver l’usage de certaines librairies passait par un cycle d’homologation. Ce dernier a pour objectif de cartographier les risques apportés par l’usage d’une technologie, pour savoir si on l’accepte ou non. Le choix peut être sous-tendu par un audit de code.
Pour se protéger correctement, il faut assurer une veille active et systématique des menaces de sécurité introduites dans le code. En mode DevOps, votre usine logicielle est équipée d’outils permettant de détecter les dépendances ou le code malicieux. Vous minisez les risques en sécurisant votre chaîne logicielle (cf. chapitre “Sécuriser sa chaîne logicielle” et fiche de poste “Ingénieur SSI”).
Par exemple, si vous n’êtes pas en mesure d’installer par vous-même une forge logicielle sécurisée, vous pouvez bénéficier des fonctionnalités de GitHub (cf. chapitre “L’exemple sur GitHub”). Plus généralement, les pratiques de sécurité chez GitLab137 sont un excellent point de départ pour vous organiser.
Adhérer à une plateforme de bug bounty est une pratique commune chez les grandes entreprises. Ils le font à la fois pour analyser leurs sites web ou des logiciels libres qu’ils utilisent138. Un bug bounty est un système visant à récompenser les individus trouvant des vulnérabilités. L’objectif est d’identifier et de corriger les vulnérabilités avant qu’elles ne puissent être exploitées par des hackers malveillants. Les plateformes les plus populaires dans ce domaine sont Hackerone, Bugcrowd, Synack ou encore Open Bug Bounty.
Dans une organisation assez mature, vous pourriez même ouvrir un Open Source Program Office139 ou “Bureau de l’open-source”, en charge de définir et de mettre en place les stratégies autour de l’utilisation et de la sécurisation des technologies open-source employées dans votre organisation.
Enfin, les très grandes entreprises technologiques publient souvent de nouveaux logiciels en open-source. Ces logiciels deviennent rapidement des standards et sont utilisés par des dizaines de milliers de développeurs dans le monde. Cela permet d’acculturer facilement des ingénieurs à leurs propres technologies sans avoir à financer la démarche. Les entreprises se retrouvent ainsi avec des candidats maîtrisant déjà leurs propres technologies.
Loin de ne bénéficier qu’à ces seules entreprises, cette pratique avantage l’ensemble du secteur qui se retrouve avec une masse de candidats ayant connaissance des mêmes outils et des mêmes pratiques.
Pour exceller dans la résilience des systèmes comme dans tout domaine, il faut s’entraîner. C’est pourquoi l’une des pratiques recommandées en SRE est de s’entraîner à faire face aux incidents. Les objectifs sont les suivants :
Pour garantir que ses équipes soient bien organisées en cas d’incident, Google a conçu deux types d’entraînement140. L’objectif est de réduire le Mean Time To Mitigation (le temps moyen de résolution d’un incident, cf. chapitre “Mesurer le succès de sa transformation”), qui aurait un impact sur les contrats de service de l’entreprise.
Amazon Web Services (AWS) propose une approche nommée Game days142 similaire à la Wheel of misfortune de Google. L’entreprise liste ses services critiques et les menaces qui peuvent y être associées (ex: perte de données, surcharge, indisponibilité) pour en déterminer un scénario “catastrophe”. Par la suite, l’idée est de provisionner une infrastructure identique à la production et provoquer la panne souhaitée. Elle observe alors comment ses équipes et ses outils de production réagissent à l’incident.
Ces entraînements sont plus communément appelés fire drills. Encore une fois, leur objectif est de pratiquer sa réponse à incident face à une situation urgente. Au cours de ces entraînements, quelqu’un doit noter les éléments incomplets ou manquants dans les procédures ou outils existants, en vue de les améliorer.
Netflix y va encore plus fort avec son outil Chaos Monkey qui arrête automatiquement, de manière aléatoire et à tout moment des services en production. L’objectif est de s’assurer que les clients continuent d’avoir accès à Netflix, même avec un ou plusieurs services internes en panne. Leur outil Chaos Gorilla va même jusqu’à simuler l’arrêt d’une région AWS complète (ex: un datacentre qui serait mis hors service) pour observer ses conséquences sur la disponibilité de la plateforme. Ces pratiques font partie de ce que l’on appelle le chaos engineering.
Enfin, en dehors de logiciels d’audit qui permettent de détecter certaines failles (ex: Lynis, Kube Hunter), il existe d’autres exercices à faire pratiquer par vos équipes de sécurité et de SRE.
La manière la plus populaire d’évaluer la sécurité de son infrastructure est l’exercice “blue team / red team”. Inspirée des entraînement militaires, elle consiste en un face à face entre une équipe d’experts en cybersécurité qui tente de compromettre un système d’information (la red team), et les équipes de réponse à incident (les SRE, la blue team) qui vont identifier, évaluer et neutraliser les menaces. L’idée est d’éviter de se reposer sur les capacités théoriques de ses systèmes de sécurité, mais de les confronter à des menaces concrètes pour évaluer leur intérêt et leurs points faibles. Des variantes existent avec une purple team, une white team ou encore une gold team. Mais commencez par mettre en place un scénario simple. Par exemple : un de vos développeurs qui introduit une image Docker ou du code vérolé.
Ce sujet est vaste et les pratiques diffèrent selon la taille de l’organisation dans laquelle vous êtes employé. Ce chapitre vous donne quelques références pour entamer vos pratiques d’entraînement. Structurez-les par la suite en fonction de vos objectifs et de vos ressourcess.
Ça y est, nous atteignons le cœur du sujet. Dans ce chapitre, nous allons découvrir les différents piliers du DevOps, en décrivant les différentes pratiques et technologies qui peuvent répondre à nos enjeux.
En terme d’organisation, voyez le DevOps comme un moyen d’appliquer une “saine pression” à vos équipes, de sorte à inciter chacun à avancer dans la même direction. Il s’agit de faire communiquer tout le monde de manière optimale, au moyen d’outils techniques standardisés.
Vouloir supprimer les silos au sein de son organisation est une erreur courante. Voyons-le différemment : un silo est une concentration des connaissances, c’est une expertise.
Il est souhaitable que votre organisation intègre des silos. Ils peuvent par exemple être constitués d’experts en chimie organique, en science politique d’une certaine région du monde, ou maîtrisant une technologie spécifique.
La création d’un silo est souvent nécessaire pour répondre à un besoin d’expertise. Ce silo est nécessaire puisque cette expertise pointue a besoin d’une structure adaptée à son travail (outils et pratiques spécialisés, machines de pointe, local aux normes spécifiques). Le tout est d’avoir les outils et pratiques pour faire communiquer ce silo avec le reste de votre organisation.
Les silos indésirables se créent lorsque l’organisation ne fournit pas aux équipes les outils dont elles ont besoin pour travailler correctement. Des initiatives individuelles se créent alors pour trouver des alternatives plus efficaces. C’est une réaction “immunitaire” attendue quand des employés subissent une dégradation de leurs conditions de travail.
Par exemple, votre centre d’expertise prend de l’âge et ne renouvelle pas ses outils. Face à une charge de travail toujours plus importante et à l’inaction de l’entreprise, les employés historiques commencent à être exaspérés. Certains se découragent à l’idée de discuter avec des responsables peu réceptifs. D’autres essaient d’introduire de nouvelles pratiques, mais se heurtent à des refus catégoriques. Enfin, de nouveaux employés intègrent les équipes et constatent que leurs conditions de travail ne sont pas à la hauteur de ce qu’ils espéraient. Connaissant un logiciel redoutablement efficace, le nouvel employé l’installe. Ce dernier gagne en popularité grâce à son irrésistible efficacité et se propage dans le centre, puis dans l’entreprise. Bien sûr, l’employé n’en parlera pas à sa hiérarchie qui risquerait de lui reprocher son audace et d’interdire son nouvel outil.
Simultanément, la hiérarchie n’ayant pas anticipé le déclin ni prêté attention aux remarques internes lance un projet de transformation. En parallèle, l’initiative isolée lancée sans en informer la hiérarchie provoque des conflits de périmètre et brouille la situation. La hiérarchie perd peu à peu pied avec ses équipes, n’étant pas au courant qu’elles ont adopté de nouvelles pratiques. Le manque de communication avec le reste des collaborateurs et la duplication des efforts se font alors ressentir. C’est la conséquence d’un manque de cohérence globale. Voilà un terreau fertile pour une résistance au changement face à la réaction trop tardive de l’entité dirigeante.
Pour éviter le déclin d’un silo qui se propagera à l’échelle de l’entreprise (fig.
Le mouvement DevOps croit en l’usages de méthodologies et d’outils communs pour faciliter ces échanges. Ce chapitre décrit les méthodologies à adopter pour atteindre cet objectif.
Pour réaliser une transformation réussie, il faut avoir une vision exhaustive de son environnement de départ. Le cartographier est une étape primordiale permettant de bien comprendre dans quelle réalité vous évoluez et de se rendre compte des investissements qui vous seront demandés.
La cartographie de votre environnement doit répondre aux questions suivantes :
En ayant une vue d’ensemble claire et étayée de la manière dont est organisée l’entreprise, vous identifierez les points névralgiques sur lesquels agir. Faites de ce document votre point de départ et itérez sur les actions à entreprendre.
Imaginez quelques instants des équipes de data-scientists au sein de chacun des bureaux de votre organisation. Superbe ! Tous les métiers ont un appui technique dédié pour traiter leurs données. Mais rapidement, ces équipes d’ingénieurs discutent entre elles et se rendent compte qu’elles travaillent sur les mêmes sujets. Elles se rendent compte qu’elles développent les mêmes choses. C’est frustrant pour elles, mais cela signifie surtout pour l’entreprise qu’elle perd de l’argent.
Si personne n’a idée de ce sur quoi l’autre travaille, les efforts seront naturellement dupliqués. Dans les grandes organisations, les besoins sont souvent systémiques : les bureaux rencontrent les mêmes problèmes, à quelques détails près. Problèmes auxquels des solutions techniques mutualisées peuvent souvent répondre à 90% des cas d’usage.
En travaillant sur un réseau unique, l’ensemble de vos documents et de vos données sont mutualisés. Finies les questions du genre “Est-ce que le département Marketing m’a fourni toutes les statistiques ?”, “Où est la dernière version de cette présentation ?” ou “Où se trouve la procédure pour poser les vacances ?”. Chacun travaille de manière virtuelle au même endroit que l’autre. Il n’y a plus besoin de se demander si le contenu d’un dossier est à jour.
Les ingénieurs, eux, peuvent mutualiser les environnements techniques au lieu de re-déployer une infrastructure dans chaque bureau. Par exemple, il est inutile de dupliquer un miroir de librairies de développement sur deux machines séparées de quelques bureaux l’une de l’autre. Pour le machine learning, il est possible en réseau de bénéficier d’une puissance de calcul mutualisée en partageant les ressources d’un super-ordinateur central.
Dans de nombreuses organisations de grande taille, le principal frein à l’adoption des logiciels développés en interne est le réseau où ils sont déployés. Les équipes sont contraintes de les déployer sur un réseau différent de celui des métiers pour une question de sécurité des systèmes d’information.
Pour rendre leurs logiciels accessibles sur le réseau des métiers, l’impératif est souvent une homologation. Pour tout logiciel développé, ce processus peut prendre plusieurs mois à une année. Si ces équipes déploient des dizaines de mises à jour chaque jour, il est inenvisageable de subir ces délais (cf. chapitre “Sécurité : un nouveau paradigme avec l’approche DevOps”). À la fin, les utilisateurs que vous aurez le moins de temps d’accompagner délaisseront vos outils car l’irritant temporel deviendra trop important pour eux.
Utiliser un réseau unique est un élément clé dans l’adoption de vos nouveaux outils. Il permet à votre organisation de faire des économies et à vos collaborateurs d’être moins frustrés par les délais.
Dans le chapitre suivant, nous verrons comment s’organise une usine logicielle et comment elle permet grâce à un réseau unique, de décupler la productivité de l’organisation.
L’usine logicielle est au cœur de votre infrastructure DevOps. C’est ici que vos ingénieurs vont passer la majorité de leur temps : s’ils ne sont pas en train de coder dans leur IDE143, ils seront en train de gérer leurs projets dans l’usine logicielle.
Une usine logicielle est composée d’une forge logicielle et de services permettant à vos ingénieurs de développer et déployer des logiciels sur votre infrastructure : registre d’images de conteneurs, mirroirs de dépendances, dépôts d’artéfacts/binaires (cf. Nexus144, Artifactory145, Distribution146). Désormais, la plupart de ces fonctionnalités sont disponibles directement au sein des forges logicielles.
Les forges logicielles les plus populaires sont GitLab et GitHub. Vous aurez tendance à retrouver GitLab de manière plus courante au sein des grandes organisations, car il est simplement et gratuitement déployable sur des réseaux isolés. D’autres plateformes comme Froggit147, Gitea ou Bitbucket existent.
Comme nous le verrons dans le chapitre “GitOps”, en DevOps, tout le code source des logiciels et toutes les configurations de production sont stockées sous forme de code au sein d’une forge logicielle. On dit ainsi qu’elle est la “source unique de vérité” de votre infrastructure.
Sans forge logicielle, les équipes de développement travailleraient chacunes dans leur propre dossier local et s’échangeraient leur code sur un dossier réseau ou par clé USB. Cela ferait perdre un temps significatif lors de la fusion du code par plusieurs contributeurs différents et engendrerait de nombreux problèmes de sécurité. Inutile de dire qu’il n’y a aucun moyen de tracer les actions ni de retrouver ses fichiers en cas de suppression accidentelle. Qui plus est, les équipes de gestion de projet seraient totalement mises à l’écart du cycle de développement logiciel.
Les forges logicielles les plus populaires reposent sur la technologie git148, permettant de tracer toute contribution. Grâce à git, il est possible de savoir qui a fait quelle modification à quel moment. On peut remonter l’historique des contributions et gérer simplement la fusion des contributions. Nous détaillerons plus en détail ces mécanismes dans le chapitre suivant.
Aujourd’hui, les équipes de développement, d’administration système, de SSI et de management travaillent conjointement sur ce type de plateforme en y capitalisant :

L’objectif est de stocker dans un seul endroit le maximum de connaissances, de sorte à être certain de consulter la documentation la plus à jour (fig.
git est un moyen à considérer pour capitaliser des guides, des tutoriels et même des procédures administratives pour les équipes. Si quelqu’un observe une erreur ou une information obsolète dans une documentation, il peut directement proposer la modification dans git pour garder le document à jour.
Les équipes adoptant le DevOps remplacent les traditionnels Word ou Excel en Markdown (format des documentations dans les projets git). Ce format conçu pour être intuitif à la fois pour les humains et les machines149, est indépendant de toute technologie propriétaire (ex: Microsoft Word).
Pour connaître l’étendu des possibles : il est même possible de réaliser des présentations conçues sous forme de code. Ces dernières sont visualisables dans un simple navigateur (cf. Markdown-Slides150 (fig.
En revanche, git n’est pas fait pour stocker des fichiers lourds. On évitera d’y stocker de grandes images, des vidéos, des binaires ou des archives. D’autres technologies permettent de stocker ces types de fichiers (cf. Amazon S3154, Minio S3155, HDFS156, CephFS157, Longhorn158) sans ou avec une référence vers un projet git (ex. DVC159).
Mais l’usine logicielle ne se limite pas à la capitalisation de connaissance. Elle est aussi un point de contrôle pour toutes les contributions. Un premier niveau de contrôle se fait en ajoutant les utilisateurs aux projets auxquels ils ont le droit de contribuer.
Mais un deuxième niveau de contrôle peut être configuré : grâce aux mécanismes d’intégration continue (cf. chapitre “Intégration continue”), des scripts automatisés peuvent vérifier la validité d’une contribution en fonction de règles définies par votre organisation (qualité du logiciel, conformité SSI). Si la contribution ne répond pas à vos règles, elle est refusée. Le contributeur le voit immédiatement, sait pourquoi et peut dans les minutes qui suivent proposer une correction.
Les usines logicielles pouvant gérer l’accès aux ressources selon le profil de l’utilisateur, il est tout à fait envisageable d’ouvrir la votre à des partenaires externes (ex: prestataires). Ils pourront ainsi ajouter leurs logiciels selon les règles établies par votre organisation et sauront immédiatement comment s’y conformer. Ces dernières sont définies par des ingénieurs SSI internes.
C’est déjà le cas de Platform One160 qui ouvre son usine logicielle à des industriels contractualisant avec l’U.S. Department of Defense. Ou encore de la NATO Software Factory, l’usine logicielle de l’OTAN161.
Néanmoins, une transformation est l’occasion de développer une expertise en interne avant d’être capable de définir des règles pour les autres. Vous devez maîtriser les technologies évoquées dans ce chapitre pour maîtriser la sécurité de votre plateforme. Travaillez donc d’abord pour vos projets internes avant de contrôler des projets externes. Chaque organisation est différente mais se doit de disposer de ses propres experts en interne, pour la conseiller au mieux.
Comme décrit dans le chapitre “Revues de code”, ces dernières sont l’occasion de donner son avis sur une contribution avant qu’elle soit déployée. Il est possible d’appliquer des règles de sortes à ce que des équipes spécifiques (ex: équipe SSI) doivent approuver la contribution avant qu’elle puisse être acceptée. On peut voir ce mécanisme comme un “sceau d’approbation”. Les usines logicielles contiennent toutes ces fonctionnalités de validation des contributions, pour garantir au mieux la sécurité de la chaîne logicielle.
Enfin, c’est dans l’usine logicielle que les logiciels développés par vos équipes seront construits (compilés, mis sous un format déployable) puis déployés sur votre infrastructure. Analogues au principe d’intégration continue (CI), les chaînes de déploiement continue ont la charge de déployer en production des logiciels, selon des règles définies sous forme de code (cf. chapitre “Déploiement Continu (CD)”).
Attention : en aucun cas une usine logicielle ne permet à vos équipes de développer à proprement parler un logiciel. L’usine logicielle fournit des ressources permettant aux ingénieurs de développer leurs logiciels (dépendances, paquets, binaires) mais ne permet pas de rédiger ni d’exécuter du code en son sein.
L’usine logicielle est au développeur ce qu’est la trousse de pinceaux à l’artiste : la trousse contient tous les outils pour peindre, mais c’est sur son chevalet que l’artiste passe son temps à accomplir son œuvre. Le chevalet du développeur c’est son IDE162 sur son ordinateur : il code et lance son code pour le tester, à mesure qu’il l’écrit. Les options pour mettre en place des environnements de développement sont décrits dans le chapitre “Développement basé sur le zero trust”.
Toutes ces technologies contribuent à rapprocher les équipes et unifier les pratiques au sein de l’organisation. Nous allons découvrir dans le prochain chapitre comment les équipes techniques peuvent s’organiser pour collaborer efficacement dans une usine logicielle.
Le GitOps est une méthodologie pour les applications Cloud basée sur le déploiement continu (cf. Déploiement continu (CD)). Elle utilise des projets git comme une “source unique de vérité” pour la configuration des infrastructures et des applications. Ainsi capitalisée, la configuration est dite “déclarative”. En d’autres termes, vous “codez” des fichiers de configuration, pour définir la manière de déployer votre infrastructure.
L’idée derrière le GitOps est de se baser sur du code pour déterminer l’état souhaité du système.
La synchronisation de l’état souhaité est assurée par des technologies spécifiques (ex: ArgoCD, FluxCD). Cette approche fournit une source unique de vérité pour l’ensemble du système, ce qui facilite le suivi des changements, l’audit de la configuration et permet de s’assurer que l’infrastructure est conforme aux exigences de l’entreprise.
Exemple : si vous devez créer un mécanisme de sauvegarde, vous pourrez coder un playbook Ansible (cf. chapitre “Infrastructure as Code (IaC)”), le pousser dans un projet git et une chaîne de déploiement continue va se charger de déployer la modification. L’état final recherché est décrit par du code.
Vous pouvez commencer par rédiger des scripts d’IaC lançables manuellement, puis opter pour une solution automatisée après être monté en maturité sur ce sujet (ex: script Ansible automatisé par une chaîne d’intégration continue (CI) et dont le déploiement est confié à ArgoCD, cf. chapitre “Déploiement continu”).
Un workflow git est une méthode pour organiser les contributions au code d’un logiciel.
git permet de collaborer facilement sur du code, en apportant un mécanisme d’historisation des fichiers. Mais pour collaborer efficacement, encore faut-il s’organiser.
Imaginez plusieurs ingénieurs travaillant sur une voiture dans une chaîne d’assemblage. Robert travaille sur le démarreur pendant que Caroline s’assure que les phares répondent correctement aux commandes. Mais quand Robert éteint la voiture, Caroline ne peut plus mesurer le courant. Robert et Caroline n’arrivent pas à travailler ensemble, en même temps.
A cause d’une urgence personnelle, Robert doit partir rapidement et il se fait remplacer par Marie. Malheureusement, Robert n’a pas eu le temps de communiquer à Marie où il en était. Elle doit donc deviner la situation, à partir de ce qu’elle a devant les yeux.
C’est pareil en développant des logiciels. En travaillant au même endroit au même moment, on entre en collision. Dans git, quand deux personnes travaillent sur le même fichier et tentent de le fusionner, cela provoque un “conflit”. Il faut un minimum d’organisation lorsque l’on développe un projet. A défaut, le risque est d’engranger de la dette technique et de se retrouver avec un logiciel impossible à faire évoluer.
git fonctionne avec un principe de branches. Par défaut, seule la branche principale main ou master existe. Elle est la branche considérée comme “stable”. Si un intégrateur doit déployer un logiciel en production, il choisira le code présent sur cette branche.
Un développeur qui souhaite concevoir une nouvelle fonctionnalité va créer une nouvelle branche à partir de la branche principale. Il se retrouve avec une copie du code dont les modifications (commits) sont à sa discrétion, sans déranger les autres. Une fois la fonctionnalité finalisée, le développeur peut faire une “demande de fusion” (merge request) vers la branche principale. La figure
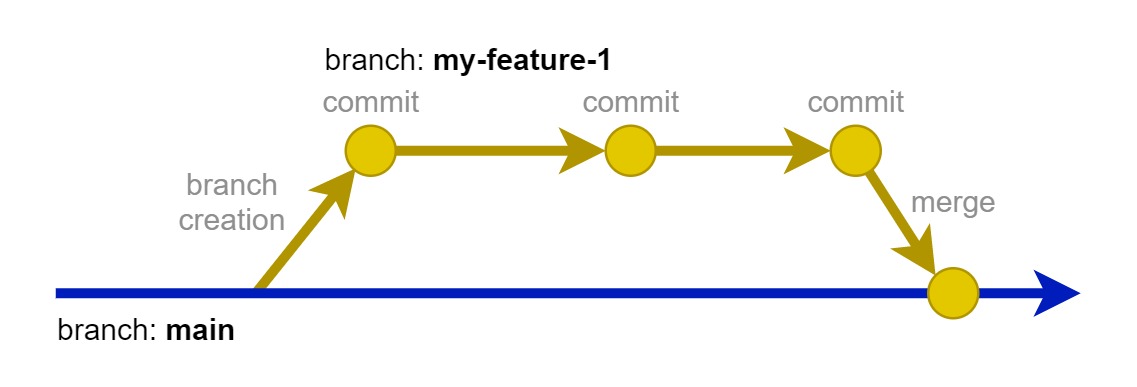
Il y a trois questions à se poser pour déterminer un “bon” workflow git :
Plusieurs méthodes ont émergé au cours du temps163 mais il en existe 4 principales :
Release Branching : Adaptée au déploiement périodique d’un logiciel (release), cette méthode consiste à créer une nouvelle branche à partir de la branche principale, puis à la stabiliser avec des corrections de bugs et d’autres changements avant publication.
Ici, une release correspond à une branche qui évolue longtemps en parallèle de la branche principale, puis devient éventuellement dépréciée au bout d’un moment.
Elle permet à des groupes de développeurs de travailler ensemble sur une release en particulier ou une version personnalisée du logiciel pour un client. Cela limite les conflits mais complexifie l’unification des contributions entre versions.
Gitflow : Extension de la méthode Release Branching, celle-ci utilise 6 branches164 vivant en parallèle et adressant des besoins précis (release, hotfix, feature, support, bugfix en plus de la branche principale master ou main). Elle est historiquement utilisée pour gérer de très grands projets (fig.

GitHub flow / GitLab flow : Cette méthode élimine la complexité apportée par le Gitflow en supprimant ces 5 branches parallèles à la branche principale (fig.
Un développeur doit créer une branche par nouvelle fonctionnalité, à partir de la branche principale. Une release peut être créée à n’importe quel moment à partir de la branche principale. Au delà de sa simplicité, l’intérêt est d’avoir une branche qui contient un code fonctionnel en permanence et de savoir qu’il est à jour à tout moment.

Trunk-based : Cette méthode favorise le déploiement en continu d’un logiciel (cf. chapitre “Déploiement continu”).
Contrairement au GitHub flow, chaque développeur pousse ici son code directement dans la branche principale (le trunk, fig.
Cette méthode s’appuie fortement sur les mécanismes de CI/CD car chaque contribution est contrôlée (CI). Si les contrôles sont validés, le logiciel peut être automatiquement mis à jour (CD) en créant une release. Vous vous assurez ainsi que les mécanismes de mise en production (CD) fonctionnent à tout moment.
A l’échelle, il est néanmoins conseillé de créer des branches de très courte durée pour notamment profiter des revues de code (maximum 1 jour). Le principe est très similaire au GitLab flow mais en s’imposer des branches de très courte durée, là où les branches en GitLab flow peuvent exister plus de temps.
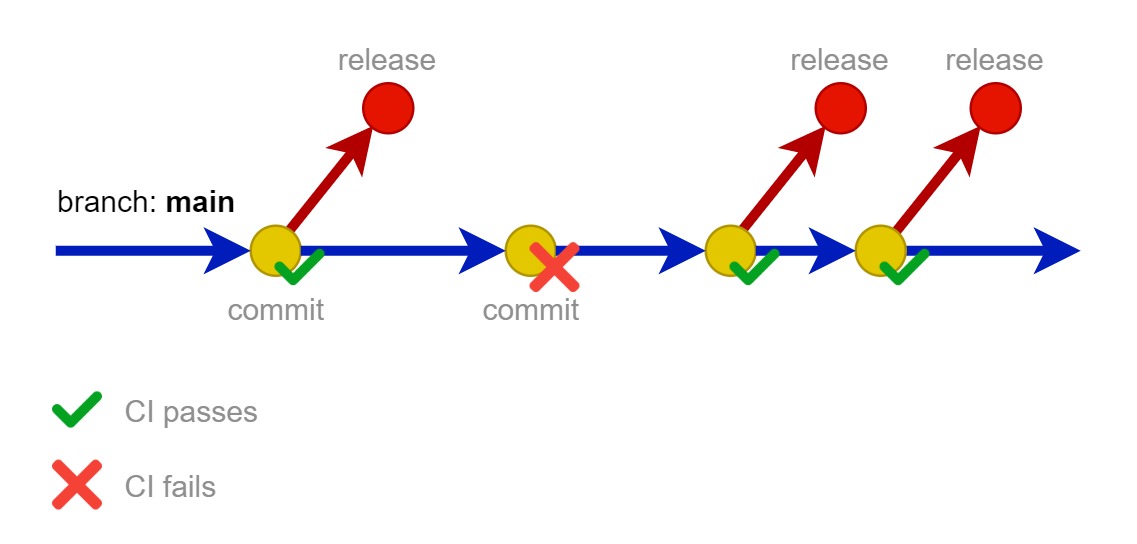
Selon Atlassian, le workflow git à l’état de l’art est aujourd’hui le trunk-based development165. La base de code de Google est un bon exemple : malgré des dizaines de milliers de contributions quotidiennes, c’est cette méthode qu’elle a choisie166.
Néanmoins, vous n’avez peut-être pas les équipes d’ingénieurs de Google. Le trunk-based development implique une rigueur particulière que seule une équipe technique éxpérimentée peut assumer. Cette méthode nécessite des chaînes d’intégration continue qui vous assurent que le code poussé est valide (au risque de publier une version du logiciel qui ne fonctionne pas). Elle implique aussi la création de chaînes de déploiement continu optimisées (car régulières). Écrire ces chaînes prend du temps et requiert de l’expérience.
Si vous ne disposez pas d’une équipe outillée en conséquence, il est recommandé de rester sur du GitLab flow167.
Mais respecter une méthodologie commune de contribution (branches, commits) n’est pas suffisant. Vous pouvez désormais plus facilement collaborer mais n’êtes pas en mesure de bien comprendre où en est chacun. Dans le chapitre suivant, nous allons découvrir une méthode d’organisation prenant en compte la gestion de projet.
Vous n’avez peut-être pas à votre main une grande équipe mais souhaitez bénéficier des bonnes pratiques d’organisation sur votre projet git. Ce chapitre est l’occasion d’en apprendre plus sur une méthode adaptée à la majorité des équipes de développement. C’est celle que j’utilise pour la vaste majorité de mes projets : professionnels ou personnels.
S’inspirant du meilleur de plusieurs méthodologies Agile (Scrum168, Extreme Programming, Kanban169), elle emprunte leur pragmatisme sans inclure leur lourdeur organisationnelle. Cette méthodologie conviendra davantage à une organisation en transformation, par rapport au trunk-based development plus exigeant. Les responsables SSI y sont également plus favorables car elle fixe des versions logicielles et facilite la maintenance de projets de toute taille sur le long terme. Enfin, elle permet aux responsables de projets autant qu’aux développeurs de suivre simplement les développements.
Nommée “Flexible flow” (fig.

Pour faire le lien entre gestion de projet et contributions techniques, les projets GitLab ou GitHub utilisent des issues. Ces dernières sont des tâches assignables à un collaborateur, permettant de décrire quelle fonctionnalité développer ou quel bug résoudre (fig.
.")
En Flexible flow, toute contribution doit faire référence à une issue qui décrit la genèse de la tâche, comment elle peut être résolue et centralise les réflexions des parties prenantes. N’importe qui peut créer ces tâches (responsable projet, développeur, utilisateur). C’est le responsable du projet qui les priorise ensuite. Tout développeur nouvellement attribué doit savoir : quoi faire, où commencer et pourquoi, en consultant l’issue. Chacune est numérotée automatiquement par la forge logicielle.
Gestion de projet :
Utiliser la vue Kanban de sa forge logicielle
Créer quatre colonnes : Open, To do, Doing, Done
Créer et documenter les issues (tâches) dans la colonne Open
Créer les labels de type de contribution : type/bug, type/feature, type/iteration, type/refacto, type/documentation, type/discussion
Permet aux équipes de comprendre la nature de la contribution à faire.
Créer les labels pour les domaines de contribution : area/backend, area/frontend, area/documentation, area/cloud (Docker, Kubernetes, CI/CD), area/infrastructure (Ansible, Terraform, configuration AWS/GCP/Azure)
Permet aux équipes spécialisées de savoir quelle tâche traiter. Par exemple sur GitLab, chaque équipe concernée par un label peut s’y “abonner” pour savoir quand une nouvelle tâche est ajoutée.
Créer les labels de valeur métier : business-value/p1, business-value/p2, business-value/p3, business-value/p4
Permet de prioriser les tâches selon la valeur métier qu’apporte la réalisation de la tâche :
p1correspond à une priorité métier élevée.p4correspond à une priorité métier faible.
Créer les labels de complexité : complexity/1, complexity/2, complexity/3, complexity/4
Permet de prioriser les tâches selon la complexité et le temps que nécessite la tâche :
1correspond à une tâche peu complexe.4correspond à une tâche très complexe ou longue.
Créer les labels de priorité : priority/low, priority/medium, priority/high, priority/critical
Permet de prioriser les tâches selon le contexte actuel du développement du projet (priorités politiques et/ou client).
Pour chaque issue, attribuer un label de chaque catégorie (domaine, type, valeur commerciale, complexité, priorité)
Ordonner les issues selon la priorité : plus une issue est en haut dans la colonne Open, plus elle est importante
Attribuer une issue à un collaborateur et la déplacer dans To do
Limiter l’attribution à 1 issue par collaborateur disponible : permet de concentrer les efforts.
Eventuellement, créer une milestone pour grouper les issues qui doivent être réalisées pour une version précise du logiciel. Une milestone est la plupart du temps associée à une date de sortie d’une version du logiciel (dead line).
Gestion des contributions :
main/master unique de laquelle les développeurs peuvent partir pour ajouter une contributionf/#65-add-users-profile-page pour l’issue n°65 de type feature et ayant pour nom “Add users profile page”package.json) et créer une release à partir de la trunk branchAutres recommandations :
Mot de l’auteur : Cette méthode a démontré son efficacité au cours du temps pour les projets auxquels j’ai contribués. Simple de prise en main même pour les débutants, je l’ai affinée au cours du temps pour qu’elle soit moins lourde à utiliser, tout en permettant de répondre aux problématiques de dette technique des logiciels et de turn-over des équipes.
Pour présenter cette méthodologie à vos équipes et retrouver facilement les références, accédez à son illustration en pleine résolution171.
Les technologies Cloud apportent une flexibilité indéniable et donnent la possibilité de servir toujours plus de clients par rapport aux technologies traditionnelles. Mais passer d’un logiciel monolithique à un applicatif capable de passer à l’échelle, nécessite de respecter quelques règles lors de sa conception.
La méthodologie à 12 critères (Twelve-Factor Methodology) regroupe une liste de bonnes pratiques pour créer des applicatifs adaptés aux plateformes Cloud. Elle constitue la synthèse de l’expérience vécue par Adam WIGGINS et ses ingénieurs à Heroku. L’objectif est d’éviter “l’érosion logicielle”172, un phénomène définit par la lente détérioration des logiciels au fil du temps, qui finissent par devenir défectueux ou inutilisables. En d’autres termes, cela permet de créer des applications plus faciles à maintenir, à déployer, à mettre à l’échelle et plus résistantes aux pannes.
Le site Internet 12factor.net, créé par Adam WIGGINS, liste et détaille ces règles :
package.json pour NPM (Javascript) et les requirements.txt pour PIP (Python). Elles doivent être isolées pendant l’exécution pour s’assurer de ne pas avoir de dépendances déjà installées sur la machine. Par exemple en utilisant les virtualenv Python, le bundle exec dans Ruby ou Docker pour tout langage.mysql://auth@host/db qu’à mysql://[email protected]/db sans changement dans le code, du moment où les technologies sont les mêmes.2022-05-07-21:33:18) et rendre immuable le code pour cette version. Toute modification du code requiert une nouvelle release.SIGTERM (graceful exit).stdout) et ce dès que possible (sans mémoire tampon). Cela permet à la plateforme Cloud de facilement traiter les logs des applicatifs déployés (cf. chapitre “Un socle au service de votre résilience”).psql ou encore déclencher une sauvegarde avec une commande). L’idée est de permettre l’exécution de scripts, dans le même environnement que celui où est déployé le logiciel.Ces critères - et en particulier le découpage des logiciels en micro-services - couplés à des chaînes de déploiement continue, augmentent de 43% les chances d’anticiper les incidents logiciels selon la recherche175 (ex: pannes, vulnérabilités ou performances de service dégradées). La conteneurisation est particulièrement adaptée à ces pratiques. En effet, les notions d’isolation y sont récurrentes et une technologie comme Docker peut facilement y répondre.
Bien qu’elles soient aujourd’hui des pratiques standard dans l’industrie, il peut être utile de les inclure dans un guide pour vos nouveaux arrivants.
Une manière simple mais particulièrement efficace pour rapprocher les silos, est d’instaurer une messagerie instantanée commune. Les collaborateurs peuvent par ce biais échanger rapidement au lieu de surcharger leur boite mail, faire des discussions de groupe sur la prochaine fonctionnalité à développer, s’échanger des bouts de code ou des documents facilement, favoriser la cohésion en partageant des memes, faire des annonces générales ou encore réaliser des sondages pour trancher sur une liste de choix. Au delà de fluidifier la collaboration, la messagerie rend possible le travail en mobilité ou avec des équipes décentralisées (dans d’autres villes ou pays).
Dans le cadre de l’amélioration de la fiabilité des systèmes, la messagerie est l’endroit parfait pour centraliser les alertes de la production à l’attention des équipes SRE. Les outils de surveillance des systèmes peuvent être configurés pour lever des alertes à un endroit unique. Les SRE sont immédiatements notifiés lorsqu’une alerte est émise. Bien configurées, ces alertes contient toutes les informations pour que le SRE puisse corriger au plus vite le problème. Les équipes de production peuvent également communiquer facilement avec leurs utilisateurs les actions qu’ils effectuent sur la production.
Les messageries telles que Mattermost, Element, Zulip ou Slack intègrent par défaut la VoIP (appels) et la visioconférence. La plupart intègrent aussi nativement la connexion à des logiciels utilisés par la production (ex: notification automatique à chaque release GitLab, incident report in chats, mises à jour sur la status page, chronologie du postmortem; cf. Rootly).
De nombreuses entreprises comme Scaleway ouvrent leurs messagerie d’entreprise à leurs clients. Elles constituent alors une communauté d’entraide et une base de connaissance pour les nouveaux utilisateurs. Cela favorise l’engagement et rassure ceux qui n’ont pas encore franchi le pas, en sachant qu’il y aura quelqu’un pour leur répondre en cas de problème. Les utilisateurs se confrontant à un soucis posent leur question, auquel un utilisateur ou un expert de l’entreprise pourra répondre. Chez Canonical et Prefect, il existe même des “ingénieurs de la communauté” (Community Engineers) dont le rôle est précisément d’aider la communauté face aux problèmes qu’elle peut rencontrer176. Certaines entreprises préfèrent faire entièrement payer ce soutien utilisateur.
Les grandes organisations sont souvent frileuses à l’idée de proposer du télétravail à leurs employés. Le risque, selon elles, est que l’employé ne travaille pas sur les sujets de l’entreprise.
Si vous devez convaincre votre hiérarchie, listez clairement les objectifs de l’employé en télétravail (en vous appuyant sur les arguments du chapitre “Former de manière continue”). Si cela ne suffit pas, vous pouvez par exemple lui proposer que l’employé écrive un compte rendu sur son travail en fin de journée. Mais cela revient à dire au collaborateur “je ne te fais pas confiance sur ton sérieux”. Réfléchissez-y à deux fois.
La recherche177 a démontré qu’un environnement de travail flexible était associé à une baisse de burnout et une augmentation des chances que l’employé recommande son entreprise.
Connaître les différentes architectures logicielles vous aidera à bien comprendre comment les logiciels sont déployés dans les architectures Cloud.
En fonction de votre maturité organisationnelle et de la taille de vos équipes, certaines rendront vos logiciels plus simples à maintenir, à mettre à jour ou plus résilients dans la durée.
Ce chapitre présente trois architectures célèbres et décrit leurs avantages et inconvénients. Enfin, nous verrons comment réaliser progressivement la refonte de vos logiciels historiques en micro-services.
Une application monolithique (conçue comme un monolithe) est développée comme un tout unique et indivisible, où chaque fonction ou module est interconnecté. Les composants du logiciel sont dépendants les uns des autres.
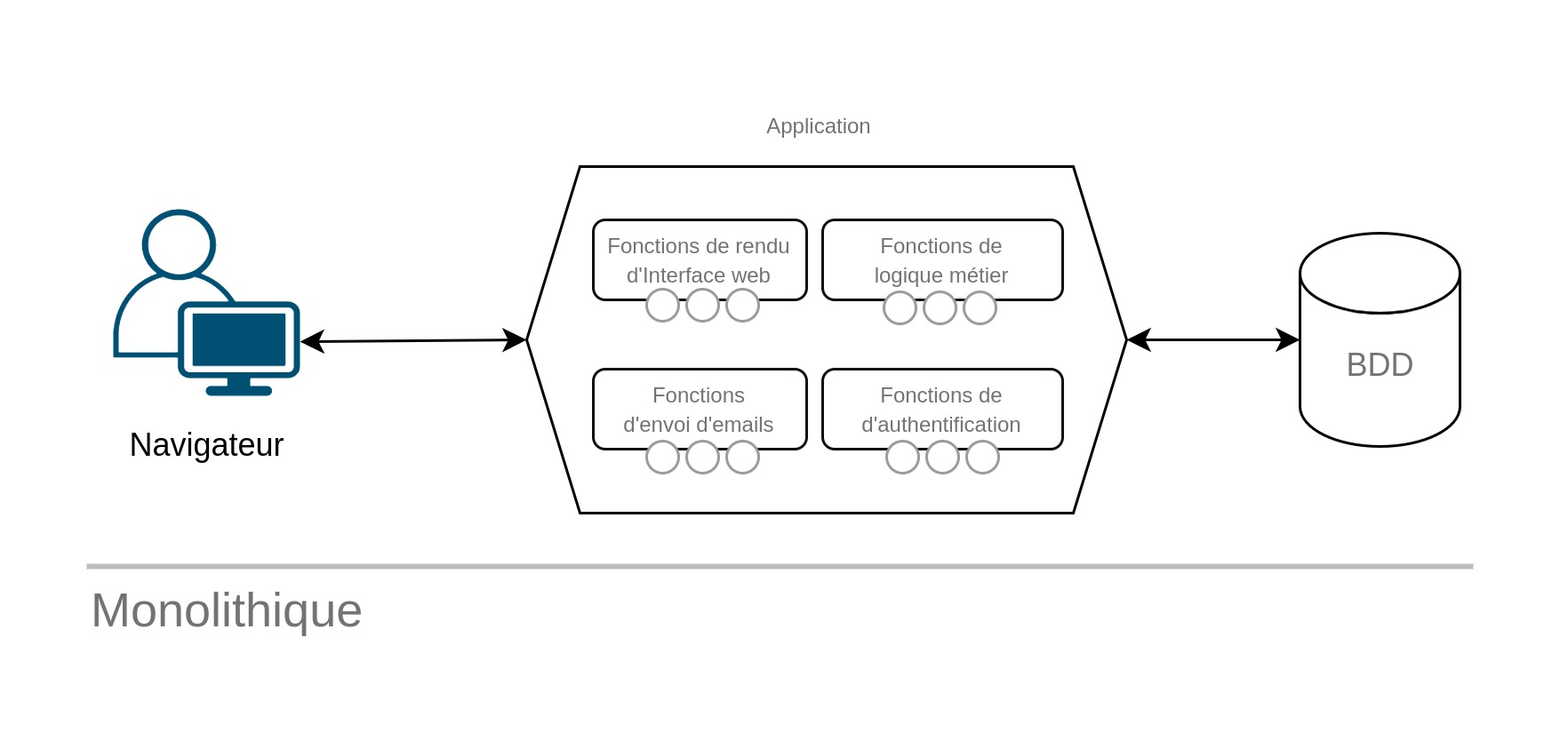
Plus simples à développer et utiliser dans un premier temps, les logiciels conçus comme des monolithes rendent complexe l’ajout de nouvelles fonctionnalités à mesure qu’ils grossissent178.
Les mises à jour apportées à une partie du système affectent l’ensemble de l’application, ce qui nécessite des batteries de tests importantes pour s’assurer qu’elle fonctionne comme attendu lors du déploiement. Le “rayon d’explosion” d’un bug (blast radius en anglais) est très important dans ce type d’architecture.
De nombreux logiciels réputés comme Wordpress et Magento utilisent encore aujourd’hui une architecture monolithique. Mais la tendance se porte vers les architectures en micro-services, plus adaptées à la montée en charge et plus résilientes179.
Une application conçue en micro-services décompose chaque fonctionnalité d’un logiciel en services isolés (ex: gestion de l’envoi des e-mails, gestion de la connexion, gestion des commandes). Chacun s’exécute de manière indépendante. Chaque microservice communique avec les autres grâce à un format d’échange prédéfini (une API180) et les mises à jours peuvent être déployées sans perturber l’ensemble du système.

En divisant votre logiciels en micro-services, vous pouvez paralléliser le travail des équipes sur chaque partie de votre logiciel. Chacune développe et déploie indépendamment.
Mais l’un des grands avantages des micro-services est de pouvoir passer à l’échelle simplement : les services les plus sollicités peuvent être instanciés plusieurs fois et simultanément pour répartir la charge. Certains orchestrateurs de services comme Kubernetes permettent d’automatiser ce comportement181.
Cependant, cette architecture demande des outils avancés pour maintenir des centaines de micro-services communiquant entre eux. Les équipes DevOps facilitent la mise en place de ce type d’architecture. Par exemple, ils outillent les développeurs avec des modèles d’applications (templates / boilerplates) embarquant tout ce qu’il faut pour bien démarrer une application en micro-services, sur sa propre infrastructure.
Pour permettre un passage à l’échelle sur des fonctionnalités plus précises, les architectures dites “sans serveur” (ou serverless en anglais) ont émergé. L’intérêt par rapport aux approches traditionnelles en micro-services est multiple :
On y retrouve des technologies de Function as a Service ou FaaS182, de Container as a Service (CaaS), les serverless compute platforms ou SCP183, les services de stockage auto-gérés184 ou encore les services de messagerie auto-gérés185.
En ne facturant les ressources que lorsqu’elles sont utilisées, le serverless représente un argument économique et écologique de taille. Ces technologies peuvent vous faire passer d’une facture de dizaines d’euros à quelques centimes chaque mois.
Par exemple, les Functions as a Service représentent chacune une fonctionnalité isolée de votre microservice. Si vous savez que seulement 10% de vos fonctions sont utilisées 90% du temps, inutile de payer pour 100% des ressources en permanence.
Prenons un cas précis : vous décidez de démarrer une campagne marketing d’emailing. C’est alors précisément la fonction d’envoi d’emails qui va être sur-sollicitée pendant un court instant. Il n’y a ici pas besoin de passer à l’échelle la fonction qui liste vos produits. L’infrastructure ne provisionnera des instances que de la fonction d’envoi d’emails.
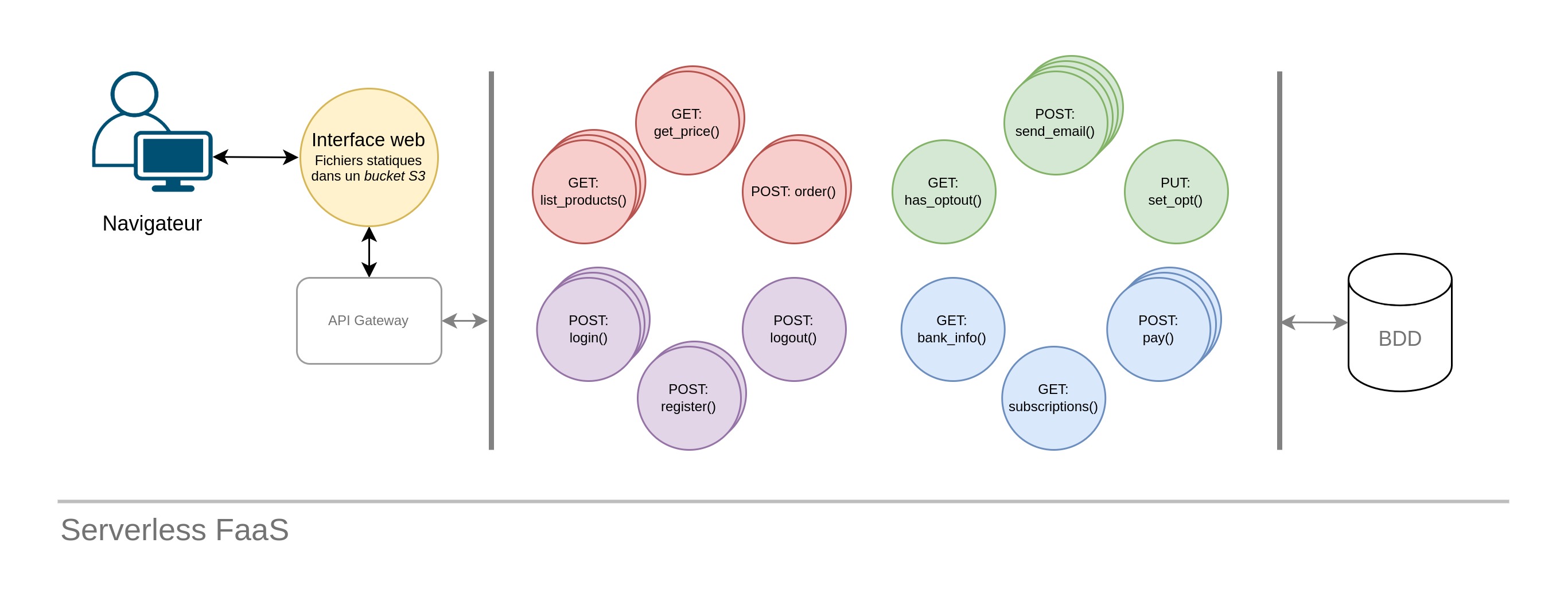
Néanmoins, les architecture serverless demandent des compétences spécifiques pour les maintenir. Elles peuvent aussi vous lier aux technologies propriétaires d’un fournisseur Cloud (cf. enfermement propriétaire ou vendor lock-in186) ou faire exploser les coûts si le cas d’usage n’est pas approprié187.
Récapitulons quelques avantages et inconvénients de chaque approche :
| Archi-tecture | Avantages | Inconvénients |
|---|---|---|
| Mono-lithique | • Simplicité de développement et de déploiement • Gestion centralisée • Facile à tester et débugger |
• Difficile à passer à l’échelle • Un bug peut affecter tout le logiciel • Déploiements plus lents et moins fréquents |
| Micro-services | • Passable à l’échelle sur demande • Déploiements rapides • Bugs et crashes isolés • Agnostique au langage de programmation |
• Compétences spécifiques pour les gérer • Cohérence des formats de données à maintenir (API) • Plus difficile à débugger |
| FaaS | • Pas de gestion de l’infrastructure • Passable à l’échelle ciblé • Rentable pour une affluence sporadique |
• Enfermement propriétaire • Moins de contrôle sur l’environnement d’exécution • Temps de démarrage si inutilisée (cold start) • Durée d’exécution limitée |
La marche à franchir est souvent haute pour passer d’un logiciel monolithique à une architecture en micro-services. Néanmoins, cette approche apporte une flexibilité sans précédent dans les développements et rend le passage à l’échelle drastiquement plus efficace. Mais comment réaliser cette transition sans chambouler toute votre activité ?
Prendre la décision de passer en microservice est tentant mais implique des compromis. L’ingénieur logiciel et auteur britannique Martin FOWLER nous éclaire sur les pré-requis dont votre équipe doit disposer avant de démarrer l’aventure188 :
En sommes, nous parlons ici des technologies Cloud et des techniques DevOps. À ce stade, vous souhaitez seulement valider le processus de développement d’un microservice et savoir le déployer automatiquement.
Pour vous entraîner à créer des micro-services, découplez une première fonctionnalité qui n’a pas besoin d’être modifiée partout dans votre logiciel. Par exemple, le mécanisme d’authentification d’une application est souvent centralisé dans une classe ou une fonction : créez et interfacez ce microservice.
La bataille d’Alésia, menée pendant la guerre des Gaules en 52 avant J.-C., est souvent citée comme un exemple de planification militaire stratégique. L’armée romaine de Jules César s’oppose alors à l’armée gauloise de Vercingétorix. Repoussé par les germains - alliés des romains - le chef militaire gaulois est contraint de se réfugier avec 80 000 hommes dans l’oppidum d’Alésia. Jules César décide d’ériger deux lignes fortifiées autour de la ville pour déloger l’armée gauloise.
Ce stratagème permettait à Jules César de contrôler les entrées et sorties de la zone, pour maîtriser la quantité de soldats arrivant d’une part de l’oppidum, et d’autre part de l’extérieur où les renforts affluaient.

Sans nous considérer comme de grands chefs militaires, nous pouvons néanmoins utiliser cette stratégie pour contrôler d’une part la charge utilisateur, et d’autre part les flux soit vers le monolithe, soit vers les micro-services que nous allons progressivement créer.
C’est la deuxième étape de l’aventure : mettre un proxy ou un service mesh autour de notre application (cf. chapitre “Service mesh”). Il nous permettra de rediriger chaque requête soit vers les nouveaux micro-services, soit vers le monolithe pour les fonctions qui n’ont pas encore été migrées. Par exemple, si l’on choisit d’extraire les fonctionnalités d’authentification vers un microservice, nous redirigerons les requêtes commençant par /auth vers le microservice d’authentification.
Une nouvelle règle doit désormais être instaurée en parallèle de la transformation que vous opérez : toute nouvelle fonctionnalité doit être développée sous forme d’un microservice.
Ex-directrice des technologies émergentes chez Thoughtworks, l’ingénieure Zhamak DEHGHANI nous offre de précieux retours d’expérience dans son article “Comment décomposer un monolithe en micro-services189”. Passons-en quelques-uns en revue.
L’un de ses premiers conseils est d’éviter la création de micro-services qui vont rappeler le monolithe. Il faut au contraire privilégier les appels du monolithe vers les micro-services.
L’objectif est d’éviter un cercle vicieux de modifications qui ne vont qu’enrichir le monolithe. Voilà pourquoi il faut rapidement s’attaquer au coeur du logiciel. Commencez par en découper les fonctions les plus intégrées et qui traitent les données principales de votre projet.
Priorisez le découpage des fonctions difficiles à découpler par domaine logique (ex: la gestion des produits puis celle des commandes). Puis concentrez-vous sur les parties du logiciel les plus fréquemment mises à jour.
Enfin, envisagez la réécriture complète d’une partie du code. Parfois, le code historique est trop complexe, trop lent, trop différent de la stack technique actuellement utilisée et nécessite une bonne mise à jour. Il convient alors de réfléchir s’il n’est pas préférable de le réécrire. N’hésitez pas, surtout s’il manque de clarté.
Ces quelques notions et conseils vous permettront d’appréhender avec sérénité vos travaux de réécriture de votre logiciel pour mieux l’intégrer dans une infrastructure Cloud et bénéficier de l’agilité qu’elle procure pour votre organisation.
Vous devez vous organiser pour accueillir l’échec comme une opportunité de corriger votre trajectoire, vers une meilleure direction. Si vous subissez un échec important, c’est que vous n’aviez pas assez d’éléments pour contrôler la situation.
À l’aide d’outils et de méthodologies incontournables dans le domaine, ce chapitre vise à vous faire comprendre l’intérêt d’une culture d’entreprise qui accepte l’échec. Elle vous permettra de mieux anticiper les risques, pour en prendre davantage en toute sérénité et augmenter votre vélocité.
Cet état d’esprit est un changement culturel qu’une organisation doit instiller en son sein, dans toutes les strates hiérarchiques.
« La sécurité psychologique est la culture selon laquelle une personne ne sera pas punie ou humiliée pour avoir exprimé ses idées, questions, préoccupations ou erreurs. » - Amy C. EDMONDSON, professeure en gestion et leadership à la Harvard Business School.
La culture d’une organisation est le fondement de son potentiel. Une bonne culture aide à promouvoir la collaboration et la communication entre les équipes, atout fondamental pour une mise en œuvre réussie d’une initiative DevOps. Cette idée n’est pas nouvelle, et fut théorisée en 2004 par le sociologue Ron WESTRUM dans son article “Une typologie des cultures organisationnelles”190.
En prenant soin de la sécurité psychologique de vos employés, vous favorisez le partage du sentiment de responsabilité pour le succès et les échecs. Des succès et des échecs partagés, plutôt qu’attribués à des équipes ou des acteurs individuels.
Dans un environnement de travail ne tenant pas compte de la sécurité psychologique, les collaborateurs :
Comme l’indique Kiran VARMA dans son cours sur la culture SRE chez Google191, la recherche192 a démontré qu’il existe deux facteurs principaux alimentant la tendance des individus à blâmer les autres : le biais rétrospectif et la “décharge d’inconfort”.
Le biais rétrospectif est la tendance d’un individu à surestimer sa capacité d’avoir été capable de prédire un évènement. Les humains ont souvent du mal à réaliser qu’une idée est devenue évidente seulement à partir du moment où elle s’est produite. Par exemple, vous pourriez dire en fin de match que vous saviez pertinemment qu’une équipe de foot allait perdre seulement parce-que vous l’avez annoncé en début du match. Dans le monde professionnel, cela peut mener à blamer la personne en charge de réaliser une tâche en disant qu’elle aurait “bien pu prévoir la chose évidente” qui allait se passer.
La notion de “décharge d’inconfort” fait référence au phénomène neurobiologique selon lequel nous blâmons les gens pour nous décharger d’une douleur mentale. La sociologue Brené BROWN déclare que les humains le font contre leur gré, naturellement, mais que blâmer entrave notre capacité à apprendre de nos erreurs193.
Dans une organisation qui n’est pas à l’aise avec l’échec, les collaborateurs auront tendance à cacher des informations ou ne pas déclarer d’incident car ils craindront d’être punis. Pour la même raison ou par peur d’être considérés ridicules, ils auront peur de poser des questions pouvant mener à identifier les causes d’un problème. Or, les erreurs ne sont des opportunités de s’améliorer que si leurs causes véritables sont identifiées. Ceci n’est possible que dans un environnement de travail psychologiquement sûr.
Une organisation qui tient compte de la sécurité psychologique considère que :
Cet état d’esprit permet d’établir la confiance. L’idée est de remplacer les questions du genre “Qui a fait ça ?” par “Qu’est-ce qu’il s’est passé ?”. L’organisation doit se concentrer sur ses méthodes et ses procédures, pas sur les individus. La meilleure pratique consiste à supposer que les collaborateurs agissent de bonne foi et prennent leurs décisions à partir des informations les plus pertinentes dont ils disposent. Enquêter sur la source d’une information erronée est plus bénéfique pour l’entreprise que d’attribuer l’erreur à quelqu’un.
L’innovation requiert un certain degré de prise de risque. Il n’y a pas de nouveau produit ou de nouvelle stratégie ayant 100% de chance de réussir. Donc si tout le monde a peur à l’idée de prendre un risque, personne n’en prendra et votre organisation ne sera plus en mesure d’innover.
Un tas d’autres modèles de décision194 et de gestion de projet195 existent, n’hésitez pas à vous en inspirer.
En découvrant la multitude de technologies expérimentales à mettre en place pour atteindre un fonctionnement en mode DevOps, vous pourriez prendre peur à l’idée de devenir le responsable de ce grand et nouveau système.
Ce chapitre vise à comparer un modèle de responsabilité traditionnel avec le modèle DevOps. Il propose aussi un outil permettant d’éclairer le décideur, le DACI. Libre à vous d’y sélectionner les méthodologies qui vous semblent les plus opportunes pour votre organisation. Néanmoins, soyez assez audacieux et tentez d’éviter de retomber dans un modèle traditionnel, qui ne vous donnerait que l’illusion de vous transformer.
L’un des modèles de partage des responsabilités est le “RACI”, pour Responsible (Exécutant), Accountable (Responsable), Consulted (Consulté) et Informed (Informé). Il permet de s’assurer que toutes les parties prenantes sont conscientes de leurs rôles et de leurs responsabilités dans un projet.
Dans le tableau suivant, nous avons cinq parties prenantes pour le développement d’un nouveau site web. Un responsable, un exécutant (personne en charge de la réalisation), des consultés et des informés sont désignés pour chaque activité.
| Livrable du projet (ou activité) | Responsable du projet | Architec -te | Design -er | Développeur front-end | Développeur back-end |
|---|---|---|---|---|---|
| Conception du plan du site | C | R | A | I | I |
| Direction artistique | A | C | R | C | I |
| Conception des maquettes | C | A | R | I | I |
| Structure du code (template) | A | I | C | R | C |
Une extension du RACI est le RACI-VS196 qui inclut un validateur (la personne en charge de la validation finale du livrable, une autorité) et un signataire (personne en charge de l’approbation officielle du livrable et qui engage sa signature, une haute autorité).
Le modèle RACI repose sur une séparation claire des rôles et des responsabilités. Cela peut être contre-productif dans une initiative DevOps, qui cherche à promouvoir une collaboration entre les équipes. De plus, le RACI ne tient pas compte de la nature dynamique et en constante évolution du développement d’un projet.
Dans un modèle DevOps, tout le monde peut contribuer à un projet. Tout le monde est responsable au même niveau selon son domaine d’expertise. Une modification significative - par exemple pour le lancement d’une nouvelle version d’un logiciel - nécessite l’approbation de chaque équipe (de l’équipe de design, en passant par le marketing, l’ingénierie et la sécurité).
Bien sûr, on évitera de demander à l’équipe SSI de nous donner son avis sur le changement de couleur d’un bouton… Mais l’idée est qu’il n’y a pas un seul responsable ou un seul exécutant : tout le monde est responsable et peut valider ou invalider une modification selon les règles et contraintes du moment.
Le RACI tel qu’utilisé dans les grandes organisations joue le rôle d’arbitre. Une équipe spécifique est désignée pour réaliser des tâches spécifiques. Or le DevOps est un ensemble commun de pratiques qui ne vont pas l’une sans l’autre. Et si vous visez à faire évoluer plusieurs équipes de l’organisation, le RACI peut avoir un effet pervers et décourageant. Il peut être le prétexte pour une équipe A, de ne pas s’intéresser au sujet de l’équipe B, sous prétexte que ça n’est pas dans ses responsabilités.
Pour pallier ce phénomène tout en continuant de rassurer vos responsables, les livrables du RACI peuvent dans un premier temps être élargis. Par exemple, on ne fera pas référence à “un mécanisme qui récupère les logs applicatifs” mais à un “ensemble d’outils pour faire de l’observabilité”. Cela n’empêche pas de définir des sous-objectifs plus précis, mais la responsabilité doit rester vaste. Si certains ne jouent pas le jeu, le RACI peut les contraindre à faire le travail, mais ils ne sont probablement pas les bons membres à associer à votre projet.
En tant que meneur d’une initiative impliquant technologies et pratiques inédites, votre hiérarchie vous demandera de vous engager sur de nombreuses lignes du tableau ci-dessus. Prenez cette responsabilité pour rassurer vos autorités197. Vous n’avez rien à craindre puisque vous savez que la méthodologie que vous voulez mettre en place est collective et itérative.
La plupart du temps, il n’est pas souhaitable de se séparer immédiatement d’un modèle type RACI. C’est une question de culture à faire évoluer et d’outillage à mettre en place. Mais c’est bien cela que vous devez viser : un changement de culture dans votre organisation pour que les autorités surpassent leurs peurs.
En assumant des responsabilités partagées sans les imputer plutôt que de trouver un coupable, vous vous concentrez sur l’amélioration du service afin d’atteindre l’effet final recherché (ex: une infrastructure plus stable). Fort de ce principe, analysons alors une réflexion qui peut nous venir à l’esprit.
Vous l’aurez compris, le DevOps incite à ne pas blamer les parties prenantes. Il est naturel de rétorquer alors que si personne n’est personnellement responsable, les équipes risquent d’être moins attentives dans leurs responsabilités quotidiennes. Comment imaginer un responsable de la production qui supprimerait l’ensemble de la base de données client sans conséquence ? Les responsables doivent bien à un moment comprendre que leurs actions ont des conséquences. Le DevOps répond de deux manières à cet enjeu :
Voilà pourquoi il faut commencer avec des moyens, mais avoir l’audace de commencer petit dans son initiative de transformation. Votre entreprise doit progressivement mettre en place les procédures (dans notre cas, les technologies de contrôle des systèmes informatiques) selon ses moyens RH et financiers. Une fois que vous avez éprouvé ces techniques, itérez à plus large échelle.
Le DACI n’est pas un moyen de définir les responsabilités pour un projet. C’est un document et une méthode pour s’organiser ponctuellement, dans l’objectif de prendre une décision de groupe face à plusieurs options. On l’emploie généralement pour faire en sorte qu’une décision soit prise en fin de réunion. Considérez-le comme un outil, appuyant la démarche de partage des responsabilités en mode DevOps.
Une réunion sous le modèle DACI implique la désignation de quatre rôles :
Ensuite, l’objectif est de discuter ensemble pour lister en quelques mots les options envisagées. Indiquez pour chacune leur coût, le temps qu’elle nécessitera et autres avantages ou inconvénients.
Dans les 5 minutes restantes, définissez la date à laquelle la décision doit être prise (si ce n’est pas tout de suite). Fort de ces ébauches d’options, s’il en reste à étayer, distribuez la tâche à celui en charge de la réaliser.
Une fois les options regroupées, les approbateurs prennent la décision et l’autorité distribue les tâches à l’issue.
Exemple de DACI, listant les options considérées pour une prise de décision sur la problématique “Comment devrions-nous finaliser les spécifications de notre produit ?” :
| Critères | Option 1: Groupes de discussion / Groupes de discussion de persona198 cibles rémunérées | Option 2: Revues internet / Équipe interne d’experts en contenu | Option 3: Ne pas finaliser / Ne rien faire pour adresser le problème pour le moment |
|---|---|---|---|
| Stratégiqu -ement fiable / priorité haute | (+) Cibles ancrées dans la stratégie = retours ancré dans la stratégie | (+) 2 nouveaux membres d’équipe correspondent au persona = quelques retours ancrés dans la stratégie | (-) Risque d’erreur importante ou coûteuse, (-) Risque de prise de délais ou de confusion |
| Centré sur l’utilisateur / priorité haute | (+) Retour précis de clients | (-) Biais d’expert | (-) Naviguer à l’aveugle |
| Coût / priorité moyenne | (-) Plus coûteux sur le court-terme, (-) Chronophage | (+) Pas de coût supplémentaire, (+) Relativement rapide à mettre en place, (-) Prend du temps à l’équipe | (+) Pas de coût supplémentaire, (+) Option la plus rapide |
| Opportunité d’en apprendre plus / priorité faible | (+) Opportunité d’en apprendre plus sur nos cibles | (+) Opportunité d’apprendre des retours de nos experts inter-équipes |
Exemple d’emploi du modèle DACI pour trier avantages & inconvénients et prendre une décision (dans ce cas l’option 1). Traduit depuis l’anglais. Source : atlassian.com
Une fois votre décision prise, il est temps de la communiquer pour que tout le monde soit informé. Envoyez le document aux personnes qui doivent en prendre connaissance puis archivez-le.
Une fois archivé, il permettra aux nouvelles parties prenantes du projet de comprendre pourquoi telle ou telle décision a été prise. En menant cette réflexion collective vous évitez également les biais cognitifs individuels.
Vous recevez un message d’alerte du support client sur Slack. Elle vous informe que votre plateforme de partage de fichiers est indisponible.
C’est dès ce moment que commence l’investigation du problème. La technique la plus courante est la root cause analysis (RCA) : une méthode inspirée des techniques de contrôle qualité dans l’industrie manufacturière. Elle permet de comprendre de quels facteurs provient l’incident et d’en déterminer la source. L’objectif est alors de mettre en place les procédures pour que cet incident ne se reproduise pas.
En RCA, vous devez en priorité rétablir les services. En suit une action pour résoudre le problème de manière pérenne. Enfin, une action préventive est mise en place pour que le problème ne se reproduise pas à l’avenir.
Par exemple, dans le cas d’une cafetière défectueuse :
Pour faire comprendre à votre hiérarchie l’intérêt de cette méthode, présentez-la comme un investissement pour gagner du temps et de l’argent199. La RCA réduit les risques de refonte logicielle, coûteux en temps. Priorisez vos efforts de RCA sur les incidents qui coûtent le plus à votre organisation. La mise en place de procédures et la conservation des connaissances sur la résolution des incidents permet aussi d’améliorer la communication entre vos équipes. Au lieu de réagir en appliquant de simples rustines, l’idée est de trouver une solution pérenne.
Voici les 5 étapes de la Root Cause Analysis :
Identifier le problème
Analysez la situation pour vous assurer qu’il s’agit bien d’un incident, pas d’une simple alerte sans conséquence. L’entreprise doit déterminer un seuil pour qualifier un incident, par exemple une anomalie qui dure plus de 1 minute. Si l’évènement menace la stabilité de vos indicateurs de résilience, considérez-le comme un incident.
Dans le doute, la bonne pratique est de déclarer les incidents tôt et souvent. Il vaut mieux déclarer un incident, puis trouver un correctif rapidement et le fermer, plutôt que de le laisser perdurer et qu’il s’aggrave. Si un incident majeur se déclare, vous devrez probablement le gérer en équipe (cf. chapitre “Organiser sa réponse à incident”). Vous pouvez distinguer un incident majeur d’un plus mineur si vous répondez “oui” à l’une de ces questions :
Dès que l’incident débute, commencez à prendre des notes sur ce que vous allez observer et les actions que vous allez entreprendre. Cela sera utile pour votre postmortem. Vous pouvez ensuite qualifier le problème en utilisant la méthode “5W2H” (5 quoi/what, 2 comment/how) :
| Interrogation | Description |
|---|---|
| Qui ? | Personnes ou clients affectés par le problème |
| Quoi ? | Description ou la définition du problème |
| Quand ? | Date et l’heure à laquelle le problème a été identifié |
| Où ? | Localisation des plaintes (zone, équipement ou clients en question) |
| Pourquoi ? | Toute explication connue antérieurement |
| Comment ? | Comment le problème est-il survenu (cause racine) et comment il va être corrigé (action corrective) |
| Combien ? | Gravité et fréquence du problème |
Sur les infrastructures matures, l’identification d’un problème est facilitée par la présence de systèmes de surveillance de la plateforme. Ils remontent sous forme de notification les anomalies qu’ils détectent. Par exemple, ces anomalies peuvent être détectées par des outils comme Statping, qui déclenchent une alerte quand un service devient indisponible. Mais elles peuvent également être détectées par des mécanismes de machine learning, qui révèlent des tendances anormales. L’avantage est que l’alerte n’est pas lancée uniquement quand un simple seuil est franchi, mais quand un phénomène inhabituel se produit.
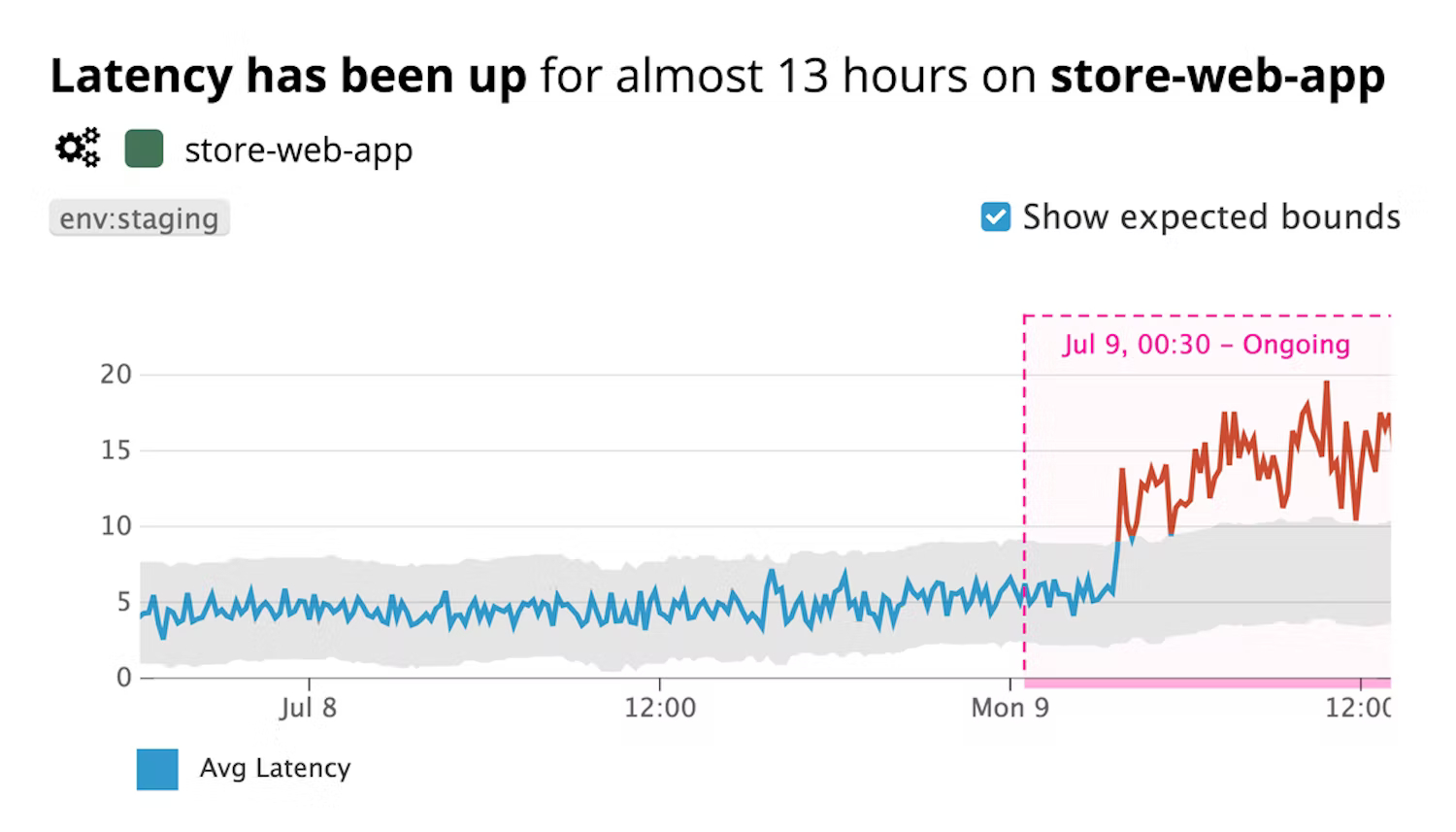
Des outils comme OpenRCA, OpenStack Vitrage ou Datadog peuvent vous aider à identifier la cause d’un problème en mettant en évidence les anomalies au sein de votre infrastructure.
À cette étape, vous ne connaissez pas la gravité du problème, seulement ses symptômes.
Contenir et analyser le problème
Toujours commencer par résoudre le problème. Rétablir au plus tôt le service pour éviter qu’il ne dégénère, même si la solution est temporaire ou qu’elle n’est pas considérée “propre”.
La confiance que vos utilisateurs portent à l’égard de votre service est liée à votre réactivité. Vos utilisateurs ne s’attendent pas à 100% de disponibilité, mais ils s’attendent à une communication claire en cas d’incident. Cette transparence est fondamentale.
Une page d’état des services (status page en anglais), est un excellent moyen d’informer vos utilisateurs de l’état d’avancement d’un incident (fig.
À chaque mise à jour du statut de l’incident, communiquer sur :
Pour analyser le problème plus en détail et trouver la source du dysfonctionnement, utiliser ses outils d’observabilité (journaux d’activité, métriques).
La suite Beats de Elastic est un exemple d’outil permettant de surveiller une infrastructure. Nous découvrirons l’étendue de ces technologies dans le chapitre “Tout mesurer”.
À cette étape, vous devez trouver une action immédiate. Par exemple, un industriel fabriquant des pièces pourrait décider de ré-inspecter celles prêtes à l’expédition, les retravailler ou faire un rappel. Pour un logiciel, l’idée est de trouver une manière de rétablir le service, souvent en poussant un correctif rapide (hotfix en anglais).
Votre équipe SRE doit s’assurer que les correctifs déployés fonctionnent. Ils peuvent le faire en lançant des tests pilotes200 qu’ils auront préparé.
Définir la cause du problème
L’impact de l’incident étant contrôlé, on peut désormais investiguer la cause racine du problème.
Listez en équipe les facteurs probables contribuant au problème. Structurez ensuite vos hypothèses avec un diagramme de cause à effet (ou diagramme d’Ishikawa, fig.
Choisir par un vote à majorité les causes qui vous semblent les plus susceptibles de se reproduire. Selon la loi de Pareto, 80% des effets sont produits par 20% des problèmes. Vous avez désormais identifié un axe de réflexion.
Utiliser la méthode des “5 Pourquoi” (5 Why’s). L’idée est d’identifier plusieurs symptômes en cascade, jusqu’à trouver la cause racine d’un problème. “5” est une valeur arbitraire, elle peut être réduite ou agrandie selon le cas.
Voici un exemple pour le problème identifié “Notre logiciel plante fréquemment” :
| Question | Réponse |
|---|---|
| Pourquoi ? | Parce que la mémoire utilisée augmente au cours du temps |
| Pourquoi ? | Parce qu’il y a une fuite de mémoire dans le code |
| Pourquoi ? | Parce que les développeurs ne libéraient pas correctement la mémoire après l’avoir allouée |
| Pourquoi ? | Parce qu’ils n’étaient pas au courant qu’il était possible que leur programme ait une fuite de mémoire |
| Pourquoi ? | Parce qu’il n’y avait pas de chaîne d’intégration continue le vérifiant |
Résoudre le problème de manière pérenne
En ayant déterminé quelle était la cause racine du problème, il faut maintenant concevoir une solution pour en résorber la cause.
Vérifier que la solution peut fonctionner en réalisant une preuve de concept avant de l’appliquer en production.
Définir et rédiger les actions qui seront prises pour corriger le problème, qui en est responsable et quand cela sera fait.
Définir comment l’efficacité de la solution sera mesurée : par sondage téléphonique, sondage en ligne, mesures remontées automatiquement, mesures prises manuellement… Définir un temps pendant lequel mesurer l’action, puis appliquer la correction.
Valider le correctif et faire en sorte que l’incident ne se reproduise pas
Fort de vos mesures définies à l’étape 4, s’assurer que les actions entreprises ont eu l’effet désiré.
L’incident est désormais résolu et vous savez pourquoi le problème est survenu. C’est le moment d’informer vos utilisateurs sur la status page : “L’analyse de la cause du problème est terminée, l’incident a été résolu, l’incident est documenté”.
Il ne reste plus qu’à rédiger votre postmortem, en y inscrivant ce que vous avez fait pour vous assurer que le problème ne se reproduise plus (cf. chapitre “Postmortems”). Reprendre ici les notes prises aux points précédents et formalisez ce document.
Publier et communiquer ce document (en interne de l’entreprise ou au public). Cela permettra aux clients d’être satisfaits en étant mis au courant, et aux équipes gérant la production de voir leur travail reconnu.
Tout comme les pilotes d’avion qui s’entraînent à faire face à une situation d’urgence, vos équipes SRE doivent s’entraîner pour ne pas perdre de temps quand un incident se produit (cf. chapitre “Évaluer sa sécurité et s’entraîner”).
Leur procédure de réponse à incident doit être simple à trouver et être rédigée à l’attention de tout public. Elle doit à la fois inclure les consignes pour les équipes SRE, mais aussi pour tout non-SRE qui se retrouverait face à un incident. Quelle que soit la taille de votre organisation, vous devez disposer d’une procédure de réponse à incident.
Le postmortem est une technique d’investigation des incidents. Elle permet de tirer des conclusions sur les actions à prendre pour qu’ils ne se reproduisent pas. Le postmortem se traduit par un document formalisé par votre équipe SRE, qui le rédige à partir des informations récoltées pendant la root cause analysis (cf. chapitre “Investiguer les incidents”).
Dans le milieu militaire et en aéronautique, le RETEX (retour d’expérience) est systématiquement pratiqué à la suite d’un évènement pour en tirer des enseignements. Le postmortem est quant à lui seulement déclenché lorsqu’un incident ou un échec s’est produit. Voilà donc ce qui les distingue.
Il est recommandé de stocker ces documents dans un projet git pour être en mesure de les éditer et de visualiser leurs modifications au cours du temps (cf. chapitre “GitOps”). Ma recommandation personnelle est de les rédiger au format Markdown.
Historiquement, le terme latin “post mortem” signifie “après la mort” et définit le processus d’investigation réalisé par les forces de l’ordre pour comprendre en quoi un crime a pu se produire. Pour cela : elles analysent les preuves, identifient la cause du décès (ex: via une autopsie), puis tentent d’emprisonner le coupable ou d’adapter la loi pour que le problème ne se reproduise plus. L’idée est similaire pour les incidents informatique.
La structure que recommande Google201 est un bon exemple. Le document est composé de deux parties : une qui décrit ce qu’il s’est passé et une autre décrivant les mesures à mettre en place suite à cet incident.
Ouvrez un nouveau document Markdown et nommez-le de cette manière :
aaaammjj_postmortem_résumé-incident_durée.md20230604_postmortem_ptg-fichier-indispo_00j00h38m.mdPour la première partie, définissez les titres suivants :
La deuxième partie décrit ce que votre équipe pourrait faire différemment la prochaine fois. Conclusion de votre postmortem, elle liste les actions à prendre pour que les problèmes ne se reproduisent pas. Ne vous concentrez pas uniquement sur la correction des bugs. Incluez aussi les changements de procédure nécessaires pour réduire l’impact d’incidents similaires.
Définissez un tableau avec quatre colonnes et autant de lignes que souhaitées :
Si votre équipe ou vos projets commencent à s’agrandir, il pourrait être nécessaire de structurer plus formellement vos postmortems. Le modèle de postmortem proposé par Atlassian est un bon exemple202.
Pour les incidents mineurs ou les bugs que vous rencontrez au quotidien, utilisez un service de question/réponse (Q&A) comme Scoold ou question2answer. Il peut référencer des problèmes techniques (ex: “Comment résoudre un conflit de dépendances”) ou des questions plus générales (ex: Q: “Je n’arrive pas à me connecter au service X”. A: “Avez-vous pensé à vous inscrire à cette URL ?”).
Grâce ce type de logiciel, vos SREs disposeront d’une liste de problèmes facilement résolubles à l’avenir. Alternative privée à StackOverflow, il permet aussi à vos développeurs de poser des questions aux autres collaborateurs de l’entreprise, en toute confidentialité.
Comme évoqué dans le chapitre “Investiguer les incidents”, rendre public ses travaux permet de voir son travail reconnu par la communauté. Cette pratique améliore aussi la fidélisation en permettant au collaborateur de développer sa notoriété.
Le vidéaste Bastien MARÉCAUX (connu sous le pseudo Basti UI) introduit la notion de “télétralive”, mix de “télétravail” et de “live”. Il diffuse publiquement des sessions de travail en direct sur la plateforme Twitch, pour ses clients l’ayant accepté203. Cela démontre l’importance que peut apporter le fait de publier son travail. Une tendance qui pourrait prendre de l’ampleur à l’avenir.
Au delà de l’intérêt personnel, diffuser son travail à un public averti incite l’auteur à fournir un travail de qualité204. Il s’agit dans un premier temps de le publier uniquement en interne,à l’usage des collaborateurs de l’entreprise. Un simple message mentionnant l’existence du postmortem dans la messagerie de l’entreprise peut suffire.
La transparence est aussi un excellent moyen d’attirer les talents. Dans l’industrie, les entreprises ayant le courage de documenter et publier leurs incidents sont reconnues fiables. En effet, elles n’ont pas peur de le faire car leurs procédures sont sérieuses et leurs travaux faits avec soin. Cela donne confiance et inspire les talents.
De nombreuses entreprises telles que Spotify, LinkedIn, Meta, Airbnb ou Capgemini partagent des articles sur leur blog respectif. Il peut être sujet de postmortems, mais aussi présenter de bonnes pratiques internes ou des défis surmontés.
Par exemple, Cloudflare est reconnue pour ses postmortems de qualité qu’elle publie régulièrement sur son blog205. Des lettres d’information comme SRE Weekly répertorient également des incidents publics chaque semaine.
Un postmortem public est souvent moins fourni qu’un postmortem interne. Dans le premier cas, on ne fera qu’un résumé du second, en enlevant les parties sensibles.
Quand l’incident est d’ampleur, il est impératif de s’organiser pour y faire face efficacement. Une technique efficace est celle des 3 Commandants (3 Commanders ou 3Cs). Théorisée en 1968 par les pompiers sous le nom de système de commandement des incidents (Incident Command System, ICS)206, elle a été adaptée aux incidents informatiques. Ajourd’hui, elle est utilisée par les équipes SRE de Google207.
Lorsqu’un incident important se produit, il faut réussir dans l’urgence à coordonner les tâches, résoudre l’incident et communiquer. Le tout en même temps. Imaginez devoir conduire une voiture en même temps que de trouver votre chemin sur une carte.
Ouch ! Le serveur gérant l’authentification de vos employés sur l’intranet vient de tomber en panne.
Pour gérer la situation, désignez 3 personnes pour les 3 rôles suivants :
Dans les petites équipes, l’IC occupe souvent les 3 rôles. Mais vous devez être préparé à déléguer ces tâches en cas d’incident grave.
La définition et l’organisation des rôles doit faire partie de votre procédure de réponse à incident. Veillez à ce qu’elle soit clairement définie dans votre base de connaissance pour que vos équipes sachent comment réagir. Veillez à entraîner vos équipes pour répondre efficacement à de potentiels incidents (cf. chapitre “Évaluer sa sécurité et s’entraîner”). Vous pouvez faire en sorte que vos équipes soient régulièrement entraînées en définissant un seuil d’alerte bas. Elles seront alors davantage confrontées à vos procédures de réponse à incident.
Communiquer est essentiel, que ce soit auprès de vos clients ou de vos équipes internes. À l’occasion d’un incident de grande envergure, Datadog pointe dans son postmortem208 l’importance de communiquer tôt les pannes, à la fois à ses clients et ses équipes internes. Voici quelques enseignements qu’ils ont su en tirer :
Dans le cas d’un incident n’étant pas encore totalement identifié et affectant différemment vos clients (ex: selon leur localisation ou le produit utilisé), la règle est de communiquer sur le problème ayant les “pires symptômes”. Pour éviter de frustrer vos clients et de passer trop de temps à communiquer sur chaque zone ou chaque produit, vous devez décider de communiquer au plus tôt, sur la zone ou le produit le plus impacté. Par exemple, si la zone “UE” a des symptômes plus importants que la zone “US” de vos datacentres, communiquez sur les symptômes de la zone “UE” : vous ne savez pas encore si la panne est globale, si elle va se propager ou si elle n’impacte qu’une seule zone. Indiquez clairement que la zone “US” est possiblement impactée de la même manière que la zone “UE”.
Lors d’un incident d’ampleur, de nombreux clients peuvent ouvrir des tickets. Des ingénieurs “support” sont alors assignés à ces tickets pour répondre à des clients en détresse. Sans communication claire en interne pour que vos ingénieurs support sachent quoi dire à vos clients, vos équipes et vos clients vont chacun commencer à s’impatienter. Veillez à disposer d’un canal de communication interne auxquels tous vos ingénieurs support ont accès (ex: canal Slack, document Google Docs) pour qu’ils sachent quoi répondre à leurs clients et sans discours contradictoire.
De manière plus générale, l’entreprise a découvert avec le temps qu’informer ses clients une fois toutes les 30 minutes était la fréquence idéale. Les équipes techniques peuvent ainsi se concentrer sur la résolution du problème sans être dérangées trop souvent pour communiquer.
Nous allons découvrir dans ce chapitre deux techniques pour anticiper autant que possible les incidents : le premortem et l’analyse de cause à effets.
Si plusieurs approches sont envisageables, effectuez d’abord un DACI (cf. chapitre “Le modèle DACI”). Une fois votre choix effectué, l’équipe a une orientation sur l’approche à mener : c’est le moment de la mettre à l’épreuve avec le premortem.
L’analyse de cause à effets intervient elle sur les considérations techniques, une fois que la décision sur l’approche à adopter ait été prise.
En amont du lancement d’un projet, vos chefs de projets et ingénieurs doivent se réunir pour lister les hypothèses de son échec.
Le premortem est aussi connu sous le nom “d’étude des cas non conformes”. Le stratège militaire Sun TZU préconisait déjà en l’an cinq avant Jésus-Christ de planifier un maximum de scénarios de guerre possibles (de “cas non conformes”) en amont d’une bataille, dans son écrit L’art de la guerre209.
C’est une méthodologie de gestion de projet qui consiste à imaginer que le projet a échoué, avant même qu’il ne commence. Il se traduit par un document listant les incidents susceptibles de contrecarrer le projet, auxquels l’équipe doit se préparer.
Prenons un exemple : “Notre équipe administre aujourd’hui ses infrastructures avec des méthodes traditionnelles. Nous voulons établir un plan pour travailler en mode DevOps.”
Voici un autre exemple plus technique : “Notre équipe déploie ses logiciels avec Docker Compose. Elle veut maintenant les déployer avec Kubernetes.”
La RCA (root cause analysis) est une méthode dite “réactive” : elle est menée après qu’un problème survienne. Pour tenter d’anticiper les défaillances avant qu’elles ne surviennent, il est possible de réaliser une analyse des modes de défaillance (failure modes and effects analysis ou FMEA). Créée en 1949 par l’armée américaine210 puis reprise dans l’industrie automobile, elle est une méthode dite “proactive”.
Le résultat de cette analyse est un tableau listant les états d’erreur d’un produit ou d’un logiciel, priorisés par risque. En fonction des conséquences qu’un risque peut produire, les équipes de conception priorisent le développement des mécanismes à mettre en œuvre afin d’empêcher qu’il se produise.
En FMEA, il est possible de représenter visuellement une cause susceptible de provoquer une situation d’erreur (fig.

On peut ainsi établir une chaîne de causes à effets, pour mieux se représenter les conséquence d’un problème. Prenons comme exemple la figure
Vous pouvez faire de même avec des scénarios de dysfonctionnement d’un logiciel ou d’une infrastructure. Etablissez un tableau de 7 colonnes. Pour chaque hypothèse d’incident, l’auteur doit déterminer :
A partir de ce tableau, priorisez les tâches de vos équipes pour qu’elles travaillent à anticiper les situations les plus critiques.
Pour la maintenance d’une infrastructure, l’une des bonnes pratiques est de créer des “fiches incident”. Chacune inclut un scénario de panne, associé aux pistes à explorer pour la résoudre. Exemples typiques de pannes : manque d’espace disque, base de données mal migrée, sauvegarde mal exportée. Capitalisez-les dans votre base de connaissance (ex: GitLab, Confluence).
Si vous êtes une petite structure, commencez par formaliser vos procédures pour mener une RCA et par rédiger des postmortems. Ensuite, établissez progressivement des FMEA et tentez de commencer vos projets par des premortems. Enfin, réalisez périodiquement des FMEA.
Le choix d’investir du temps dans la réalisation de premortems, de FMEA ou de postmortems reste régit par vos priorités en terme de résilience. La recherche démontre néanmoins que l’indisponibilité d’un service peut coûter cher aux grandes organisations, en atteignant en moyenne 500’000 à 1’000’000 de dollars par heure d’indisponibilité211.
Le DevOps est souvent présenté comme un mode d’organisation disruptif, c’est à dire un changement de paradigme dans les technologies et les pratiques. Pour éviter d’intimider les parties prenantes à votre transformation, présentez plutôt le DevOps comme une évolution des technologies traditionnelles.
Par exemple, Windows 10 (sorti en 2015) n’est qu’une évolution de Windows NT 3.1 (sorti en 1993) et comporte encore du code datant des débuts de l’architecture Windows NT (conçu en 1988)212.
Voici quelques parallèles concernant le Cloud :
Les VMs traditionnelles ont aussi leur place dans une infrastructure Cloud DevOps. Elles peuvent en faire partie (cf. chapitre “Abandonner les VMs ?”).
À ces évolutions technologiques s’ajoutent des méthodologies pour maîtriser la dette technique, accélérer les déploiements et maintenir un niveau de résilience élevé : une forge logicielle, le gitops, l’intégration continue, le déploiement continu, les postmortems… C’est le DevOps.
En définissant les méthodologies vues dans ce livre et en utilisant des technologies dont l’administration est standardisée (ex: Kubernetes), vous diminurez à terme les coûts d’administration.
Comme évoqué dans le chapitre “Être au plus proche du métier”, il est courant de ne pas répondre au besoin initialement exprimé avec les méthodes traditionnelles. Figer le besoin à l’instant T n’est pas un moyen fiable de livrer le produit attendu. Le besoin évolue continuellement et le client ne sait souvent pas exprimer exactement ce dont il a besoin.
La méthodologie Agile vise à réduire ce risque en proposant plusieurs cycles courts de livraison (sprints). À chaque cycle, le client fournit ses retours. Cette boucle est rejouée jusqu’à ce que le projet convienne au client ou que le contrat prenne fin. Le DevOps vient outiller l’entreprise pour fluidifier les interactions. Dans les entreprises les plus performantes, les sprints ne sont plus qu’un détail contractuel pour échanger sur les avancées : le logiciel, lui, est déjà en production et prêt à être utilisé.
Cette méthodologie a l’avantage d’éviter de traiter une demande figée. Certains sont convaincus de la manière dont le logiciel devrait être conçu pour qu’il réponde le mieux à son besoin. Or la suggestion faite n’est peut-être pas l’option la plus adaptée. Au cours de vos différentes livraisons, le client aura toujours une suggestion à faire ou un détail qu’il aura oublié de vous communiquer. Ces détails - plus ou moins grands - s’accumulent avec le temps et peuvent engendrer des délais.
Si un logiciel est voué à changer en profondeur les habitudes de son utilisateur, le livrer tôt est nécessaire pour qu’il s’acculture progressivement aux changements qui vont lui être imposés. Il pourra par exemple faire évoluer ses procédures internes, recruter les profils adaptés et préparer sa stratégie de communication. Cela évitera les frustrations et permettra de garantir un livrable au plus proche du besoin métier.
Se passer de cette approche si votre client est trop exigeant peut parfois mener à des projets perdurant des années. Voire même à abandonner des projets. Cela ne manquera pas d’engendrer des frustrations réciproques entre le responsable d’équipe, l’équipe de développement et le client.
L’humain est la première cause d’erreur. C’est pour cela que l’automatisation est un élément fondamental d’une organisation en mode DevOps. Les chaînes d’intégration et de déploiement continu sont particulièrement efficaces pour fluidifier le cycle de livraison logiciel.
Si vous ressentez actuellement une lenteur dans votre cycle de production, vous avez probablement besoin d’investir du temps pour automatiser. Dans les entreprises matures, des équipes dédiées au développement d’outils d’automatisation au profit des équipes de développement existent. Elles ont pour mission d’être à l’écoute des développeurs pour fluidifier leur expérience de développement. Elles vont par exemple développer des outils internes analysant le code ajouté pour proposer des modifications améliorant la lisibilité ou la sécurité de la contribution. Au sein de Google, une plateforme interne se charge de faire ce type de suggestion : si un code n’est pas conforme, un clic suffit à le reformater. Si une librairie est considérée vulnérable, une alternative est proposée.
Ces outils permettent globalement d’accélérer le processus de développement et accélèrent les revues de code pour mettre le logiciel le plus rapidement possible en production. Ces méthodes sont particulièrement efficaces quand vous recevez régulièrement de nouveaux personnels non formés à vos pratiques de développement. Des arrivants peu expérimentés, sans règles explicites et contraignantes (les chaînes de CI/CD), peuvent rapidement impacter la qualité de votre base de code. Une inattention et un bug peut rapidement survenir.
Les techniques de déploiement blue/green qui seront évoquées dans les prochains chapitres permettent également de réduire les risques de régression logicielle (cf. chapitre “Déploiement continu”).
Les entreprises avec une forte culture SRE/DevOps favorisent les innovations proposées par leurs collaborateurs. Grâce aux techniques évoquées dans le chapitre précédent (CI, CD, blue/green, premortems, FMEA), il est heureusement possible de maîtriser le risque apporté par ces nouveautés.
Pour que vos employés restent motivés et innovants, il faut à tout prix éviter de brider leur créativité ou leurs idées. C’est pourquoi le design thinking et la réalisation de prototypes sont des techniques clés pour une organisation efficace.
Le design thinking est une technique d’innovation qui combine créativité et méthode pour tenter de résoudre des problèmes complexes. Elle est composée de 5 phases :
En résumé, vous devez vous mettre dans la peau de l’utilisateur, et des techniques comme le déploiement continu permettent de fluidifier ce processus. En étant confrontée à la réalité, l’innovation n’est pas freinée par l’organisation.
Si elle échoue, l’organisation en aura appris davantage sur son utilisateur et son environnement. Si elle aboutit, c’est un succès pour tout le monde : l’équipe en charge de l’innovation, l’organisation et l’utilisateur.
Cette culture du prototype est importante car une entreprise qui ne prototype pas lance moins d’idées, donc provoque moins de succès et prend plus de temps pour échouer. Au contraire, une entreprise ayant pris l’habitude de tester ses prototypes échouera plus vite et engrangera mécaniquement davantage de retours d’expérience et de succès.
Il n’est pas obligatoire de créer le logiciel de A à Z avant de le confronter au client. Vous pouvez réaliser une maquette sur Figma ou Penpot, utiliser une solution low-code/no-code213 ou trouver quelqu’un qui joue le rôle du client.
Une bonne culture s’entretient par la connaissance des techniques à l’état de l’art. Les compétences techniques de vos équipes constituent le terreau de votre organisation et forgent votre réputation de structure résiliente.
La formation continue est un moyen simple d’éviter à votre organisation de perdre des millions d’euros chaque année. En effet, si votre personnel demeure formé à l’état de l’art des technologies, il sera moins susceptible de se faire duper par des tierces parties. Ces dernières arrivent souvent en promettant “la solution idéale” au travers de présentations flatteuses et particulièrement ambitieuses. Des présentations qui ne manquent pas de cacher, la plupart du temps, un service non abouti ou complètement déficient. En restant à jour, vos collaborateurs prendront de meilleures décisions pour vos finances et le futur de votre organisation.
Mais garder le rythme n’est pas simple, surtout à la vitesse à laquelle les technologies évoluent. Raison de plus pour mettre en place de bonnes pratiques de formation dès l’arrivée de vos collaborateurs.
Par exemple chez Google, les stagiaires commencent par une semaine complète dédiée à la formation. Ils reçoivent des instructions sur les bonnes pratiques de sécurité, les formalités administratives qu’ils doivent remplir et sont sensibilisés aux outils techniques internes. Par la suite et comme pour tous les employés, ils devront valider périodiquement des modules de formation sur une plateforme dédiée avec des cours écrits ou en vidéo.
L’United States Air Force (USAF) s’est mise depuis 2019 en ordre de bataille en investissant massivement dans des solutions d’auto-apprentissage. Dans un podcast214, son ancien Directeur de l’Ingénierie Logicielle (Chief Software Officer) Nicolas CHAILLAN explique comment il a mis en place ce système pour plus de 100 000 développeurs. Une plateforme web a été déployée avec du contenu pédagogique spécialement sélectionné ou créé par ses équipes. Il ajoute qu’une heure par jour a été accordé aux collaborateurs pour “rattraper le retard et continuer d’être à jour sur les dernières technologies”.
« C’est (la formation est) un investissement pour l’entreprise et pour eux-mêmes. Les gens qui ne veulent pas apprendre d’eux-même n’ont pas beaucoup de chance de réussir en informatique. De toute façon, l’industrie bouge tellement vite qu’ils n’ont pas le choix. » - Nicolas CHAILLAN
À l’instar de l’USAF, la solution suivante avait bien fonctionné dans l’une de mes dernières expériences : nous avions réussi à obtenir un jour de télétravail par semaine. Le faire accepter à nos responsables n’était pas simple, mais ils ont fini par l’accorder. Ce jour était dédié à notre formation continue en tant qu’expert en IA, data et DevOps. Nous étions outillés et nos progrès pouvaient être mesurés : un accès quasi-illimité à un service Cloud et à une plateforme de e-learning. Cette dernière permettait à notre hiérarchie de visualiser les statistiques sur le temps passé à se former et les cours achevés. Le coût de ces deux services était minime par rapport à toutes les connaissances qu’ils nous conféraient.
Si vous avez déjà des équipes techniques à votre main, donnez leur la possibilité d’expérimenter, de pratiquer. C’est ce que j’ai observé de plus efficace (donc rentable) pour l’organisation : investissez du temps dans la formation de votre personnel. Par exemple, donnez-leur accès à des machines ou des hébergeurs Cloud pour expérimenter les dernières innovations du privé ou issues de l’open-source. Vos équipes seront ravies d’avoir accès à ces services, pendant que la direction sera assurée d’être conseillée au mieux, grâce à des collaborateurs à jour.
Il peut être tentant de penser que former un personnel sur une technologie innovante - c’est à dire le rendre attirant auprès de la concurrence - peut l’inciter à changer d’entreprise. Premièrement, partir simplement parce-que l’on acquiert une nouvelle compétence dénote un manque de perspectives au sein de son entreprise. Cela révèle un personnel déjà peu motivé, donc peu productif. Deuxièmement, la recherche indique qu’un personnel se formant sur son temps libre a plus fréquemment tendance à rechercher un autre travail215. C’est l’inverse quand l’entreprise se charge de le former.
Dans tous les cas, présentez votre transformation comme une opportunité d’évolution de carrière. Et soyez honnête avec les personnes qui devront monter en compétence : oui cela demandera des efforts personnels et du temps. Mais développer ces nouvelles expertises en vaut la chandelle.
Au sein de systèmes d’informations de plus en plus complexes, il devient fondamental d’automatiser les tâches récurrentes. L’humain représente le facteur principal d’erreurs au sein d’un système d’information216. Tout ingénieur confirmé pourra vous l’affirmer. C’est pour cela que les équipes de Google tentent de minimiser au maximum les interactions de leurs opérateurs pour administrer leurs systèmes217.
« Si un opérateur humain doit toucher votre système durant le fonctionnement normal du quotidien, vous avez un bug. La définition du terme “normal” change au fur et à mesure que vos systèmes se développent. » - Carla GEISSER, SRE chez Google
Si vous souhaitez faire de votre système informatique un outil intégré au sein de votre entreprise, vous devez d’abord automatiser les actions répétitives et coûteuses en temps : les actions manuelles (ou toil en anglais).
Cette notion de pénibilité qualifie toutes les tâches manuelles, répétitives et automatisables. Globalement, il s’agit de toutes les tâches peu intéressantes intellectuellement qu’un robot serait bien plus à même de faire que vos brillants ingénieurs.
Les équipes SRE de Google ont pour objectif de maintenir le travail opérationnel (tâches d’administration manuelles) en dessous de 50% du temps pour chaque SRE. Au moins 50% du temps de chaque SRE doit être consacré à des projets d’ingénierie qui permettront de réduire la quantité future de tâches manuelles ou d’ajouter des fonctionnalités à l’infrastructure.
Ce travail peut commencer par de petites choses au sein de votre infrastructure existante. Nous allons dans ce chapitre les lister selon plusieurs niveaux de maturité organisationnelle. Il vous convient de déterminer quel niveau d’automatisation est le plus acceptable pour votre organisation, selon le niveau d’acculturation technologique de vos équipes d’ingénieurs et le temps que vous voulez accorder à la mise en place de ces technologies.
Gardez cet élément en tête : automatiser est l’action qui permet de réduire la dette technique. Veillez à allouer assez de temps à vos équipes pour qu’elles travaillent dessus.
Ce terme populaire est simple à appréhender : il regroupe les pratiques et les technologies permettant de rendre la configuration de votre infrastructure explicite, sous forme de code informatique.
Voici quelques exemples de configuration :
Bien entendu, quand j’évoque « toutes vous machines », les scripts d’IaC permettent de définir quelles sont exactement ces machines de telle sorte à n’appliquer les modifications que sur tel ou tel groupe de machines.
Cette pratique comporte plusieurs avantages :
Des exemples courants de technologies permettant de réaliser ces actions sont : Ansible, Terraform, Puppet ou encore SaltStack.
Chacun a ses avantages, ses inconvénients, sa communauté. D’autres sont complémentaires. Le tout est d’adopter un format standardisé (pas forcément en n’utilisant qu’une seule technologie) pour que vos équipes SRE s’y retrouvent. Un nouvel arrivant sera grandement aidé par ces pratiques et vos ingénieurs les plus confirmés pourront améliorer incrémentalement ces algorithmes.
Vous pouvez tout d’abord commencer à automatiser vos infrastructures à l’aide de scripts classiques (bash, Powershell) puis passer sur une technologie plus avancée comme Ansible qui normalisera vos configurations.
Reportez-vous au projet GitHub « ToDevOps » 218 pour voir cette technologie en pratique.
Pour superviser et automatiser ces tâches d’administration, des outils avancés comme Ansible AWX, Ansible Tower (fig.

Gardez en tête que maintenir une infrastructure est une tâche complexe, donc keep it simple ! N’allez pas adopter la dernière technologie du moment seulement parce qu’elle est “sexy” : plus vous ajoutez des technologies et des niveaux d’abstraction, plus votre équipe doit être fournie et expérimentée pour les maintenir et les réparer (cf. chapitre “Too big, too soon”).
Le développement piloté par tests (ou test-driven development (TDD) en anglais) est une pratique de développement logiciel qui remonte au début des années 2000. L’objectif est de maîtriser l’érosion d’un logiciel220, c’est à dire éviter sa régression et maîtriser sa dette technique au cours du temps. Ou dit plus simplement : éviter les bugs à mesure que les contributions s’accumulent.
L’idée est de coder les tests avant de développer sa fonctionnalité. Le cycle de développement en TDD est le suivant221 :
C’est une pratique courante dans les entreprises du secteur de la technologie, en particulier chez les GAFAM. Ces derniers se basent dessus pour maîtriser la dette technique, malgré les milliers de développeurs qui contribuent en parallèle et chaque jour à leurs logiciels. La plupart du temps, les logiciels sont développés sans ou avec peu de tests. Il peut être compliqué de justifier à une hiérarchie non-technique le temps passé à développer des tests, plutôt que de se concentrer sur une nouvelle fonctionnalité. Travailler en TDD impacte en effet la productivité, mais améliore significativement la qualité du code222.
Pour un logiciel historique, il est recommandé d’au moins adopter l’approche TLD (test-last developement). C’est à dire développer les tests après que la fonctionnalité soit créée. Puis de progressivement passer au TDD pour améliorer la qualité et réduire la complexité du code223. Pour les nouveaux projets, privilégiez le TDD.
Dans tous les cas, l’idée est de tester son code pour éviter les mauvaises surprises en production. Selon Atlassian224, il est recommandé de couvrir 80% de son code par des tests (code coverage en anglais).
Le TDD est recommandé dans certains cas, mais pas tous. Par exemple, si votre secteur d’activité est réglementé - comme celui des banques ou de la santé - il est impératif de tester votre code. La conséquence du dysfonctionnement de votre logiciel peut impacter la responsabilité juridique de votre organisation. Si votre logiciel est destiné à être utilisé et maintenu de nombreuses années - comme dans la défense - il est recommandé d’adopter le TDD. En revanche, si vous êtes une start-up en étape de preuve de concept, le dysfonctionnement d’un logiciel peut avoir moins de conséquence et vous pouvez vous permettre de privilégier votre productivité. Plus votre structure grandit, plus le nombre de développeurs qui contribuent à votre logiciel augmente, plus il devient nécessaire de tester votre code. Par exemple, pour un nouveau contributeur, un test permet d’avoir un exemple de la manière dont une fonction est utilisée, ce qui facilite la compréhension du code.
En somme, il s’agit de trouver l’équilibre entre productivité, garantie de bon fonctionnement et contrôle de la dette technique.
Ce chapitre n’est qu’une introduction pour vous présenter l’intérêt de tester votre code. Il existe de nombreuses approches complémentaires et des bonnes pratiques de développement qui concernent davantage l’ingénierie logicielle (cf. YAGNI, KISS, DRY) et moins spécifiquement le DevOps. Par exemple, le TDD peut être suppléé par le BDD (behavior-driven development) ou l’ATTD (acceptance test-driven development)225 si la maturité de votre structure et la taille de vos équipes peuvent le permettre.
L’ensemble de ces tests est vérifiable automatiquement avant toute mise en production. Découvrons ce que cela signifie et comment le mettre en pratique dans le chapitre suivant.
L’intégration continue (continuous integration ou CI en anglais) est une pratique de développement au sein de l’usine logicielle. L’idée est la suivante : à chaque modification du code, des scripts automatisés se lancent pour vérifier la conformité de la contribution (fig.
Par exemple, vos équipes SSI n’ont probablement pas le temps de vérifier la conformité de chaque contribution. Elles peuvent alors déléguer une partie de ces vérifications à des scripts qui vérifieront automatiquement et systématiquement que la base de code respecte vos standards de sécurité. L’avantage est triple :
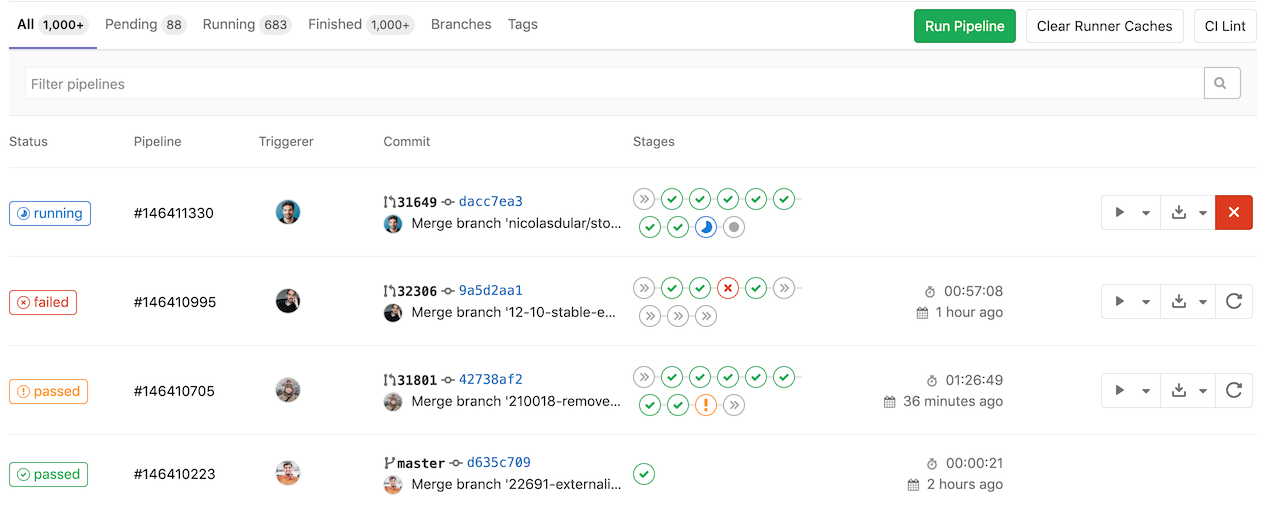
Ainsi, en mode DevOps, les responsables SSI ne sont plus des personne édictant des règles au format papier, mais des ingénieurs “codant” des règles SSI sous forme de scripts automatisés, dans la forge logicielle (fig.
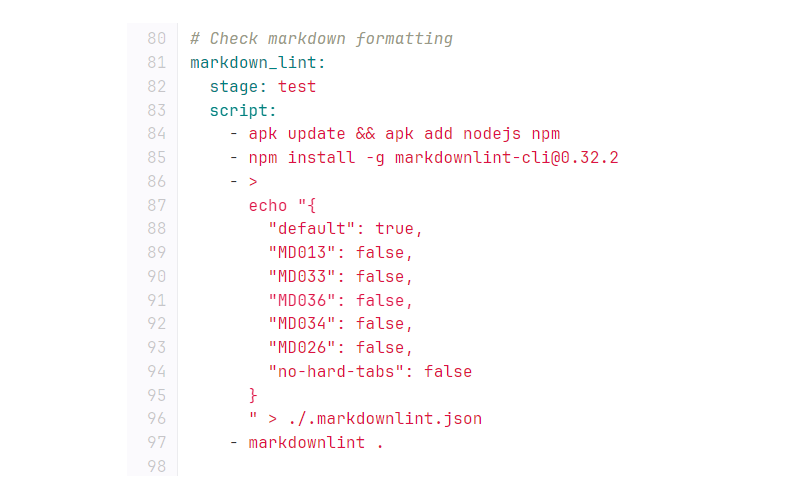
Voici quelques exemples d’algorithmes qu’il est possible de lancer pour vérifier automatiquement des règles ou prendre des actions lors d’un évènement déclencheur :
Toutes ces tâches contribuent en la réduction de la dette technique de votre base de code et facilite le déploiement de vos projets, en garantissant l’application des standards définis par vos équipes DevOps.
Il est courant d’entendre parler de pipeline d’intégration continue (en français “chaîne d’intégration continue”), qui accompagne d’autres termes dans l’univers des technologies de CI/CD. Définissons les plus courants :
Comme cité plus haut, l’intérêt d’une pipeline d’intégration continue est également de tester le code poussé sur plusieurs environnements automatiquement : votre environnement de développement et de préproduction avant de le déployer en production. Néanmoins, ces pipelines multi-environnement introduisent une complexité supplémentaire qu’il faut être en mesure d’absorber lors de sa mise en place, par une équipe technique plus importante.
Au sein d’une usine logicielle, ce sont des technologies telles que les GitLab Runners, les GitHub Actions ou les services de Circle CI qui permettent de lancer des tâches d’intégration continue.
Le déploiement continu (continuous deployment ou CD en anglais) est une pratique DevOps permettant de déclencher des actions d’administration ou de déployer et mettre à jour des logiciels en production. Le déclenchement n’est pas nécessairement automatisé mais les actions appliquées sont codées. C’est à dire prévisibles, traçables et réplicables. Cela réduit le temps de mise à disposition d’une nouvelle fonctionnalité à ses utilisateurs, en minimisant l’intervention manuelle et le risque d’erreur par les administrateurs.
Cette pratique se conjugue au principe de “livraison continue” (continuous delivery en anglais), qui réunit des étapes préliminaires au déploiement. Par exemple, publier les binaires ou les images de la dernière version du logiciel, ou créer la dernière release du projet dans l’usine logicielle.
La plupart du temps, les chaînes de déploiement continu sont techniquement similaires aux chaînes d’integration continue. Par exemple, elles vont rejouer les tâches des chaînes d’intégration continue avant de déployer le logiciel. En revanche, elles peuvent nécessiter des paramètres plus spécifiques, tels que des variables d’environnement ou des secrets (cf. Hashicorp Vault, Akeyless, Keywhiz, Conjur). En effet, un logiciel déployé repose communément sur des variables d’environnement pour s’exécuter correctement sur une infrastructure cible.
Il est habituel de retrouver des environnements de qualification/pré-production (staging) et de production différents. Ces derniers permettent de valider le bon fonctionnement d’un logiciel avant sa mise en production. Les chaînes de déploiement continu automatisent tout ou partie de ce processus, en ajoutant si souhaité des smoke tests ou des tests fonctionnels (cf. chapitre “Développement piloté par tests”).
Dans un premier temps, il s’agit d’au moins automatiser la mise à jour de votre logiciel en production. Vous pouvez le faire de la même manière qu’avec les chaînes d’intégration continue, grâce aux GitLab Runners ou aux GitHub Actions.
D’autres pratiques existent pour des utilisateurs plus avancés. Comme nous avons pu l’évoquer dans le chapitre “GitOps”, notre répertoire git est la “source unique de vérité” d’un logiciel. Par conséquent, l’infrastructure doit idéalement se baser dessus pour définir l’état attendu d’un logiciel en production. Par exemple, l’outil ArgoCD va vérifier en permanence la présence de modifications dans un répertoire git, sur une branche spécifique (souvent main ou master). Dès qu’ArgoCD détecte un changement, il tente de déployer la toute dernière version du logiciel surveillé.
Les outils comme ArgoCD (fig.
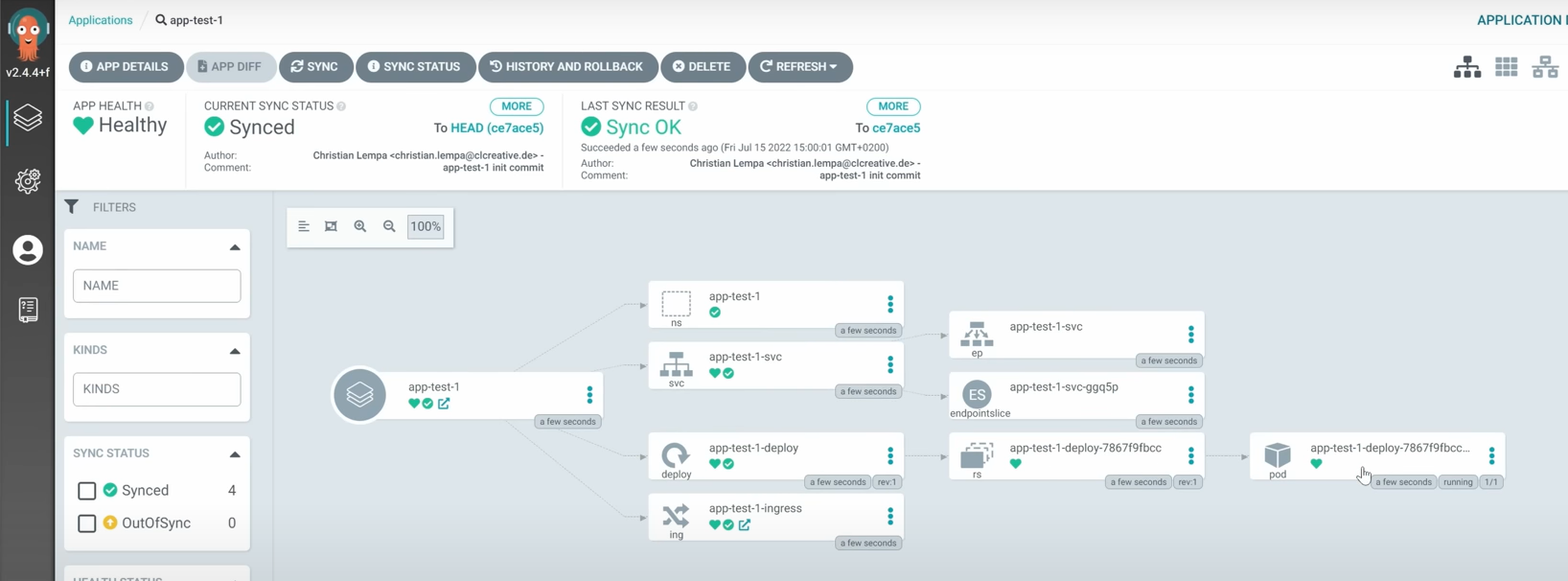
Sur le même principe, il est possible de déployer simultanément plusieurs instances d’un logiciel. Par exemple lors d’une revue de code dans une merge request, vous pouvez configurer ArgoCD pour qu’il déploie temporairement et de manière isolée cette version “en évaluation” du logiciel. Cette technique permet aux ingénieurs de rapidement tester un logiciel, au lieu de le déployer par leurs propres moyens. Les URLs ont souvent cette forme : wxyz.staging.monapp.com.
Avec ces mêmes outils, vous pouvez adopter une stratégie de déploiement blue/green et l’automatiser. Cette technique fait basculer progressivement les clients vers la nouvelle version d’un logiciel, en s’assurant que cette dernière fonctionne correctement. L’idée est d’instancier la nouvelle version du logiciel (green), en parallèle avec l’actuelle (blue). Le système dirige alors une proportion limitée de clients vers le nouveau logiciel (ex: 10%). On augmente progressivement cette proportion au cours d’une période définie, tout en mesurant le taux d’erreurs obtenu pour chaque requête. Si le taux est identique ou inférieur au précédent déploiement, on laisse le logiciel se déployer pour l’ensemble des clients. Sinon, le déploiement est annulé et on laisse l’ancienne version en production.
Des outils encore plus avancés existent pour adresser les enjeux du déploiement à très grande échelle. Nous découvrirons l’exemple de Palantir et son produit Apollo dans le chapitre “Déployer en parallèle dans des environnements différents”.
Par ailleurs, les chaînes de déploiement continu ne se limitent pas au déploiement du logiciel ou au lancement de tâches d’administration. Elles peuvent constituer un point de départ pour la supervision de votre logiciel. Par exemple, une chaîne de déploiement continu peut configurer une instance Prometheus / Grafana et commencer à envoyer ses journaux d’activité. Le déploiement de votre logiciel ne signe pas la fin du cycle de consolidation de votre infrastructure : vous devez maintenant le superviser. Nous découvrirons ces techniques dans le chapitre “Tout mesurer”.
Dans le chapitre précédent - “Tirer parti de l’automatisation” - nous avons vu en quoi l’automatisation permettait de gagner un temps considérable dans l’administration de votre infrastructure, ainsi que d’augmenter sa sécurité et sa résilience.
Dans ce chapitre, nous allons aborder une dimension importante de l’automatisation : l’observabilité. C’est grâce aux mesures qu’il est possible de massivement automatiser les systèmes et de prendre de meilleures décisions à l’échelle de l’organisation. Le fait de tout mesurer permet trois choses :
Avoir confiance dans ses décisions, en se basant sur ses propres données, est l’aboutissement d’une transformation DevOps réussie. L’industrie nomme cela les “prises de décision basées sur la donnée” ou “data-driven decision making” en anglais.
Les journaux d’activité (logs), les métriques (metrics) et les traces (traces) sont considérés comme les trois piliers de l’observabilité. Ces trois type de données peuvent être générés par les logiciels, pour identifier et résoudre les problèmes susceptibles de survenir une fois déployés.
L’observabilité est un sujet très vaste dans le domaine de la fiabilité des systèmes228. Nous ne survolerons que l’essentiel dans ce chapitre.
Le domaine de l’observabilité peut être résumé comme l’ensemble des outils et des pratiques permettant aux ingénieurs de détecter, diagnostiquer et résoudre les problèmes d’un système (bugs, lenteurs, disponibilité), le plus rapidement possible. Au delà du besoin de résilience, la récupération de certaines de ces données est parfois requise par la loi229.
Examinons de plus près ce que chacune de ces données peut nous apprendre :
Attardons-nous sur les traces pour bien comprendre ce qu’elles impliquent. Prenons l’exemple d’une application (un client) qui envoit une requête à une API REST (un serveur). Une trace est composée de spans et de metrics, associées à un identifiant unique. Cet identifiant permet de discriminer le cheminement de notre requête au travers de tous les services par lesquels elle passera. La figure
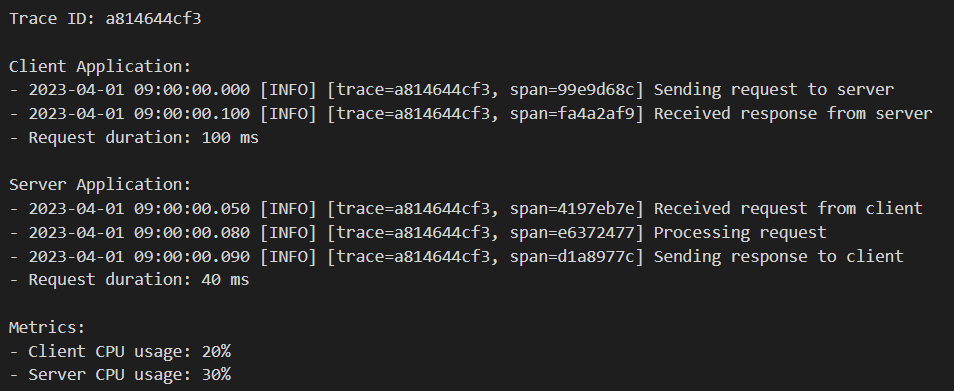
Pour mieux se représenter la temporalité de la requête, les logs d’une trace sont souvent affichés sous forme de diagramme. Chaque span est alors représentée par un rectangle incluant un nom (à gauche) et une durée (au niveau du rectangle) comme illustré en figure
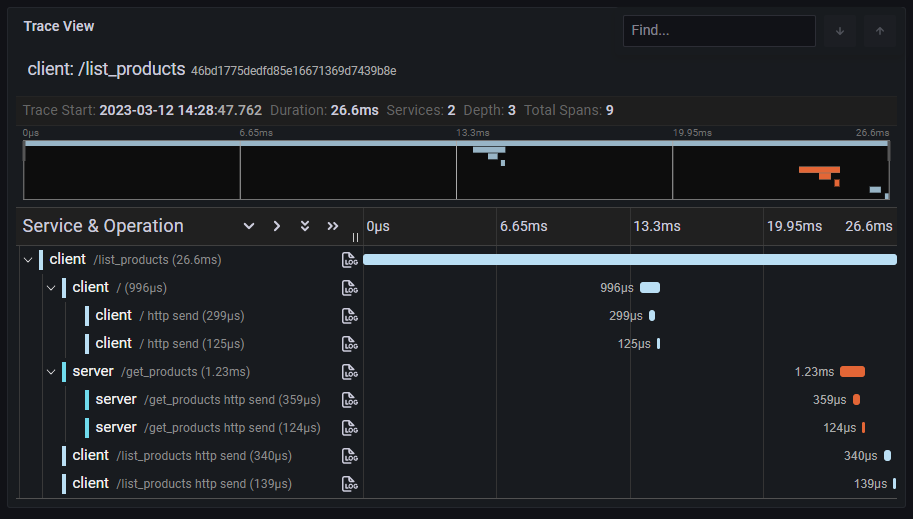
Les traces sont indépendamment remontées par des librairies comme le SDK d’OpenTelemetry. Ces dernières les envoient à un collecteur de traces comme Jaeger, Tempo ou Zipkin pour qu’elles soient validées, nettoyées et/ou enrichies. Elles sont ensuite stockées dans des serveurs de logs centralisés, comme Prometheus ou Elasticsearch. L’identifiant de la trace nous permet de retrouver la chronologie des opérations par lesquelles elle est passée.
Le plus grand défi du traçage est son intégration au sein d’une infrastructure existante. En effet, pour que les traces soient pleinement utiles, il faut que chaque composant par lequel passe la requête émette un log et propage les informations de traçage à son tour. Moins précis que s’il était directement intégré à un logiciel, le traçage via service mesh peut être un moyen rapide de disposer des fonctionnalités de traçage sans avoir à modifier le code de ses logiciels230. Nous verrons ce qu’est un service mesh et comment cette technologie fonctionnent dans le chapitre “Service mesh”.
Au sein de très grandes infrastructures, les logs et les traces sont parfois trop massives pour être ingérées par son serveur de logs à temps. Des données peuvent alors être perdues. Pour éviter ce problème, il est courant d’utiliser des services qui viennent temporiser l’indexation. Un serveur comme Kafka peut être placé devant le serveur de logs pour les absorber progressivement. Puis un programme comme le Jaeger Ingester vient progressivement les indexer. Pour les logs rsyslog, l’utilisation de protocoles comme le RELP231 peut être nécessaire pour s’assurer qu’ils soient bien sauvegardés.
Que ce soit à l’aide de Logstash ou Loki pour les logs, ou avec Jaeger ou Tempo pour les traces, normaliser ses données est capital pour pouvoir correctement les stocker et les traiter. Pour répondre à cet enjeu, la librairie OpenTelemetry définit des conventions sémantiques232. Elle est celle qui est utilisée la plupart du temps.
En mettant en place des mécanismes d’observabilité, vous pourrez répondre plus facilement à la question “Que s’est-il passé pour que ce bug se produise ?”. Vos ingénieurs pourront se baser sur des données exhaustives pour corriger les bugs plus rapidement. Ces données vont nous permettre de mieux construire nos indicateurs de résilience, pour prendre plus rapidement des décisions avisées.
À première vue, il n’est pas évident de savoir où mettre le curseur entre les travaux de résilience et d’innovation. L’idée est donc de mesurer l’état des services pour déterminer quand on s’autorise à innover.
Mesurer est une chose, mais encore faut-il mesurer les bonnes choses, au bon niveau. Dans une infrastructure distribuée, l’un des serveurs peut tomber en panne sans nécessairement impacter la disponibilité d’un logiciel pour vos clients. Mesurer la disponibilité d’un serveur est peut-être intéressant pour vos techniciens, mais peut-être n’est-elle pas la bonne mesure pour connaître l’impact du dysfonctionnement sur l’utilisateur. C’est cela que votre organisation doit définir :
Pour la deuxième question, vous ne pouvez pas répondre “0%”. Si vous mettez tous vos efforts à rendre le service disponible 100% du temps, vous allez ralentir le lancement de nouvelles fonctionnalités. Or c’est cela qui fait avancer votre projet. C’est pour répondre à cette question qu’intervient la notion de “budget d’erreur”.
Le budget d’erreur est la quantité de temps sur une période donnée que votre entreprise accorde à vos équipes et durant lequel vos services peuvent être indisponibles. Tant que la disponibilité de votre service dépasse l’indisponibilité tolérée, vous pouvez en profiter pour déployer un nouveau service majeur, en forte interaction avec les autres, ou encore mettre à jour un système critique. Ce budget est essentiel pour faire face à des dysfonctionnements matériels nécessitant un remplacement ou pour intervenir sur un système lors d’une interruption planifiée.
Par exemple, si votre budget d’erreur est de 54 minutes par semaine et que vous ne dépassez pas 10 minutes depuis 3 semaines, autorisez-vous à prendre davantage de risques. Si c’est l’inverse, travaillez à rendre votre infrastructure plus résiliente.
En somme, le budget d’erreur est un accord entre la direction et les équipes techniques, aidant à prioriser les travaux d’innovation vis-à-vis des travaux améliorant la résilience de l’infrastructure.
Il permet aux équipes d’ingénierie de réévaluer par elles-mêmes des objectifs trop ambitieux vis-à-vis du risque toléré. Elles peuvent ainsi définir des objectifs réalistes. Le budget d’erreur permet aux équipes de partager entre elles la responsabilité de la résilience d’un service : les défaillances de l’infrastructure impactent le budget d’erreur des développeurs. Inversement, les défaillances logicielles impactent le budget d’erreur des équipes SRE.
Faites attention à vos pics de consommation de budget d’erreur : si un ingénieur passe dix heures au lieu d’une pour corriger un incident, il lui est recommandé d’ouvrir un ticket auprès de quelqu’un de plus expérimenté. Il évitera ainsi de consommer tout le budget d’erreur.
Pour répondre à la première question, voyons quels sont les indicateurs qu’il est possible de suivre dans le prochain chapitre.
La surveillance de systèmes distribués représente un véritable dilemme. Les équipes SRE doivent réussir à les surveiller facilement - pour pouvoir intervenir rapidement - alors que leur architecture est souvent complexe. De fait, nombreuses sont les technologies qui composent ces systèmes. Les 4 signaux clé apportent un moyen unifié de caractériser les phénomènes les plus importants à surveiller.
Découvrons les 4 grandeurs qui nous permettrons ensuite de créer nos propres indicateurs de résilience :
Au sein d’une infrastructure Cloud, un service mesh automatise l’acquisition de ces mesures. Nous découvrirons cette technologie dans le chapitre “Service mesh”. Nous verrons également quels outils existent pour récolter et visualiser ces métriques. Mais avant cela, découvrons comment créer nos indicateurs de résilience dans le prochain chapitre.
La valeur de votre budget d’erreur découle de vos “objectifs de qualité de service” (Service Level Objective ou SLO en anglais).
Un SLO qualifie un objectif cible de résilience pour un système. Il est représenté comme une proportion de “bons” évènements à honorer, sur l’ensemble des évènements surveillés, pour une période de temps donnée. Par exemple, votre équipe SRE peut définir l’objectif suivant : “99% des pages doivent charger en moins de 200 millisecondes (ms) sur 28 jours”.
L’objectif “juste” d’un SLO est déterminé par le seuil de tolérance que peut supporter votre client face à un phénomène irritant. Par exemple, quantifiez ce que signifie pour lui avoir un site web “lent” (ex: grâce une étude SEO233). Si vos clients quittent généralement vos pages après plus de 200ms d’attente, définissez votre SLO par “99.9% des réponses doivent être retournées en moins de 200ms, sur 1 mois”.
Un bon SLO doit toujours avoir une valeur proche de 100% sans jamais l’atteindre ; nous en avons évoqué les raisons dans le chapitre “Savoir quand innover et quand s’arrêter”. Quant à la fréquence à laquelle atteindre cet objectif (99.9% sur 1 mois), il n’existe pas de règle pour la définir initialement. Vous pouvez vous baser sur une moyenne de votre historique de mesures, ou expérimenter. Cette valeur doit être adaptée à la charge de travail que votre équipe est capable d’absorber.
Les SLOs se construisent à partir d’un ou plusieurs “indicateurs de niveau de service” (Service Level Indicator ou SLI). Le SLI est le taux actuel de bons évènements mesurés, sur l’ensemble des évènements pris en compte, pour une période donnée. Se basant lui-même sur une ou plusieurs mesures, il permet de mesurer l’un des aspects de la résilience d’un système. Il qualifie un phénomène pouvant impacter négativement votre utilisateur : le temps de réponse à une requête, le nombre de données retournées qui sont bien à jour, ou encore la latence en lecture et écriture pour le stockage des données.
Voici quelques exemples pour bien distinguer sur quelle SLI se base un SLO, puis sur quelle(s) mesure(s) se base(nt) un SLI :
Un SLI peut se composer d’une ou plusieurs mesures. Néanmoins, évitez de construire des SLIs ou des SLOs trop complexes au risque de représenter des phénomènes vagues ou fallacieux.
Un SLO fixe une qualité de service à maintenir, c’est à dire une certaine valeur pour un SLI. Un SLO adopte un format de ce type : “Le SLI X doit être maintenue Y% du temps sur Z jours/mois/année”. Voici un tableau faisant correspondre taux de résilience et durées maximales de panne autorisée (partie “Z jours/mois/année” de l’exemple précédent) :
| Taux de résilience | Par année | Par trimestre | Par mois (28 jours) |
|---|---|---|---|
| 90% | 36j 12h | 9j | 2j 19h 12m |
| 95% | 18j 6h | 4j 12h | 1j 9h 36m |
| 99% | 3j 15h 36m | 21h 36m | 6h 43m 12s |
| 99.5% | 1j 19h 48m | 10h 48m | 3h 21m 36s |
| 99.9% | 9h 45m 36s | 2h 9m 36s | 40m 19s |
| 99.99% | 52m 33.6s | 12m 57.6s | 4m 1.9s |
| 99.999% | 5m 15.4s | 1m 17.8s | 24.2s |
Si les SLOs doivent représenter en priorité les irritants pour vos utilisateurs, vous pouvez aussi en constituer pour vos équipes internes. Par exemple, votre infrastructure peut vérifier que chaque serveur répond “99% du temps en moins de 500ms aux requêtes ICMP sur 1 semaine”. Dans ce cas-là, définissez vos SLOs à partir de votre historique de mesures (fig.

Les SLOs doivent être définis de paire avec les décideurs. Leur implication dans cette définition est nécessaire pour qu’ils puissent comprendre en quoi leurs décisions (ex: priorisation des tâches, quantité de travail demandée) impactent la résilience de l’infrastructure. Si un décideur veut que ses ingénieurs développent souvent et rapidement des nouveautés, les SLOs aident à comprendre quand le rythme imposé est trop exigeant. À l’opposé, atteindre trop largement ses SLOs indique que votre entreprise peut avancer plus vite sans impacter sa qualité de service. L’implication des décideurs est d’autant plus importante qu’ils mettent parfois la responsabilité de l’entreprise en jeu. C’est la SLA qui en est à l’origine.
L’accord de niveau de service (Service Level Agreement ou SLA) est un contrat entre votre organisation et un client. Si votre qualité de service est inférieure à celle définie par vos SLAs, votre organisation subit des pénalités. Un SLA se base sur un ou plusieurs SLOs, en définissant par précaution des taux de résilience inférieurs. Voici quelques exemples :
Les SLAs ne sont pas rendus obligatoires en France par la loi. Néanmoins ils peuvent faire partie de votre contrat de service, pour clarifier vos engagements et éviter les litiges. En effet, il est toujours préférable de lister des conditions claires pour lesquelles vous et votre client vous êtes engagés. Les SLAs sont également un avantage concurrentiel : votre entreprise s’engage à fournir une certaine qualité de service, là où vos concurrents ne s’en donnent pas nécessairement la peine. Instaurer un SLA dans votre méthode de gouvernance responsabilise les parties prenantes (développeurs, SRE, décideurs) et partage les attendus. L’entreprise s’oriente désormais grâce aux mesures qu’elle récolte, puis qu’elle interprête sous forme de SLO. On dit qu’elle est data-driven.
Au sein d’une institution, vous pouvez utiliser un SLO/SLA comme un moyen de gagner en crédibilité auprès de votre hiérarchie ou de certaines équipes. Un SLA remplit peut justifier l’embauche de personnels nécessaires pour maintenir un certain niveau de service. Ou bien justifier une augmentation de budget pour développer l’activité de l’équipe. Inversement, la hiérarchie peut exiger de vos équipes un certain niveau de qualité de service, reporté sur les objectifs annuels des personnels. Dans le cadre d’une expérimentation, établir des SLOs suffit. Constituer des SLOs fiables est déjà un enjeu de taille. Maintenir les objectifs en est un autre.
Vos mécanismes d’alerte doivent constamment surveiller vos SLIs pour vérifier qu’ils ne dépassent pas vos SLOs. Et surtout, qu’ils ne dépassent pas vos SLAs ! Mais comment lever une alerte avant que vos SLOs/SLAs soient dépassés ?
Prenons l’exemple de cet SLO : 99% des pages doivent charger en moins de 200ms sur 28 jours.
La méthode la plus simple est de calculer la moyenne du temps de chargement des pages, sur une courte période. Par exemple, la moyenne des temps de chargement sur 5 minutes. Configuré sur cette approche, votre mécanisme d’alerte se déclenche lorsqu’au cours des 5 dernières minutes, la moyenne des temps de chargement dépasse 200ms.
Néanmoins, baser ses alertes sur la moyenne ou la médianne des mesures n’est pas la meilleure option. Cette approche ne permet pas d’identifier les défaillances à large échelle. Google recommande une autre approche235, utilisant les centiles (percentiles en anglais). Cette méthode de distribution permet de mettre en évidence les changements de tendance parmi le top X% des mesures récoltées.
Imaginez que votre infrastructure serve des millions d’utilisateurs. Vous recevez des milliards de requêtes. Il se peut qu’une page défaillante, affectant seulement quelques centaines d’utilisateurs sur votre site, passe totalement inaperçu si vous utilisez la moyenne ou la médianne comme méthode de mesure. En revanche, si vous utilisez l’aggrégation par centile, vous pourrez distinguer plus finement ces anomalies (fig.
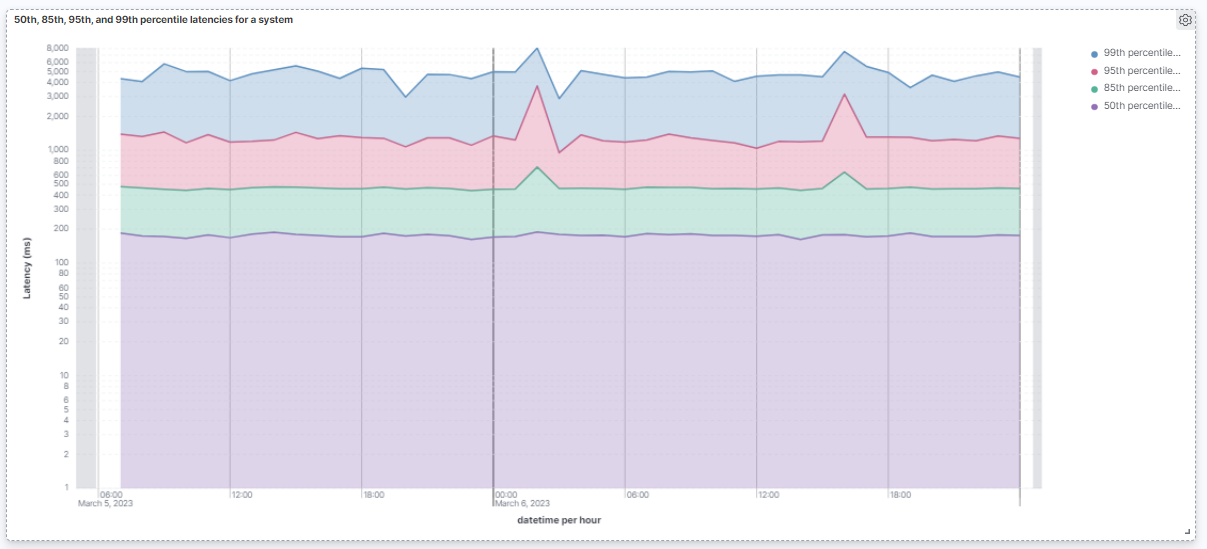
Avec cette représentation, il est possible de déduire qu’en moyenne, la latence des requêtes est inférieure ou égale à 200ms (le 50ème centile, partie violette, représente la médianne). Mais plus intéressant encore, elle permet de comprendre que 5% des requêtes (à partir du 95ème centile, partie rouge) sont 2.5 fois plus lentes (~500ms) que la moyenne. Votre équipe SRE va pouvoir travailler à découvrir pourquoi la latence est si élevée pour ces requêtes.
Attardons-nous sur un autre phénomène : le 6 mars peu après 0h00, le top 1% des requêtes les plus lentes (99ème centile, partie bleue) atteint un pic de 8000ms de latence contre 5000ms en moyenne. Il se passe quelque chose : votre système d’alerte peut plus facilement détecter cette anomalie, et votre équipe SRE mieux isoler les requêtes concernées pour les investiguer. En observant seulement la médianne (50ème percentile), on se rend compte que ces changements de tendance sont lissés, presque imperceptibles.
Fort de ce constat, nous pouvons améliorer l’un des indicateurs du chapitre précédent :
Pour développer votre intuition sur ces indicateurs, commencez par des SLIs et SLOs classiques. Une fois que votre infrastructure a gagné en maturité - et particulièrement en nombre d’utilisateurs - vous pouvez vous orienter vers des SLIs et SLOs avancés.
Les MTTx sont des mesures qualifiant le temps moyen pour qu’un évènement se produise ou prenne fin. Le “x” de l’acronyme MTTx qualifie la pluralité de cette catégorie de mesures. Par exemple, le MTTR (mean time to recovery ou temps moyen pour le rétablissement) est utilisé pour suivre le temps que prend une équipe avant de rétablir l’état d’un système défaillant.
Suivre ces mesures au cours du temps vous permet d’évaluer l’efficacité de vos travaux de résilience. Cela vous permet aussi de jauger l’efficacité de vos équipes pour répondre aux incidents. Si les mesures se dégradent, vous devrez étudier pourquoi et éventuellement réorganiser vos priorités afin de ne pas menacer vos SLOs. L’avantage est que vous saurez sur quoi vous concentrer.
Les MTTx sont nombreuses dans la littérature, avec chacune leurs spécificités et leurs nuances (fig.
| Mesure | Nom complet | Signification |
|---|---|---|
| MTTD | mean time to detect ou temps moyen de détection | Temps moyen entre le déclenchement de l’incident et le moment où vos systèmes lancent l’alerte. Détecter un incident peut prendre quelques secondes quand un problème conséquent se déclenche. Mais cela peut prendre plusieurs semaines quand il ne concerne qu’un utilisateur isolé qui ne fait pas remonter le problème… jusqu’à ce qu’il ne puisse plus le gérer. |
| MTTA | mean time to acknowledge ou temps moyen de prise en compte | Temps moyen entre le déclenchement d’une alerte et l’attribution d’un personnel à la résolution cet incident. |
| MTTI | mean time to investigation ou temps moyen d’investigation | Une fois que l’incident a été pris en compte, temps moyen nécessaire pour que la personne qui a été désignée sache réellement ce qui ne va pas et comment y remédier. Une MTTI trop élevée suggère que votre infrastructure ou votre application est trop complexe, ou que vos mécanismes d’observabilité sont insuffisants. Cela peut aussi indiquer que vos ingénieurs sont débordés et qu’ils ont ainsi du mal à se libérer pour intervenir rapidement sur un incident. |
| MTTR | mean time to recovery ou temps moyen pour le rétablissement | Temps moyen entre l’alerte et la résolution du problème |
| MTTP | mean time to production ou temps moyen à la production | Temps moyen pour que le service affecté par un incident soit à nouveau opérationnel et accessible aux utilisateurs en production. Au contraire du MTTR qui mesure le temps de réparation d’un service, alors que le MTRS mesure le temps de restauration du service après la réparation du service. Par exemple en cas de panne, votre site peut afficher un avertissement “Nous sommes en maintenance” même si vous venez de réparer le service défaillant. |
| MTBF | mean time before failure ou temps moyen entre deux défaillances | Temps moyen entre la dernière défaillance détectée et l’actuelle. Cette mesure aide à prédire la disponibilité d’un service. |

Vous pouvez commencer à suivre vos MTTx dans un tableur collaboratif (ex: Baserow, NocoDB, Google Sheets) puis passer à des outils plus intégrés comme Jira Service Management ou Odoo. L’idée est de pouvoir calculer et visualiser la tendance que prennent vos MTTx avec le temps.
Si vous optez pour un tableur, vous pouvez utiliser pour cette structure :
| Mesure | Date de début | Date de fin | Incident |
|---|---|---|---|
| TTD | 04/07/2024 16h45 UTC | 04/07/2024 16h50 UTC | abcd.com/C4D5E6 |
| TTA | 04/07/2024 16h50 UTC | 04/07/2024 17h00 UTC | abcd.com/C4D5E6 |
| TTI | 04/07/2024 17h00 UTC | 04/07/2024 17h20 UTC | abcd.com/C4D5E6 |
| TTR | 04/07/2024 17h00 UTC | 04/07/2024 18h30 UTC | abcd.com/C4D5E6 |
| TTD | 02/06/2024 13h30 UTC | 02/06/2024 13h34 UTC | abcd.com/A1B2C3 |
| … | … | … | … |
Calculez vos MTTx en faisant la moyenne des différences entre date de début et date de fin pour chaque incident. Echantillonnez sur une période d’un mois calendaire.
Comme vous pouvez l’observer, la majorité des mesures peuvent être issues de votre postmortem. Elles sont dans tous les cas intimement liées à ce dernier et la complètent. Veillez à tenir vos MTTx à jour pour chiffrer votre niveau de résilience et identifier les points névralgiques qui l’affectent.
Malgré son application très concrète et pratique, le service mesh ou “service de maillage de services” est une notion qui peut paraître complexe au premier abord.
Abordons-la au travers de quelques problématiques qui illustrent son intérêt :
Grâce aux mécanismes de déploiement standardisés que proposent les systèmes d’orchestration des containers (ex: Kubernetes), un service mesh permet d’adresser ces problématiques en se “connectant” à votre système d’orchestration. Il peut améliorer la sécurité, la stabilité et l’observabilité de votre infrastructure en :
Les métriques étant standardisées, la plupart des service mesh permettent de les utiliser pour configurer des règles automatiques selon l’activité réseau de l’infrastructure (fig.

En résumé, un service mesh gère tout ou partie des aspects suivants : gestion du trafic réseau, sécurité des flux et observabilité réseau (fig.
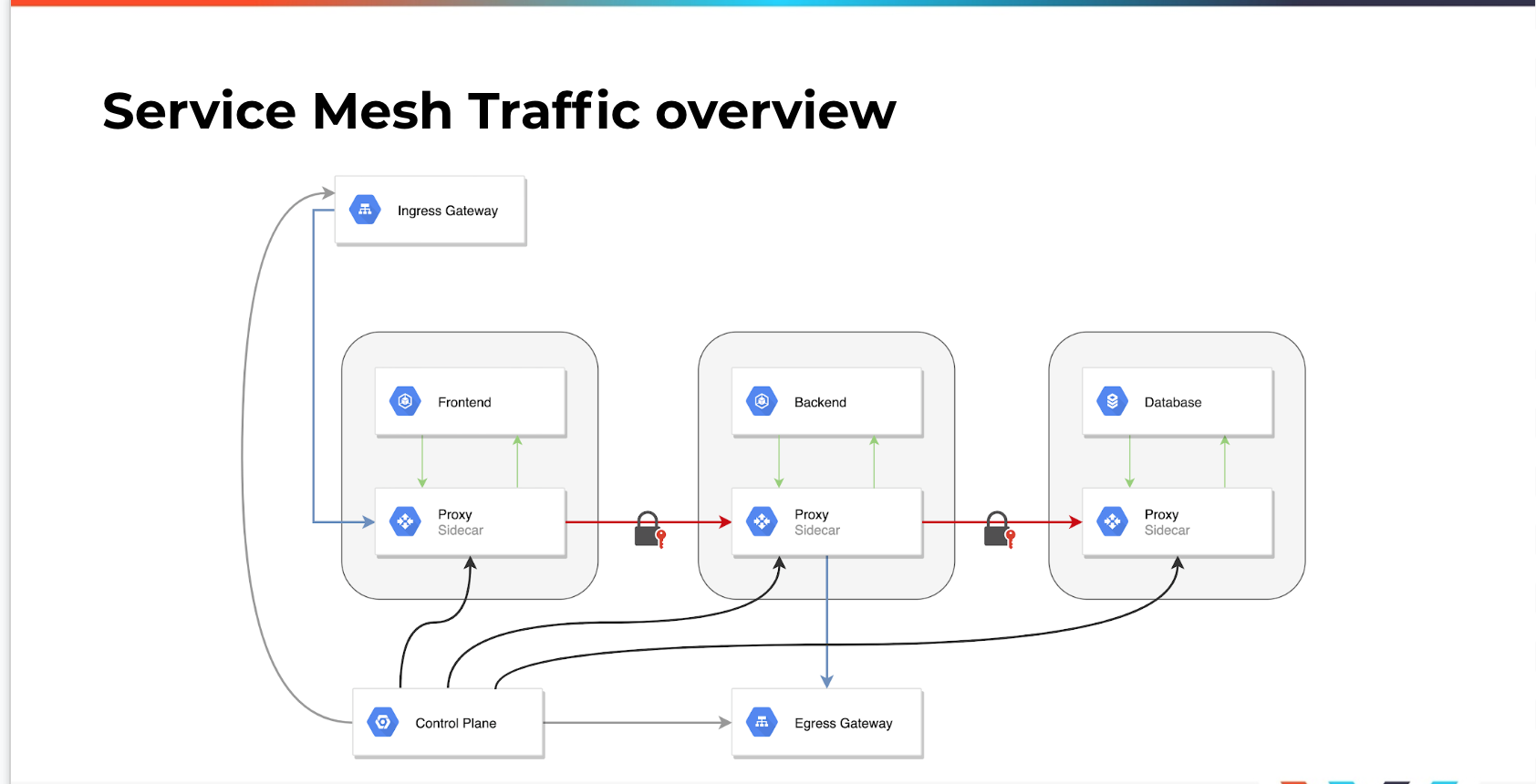
Vue d’ensemble du fonctionnement d’un service de maillage de services : des conteneurs “proxy” sont ajoutés dans chaque pod pour gérer les interactions avec le service mesh.239
Techniquement, un service mesh va s’installer sur votre logiciel d’orchestration (ex: Kubernetes) et attacher dans chaque pod (ensemble de conteneurs / application) un conteneur appelé sidecar. Ce dernier agira en tant que proxy réseau et gérera les interactions citées plus haut avec le service mesh.
En revanche, un service mesh n’est pas une technologie légère : elle nécessite de l’administration et de la formation en interne (à la fois pour les développeurs et les administrateurs) avant que vous ne puissiez bénéficier de ses avantages. Ne vous attendez pas à une technologie qui vous permette de passer de 50 à 5 administrateurs systèmes et qui soit administrable par seulement 2 personnes. Les service mesh ont un intérêt certain mais assurez-vous que vous soyez dimensionné pour en administrer un.
Plusieurs service mesh existent avec chacun leurs forces et leurs faiblesses. Prenez le temps de les comparer avant d’en choisir un. Par exemple, Linkerd240 sera plus simple à déployer que Istio, mais contiendra moins de fonctionnalités. Consul241 est une autre alternative.
Comme décrit dans le chapitre “Un socle au service de votre résilience”, les plateformes Cloud ont l’intérêt d’inclure tout un tas de services assurant des besoins communs de sécurité et de supervision. Ces services gèrent automatiquement des fonctionnalités historiquement fastidieuses à développer individuellement pour chaque logiciel, ou pour l’infrastructure.
Grâce aux CRDs242 ou en déployant les configurations Helm243 d’outils Cloud native244, il est possible de facilement “installer” des services socle au sein d’un cluster Kubernetes. Voici une liste non-exhaustive des services qui peuvent être déployés nativement dans votre cluster et qui sont administrables de manière centralisée :
Centralisation des logs et traces applicatifs et réseaux (cf. Filebeat, Fluentd (fig.
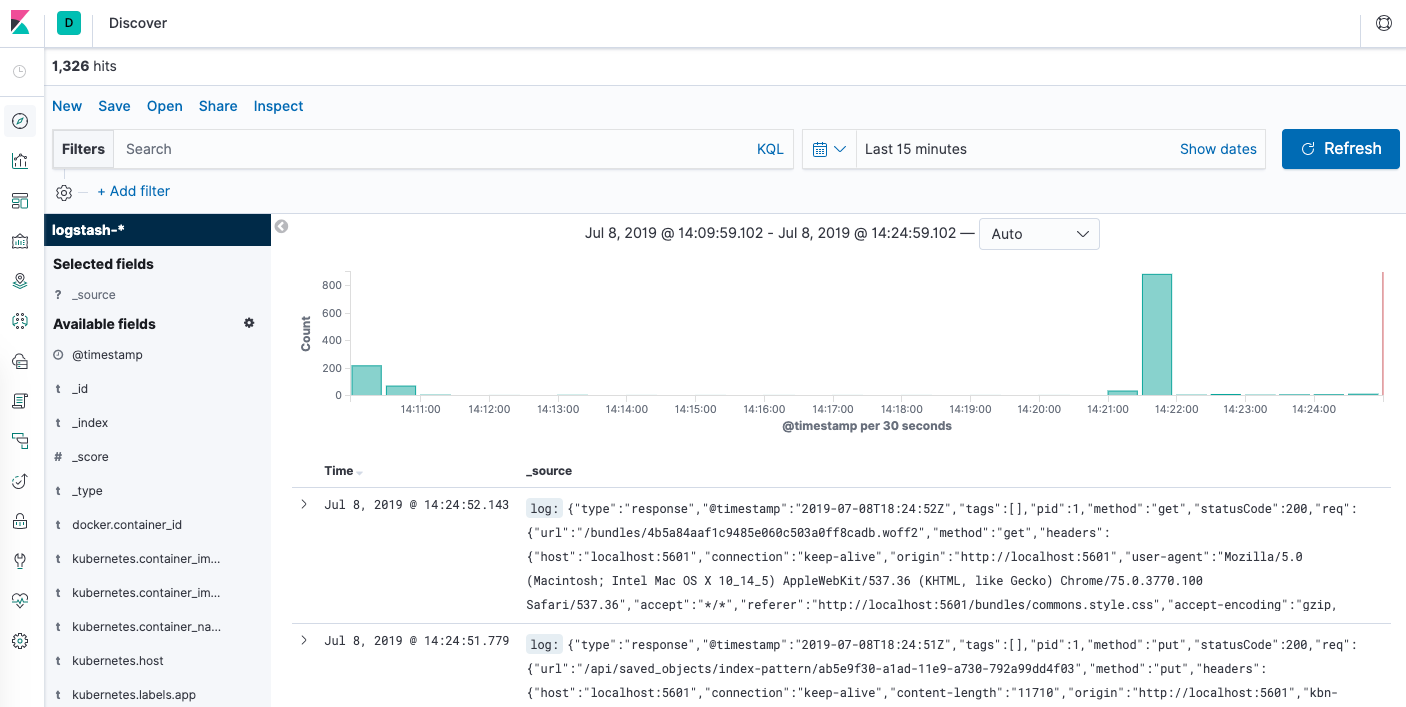
Centralisation des métriques de performance des nœuds et des conteneurs du cluster (cf. Mimir, Metricbeat, fig.
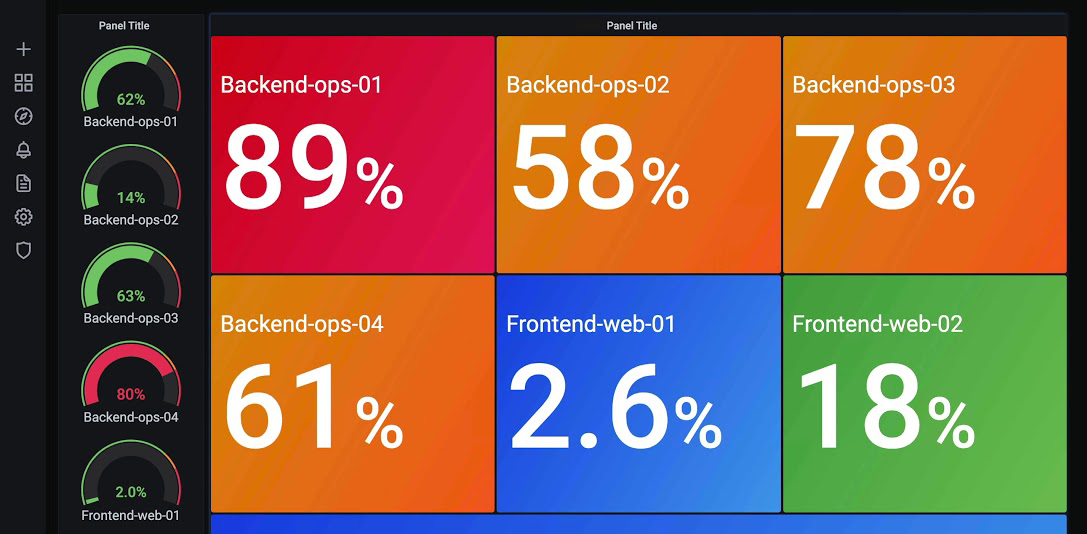
Analyse antivirus du contenu des nœuds et des conteneurs (cf. Docker Antivirus Exclusions, Kubernetes ClamAV)
Détection de comportements suspects d’appels système Linux (cf. Sysdig Falco)
Contrôle et audit des configurations du cluster (cf. Gatekeeper (fig.
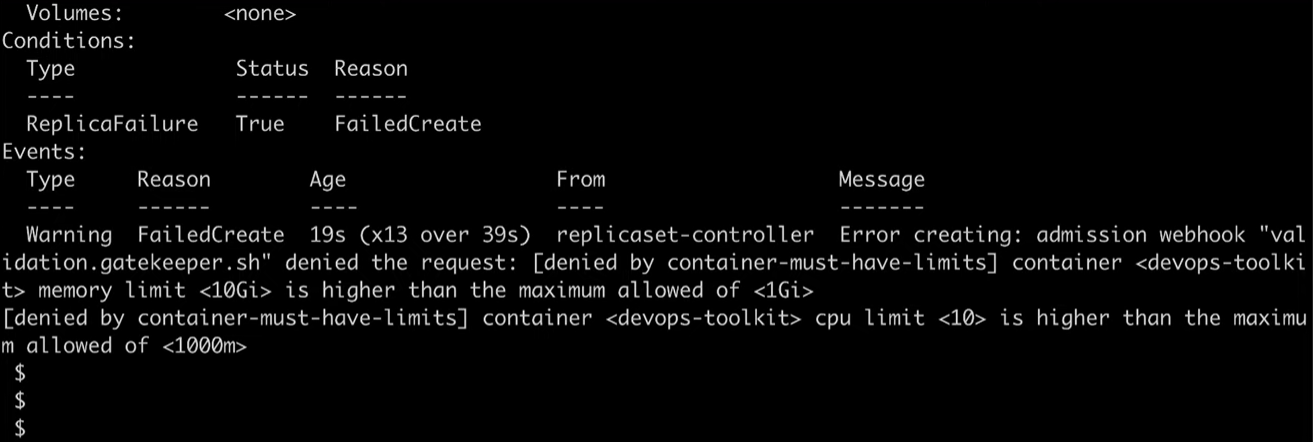
Gestion des secrets (mots de passe, tokens) des applicatifs (cf. Vault (fig.
Sauvegarde automatique des volumes persistants (cf. Velero)
Chiffrement des flux réseau entre les conteneurs (cf. chapitre “Service mesh”, fig.
details vers le pod details-v1. Source : istio.io.Gestion des certificats de sécurité (cf. chapitre “Service mesh”)
Gestion de l’authentification aux services web (cf. Istio Ingress Gateway, Keycloak)
L’intégration et l’automatisation sont les caractéristiques fondamentales d’un socle Cloud. Encore une fois, en DevOps, on estime que quelque chose qui n’est pas automatisé ne sera pas utilisé.
Les technologies évoquées ci-dessus s’interfacent automatiquement au logiciel déployé. En Cloud, ce n’est plus au logiciel de s’interfacer aux technologies du socle, c’est le socle qui s’interface aux logiciels.
Le chef de projet a la responsabilité de tout mettre en œuvre pour que le projet atteigne ses objectifs. Il joue souvent le rôle de product owner - un terme défini dans la méthode Agile - dont le rôle est de faire le lien entre les équipes techniques et métiers. C’est lui qui « vend » votre projet à vos utilisateurs.
Il est important que ce profil soit à la fois proche des utilisateurs finaux et des équipes techniques. Pour le premier dans l’objectif de comprendre les problématiques métiers et pour le second afin de bien saisir les enjeux d’ingénierie.
Quelquefois, le chef de projet va avoir tendance à « sur-vendre » les délais. Cette pratique génère du stress pour les équipes et provoque à terme de la frustration chez les utilisateurs. En effet, ces derniers se seront vus promettre un outil qui n’arrivera finalement que plus tard. Il s’agit donc de maîtriser les attentes.
« Under-promise, over-deliver »
Afin d’accélérer l’adoption de vos solutions, conviez un intervenant métier à vos présentations. Si cette personne est convaincue par votre produit, elle sera tentée de le présenter elle-même à votre assemblée pour expliquer à quel point il lui a été précieux dans son travail quotidien.
Arriver à faire témoigner vos utilisateurs à votre place est le meilleur moyen de gagner en crédibilité. Cela prouve que votre solution répond à un besoin. En illustrant un cas d’usage, vos invités se projetteront rapidement sur l’utilisation qu’ils peuvent faire de votre outil. Si vous souhaitez convaincre une audience ayant du mal à se projeter, le témoignage d’un métier est votre meilleur allié.
Tentez d’établir un réseau solide de quelques « ambassadeurs » (product advocates) au sein de votre organisation pour asseoir votre légitimité et soutenir votre initiative. En plus de ce soutien, l’ambassadeur vous permettra de capter les retours utilisateur ou d’en émettre lui-même pour affiner votre proposition de valeur.
Dans le privé et en particulier au sein des GAFAM246, il est courant pour les employés d’obtenir une journée hebdomadaire dédiée pour participer à un projet différent au sein de l’entreprise. Un jour sur cinq, ils choisissent de travailler au profit d’une autre équipe. Cette option est intéressante car elle profite à la fois à l’employé et à l’entreprise : l’employé découvre d’autres technologies et pratiques, monte en compétence et peut réinvestir ses connaissances au profit du reste des projets qu’il gère.
Il est également possible de citer le “Programme 10%” de la DINUM et de l’INSEE. Basé sur le volontariat, l’objectif est de proposer aux agents de la fonction publique de consacrer 10% de leur temps de travail à des projets d’intérêt commun247.
Tentez de proposer à votre hiérarchie cette possibilité afin que chaque collaborateur puisse bénéficier de ce programme : cela favorisera les échanges, rapprochera les équipes et fidélisera vos collaborateurs en leur permettant de découvrir et travailler sur de nouveaux sujets.
Afin de tirer parti de toutes les ressources à votre disposition, considérez l’emploi de personnels réservistes au sein de votre équipe si votre organisation le permet. Quand bien même ils ne seraient présents que quelques jours dans l’année, ils peuvent vous appuyer sur des tâches précises. Par exemple, un réserviste en sécurité des systèmes d’information vous aidera à boucler une homologation, un data-scientist à évaluer une solution d’intelligence artificielle ou apporter un appui ponctuel sur un jeu de données complexe à traiter.
Les grandes organisations se basent majoritairement aujourd’hui sur des prestations fournies par des industriels pour la réalisation de leurs projets techniques, soit en raison du manque d’experts en interne, soit du manque de RH, soit les deux. L’erreur est de s’abandonner à l’industriel et de se dire « c’est l’expert, tout va fonctionner, il suffit que je paye ». Toute personne ayant déjà mené un programme industriel s’est confrontée aux problématiques de compréhension des enjeux métiers par les parties prenantes (chefs de projets vs métiers vs industriels) et n’a pu que constater qu’un projet ne se déroule jamais 100% selon le plan prévu.
Se dire que le simple fait de payer un prestataire va nous apporter la solution attendue est une erreur stratégique. Si vous n’êtes pas un technicien expert du domaine et ayant récemment pratiqué, vous ne serez jamais au niveau pour juger efficacement les propositions de votre prestataire. Vous risquez soit de ne pas répondre à vos problématiques métier, soit de perdre de l’argent, soit probablement les deux.
Voilà pourquoi il est important de disposer en interne, au sein de vos propres équipes, des experts pratiquants du sujet que vous voulez développer. Ce sont les seuls qui seront capables de critiquer les propositions de vos prestataires pour vous faire gagner des délais et éviter que l’on vous dupe avec des fonctionnalités aux coûts exorbitants ou aux promesses irréalistes.
Chaque ingénieur DevOps et SRE le sait : il est impossible qu’un système fonctionne 100% du temps. C’est pourquoi vous ne pouvez pas attendre d’un prestataire, qu’importe le prix que vous paierez, qu’il livre quelque chose de 100% fonctionnel.
À titre d’exemple, même Google ne promet pas plus de 99.9% de disponibilité (SLA)248 avec sa capitalisation de plus de 1.6 trillions de dollars et ses quelques 150 000 employés rigoureusement sélectionnés. Amazon (AWS) et ses plus de 1.4 trillions de dollars de capitalisation ne garantit pas plus de 99.5%249.
La méthode traditionnelle des institutions pour travailler avec des industriels peut s’assimiler aux développements de type « waterfall » : une grande réunion est organisée pour recueillir le besoin, un cahier des charges technique et fonctionnel est rédigé pour structurer le contrat, les développements sont réalisés dans la foulée et le produit final est livré, clôturant le contrat.
Avec la dynamique intense du domaine numérique, cette méthode n’est plus optimale. La durée de vie moyenne d’un logiciel ne dépasse pas 3 à 5 ans250, quand bien même des mises à jours périodiques seraient apportées.
Prenons un exemple : vous avez la charge d’équiper votre organisation d’un nouvel outil numérique.
Résultat, le processus vous aura pris environ 1 an tout en n’ayant jamais mis l’outil entre les mains du métier. Vous n’êtes à cette étape même pas sûr qu’il réponde au besoin : rappelez-vous que le besoin exprimé n’est jamais vraiment le besoin effectif.
Le métier a enfin l’outil entre les mains : manque de chance, il ne répond pas pleinement au besoin, n’est pas pratique à utiliser et vos collaborateurs préfèrent rester sur les anciens outils qu’ils maîtrisent.
Il n’est plus concevable de travailler de cette manière aujourd’hui. L’une des pratiques du DevOps est de permettre « d’échouer rapidement », pour itérer plus régulièrement et atteindre plus rapidement la version qui répond au besoin. En ce sens, la méthodologie DevOps vous recommande de ne pas partir tête baissée sur une version « parfaitement aboutie » du cahier des charges : partez sur une première version, échouez, itérez et construisez l’outil parfait avec vos utilisateurs.
Vous vous souvenez de ce pilier ? « Réduire les silos organisationnels en impliquant chacun » : vous devez impliquer vos utilisateurs tout au long du cycle du projet. Si vous ne prenez pas régulièrement en compte leurs retours, le produit final risque de ne pas leur être utile. Quand bien même il serait utile, il serait peut-être trop complexe à utiliser et donc peu attirant.
En ce sens si vous souhaitez travailler efficacement avec une entreprise externe à votre organisation, vous devez rapprocher toutes les parties prenantes liées à ce projet. Faites en sorte que la voix de chacun puisse être entendue en mettant en place un moyen de communication simple et pratique à utiliser pour faire des retours et des suggestions. Par exemple, vous pourriez demander à l’industriel de vous partager l’accès à son usine logicielle (ex : GitLab, BitBucket, GitHub) pour y ajouter les commentaires de vos équipes et que les ingénieurs puissent y répondre en boucle courte.
GitLab permet aussi de réaliser du déploiement continu : l’industriel peut alors mettre à disposition de ses clients une URL permettant d’accéder à la dernière version du logiciel. Vous évitez ainsi les réunions de plusieurs heures et gagnez en flexibilité. L’objectif est atteint : vous itérez, rapidement.
La figure
représente la vue Kanban dans GitLab, où sont centralisés les commentaires sur un logiciel (tâches à réaliser, feedbacks, bugs…).
Dans le cas où vous ne pouvez pas agir sur vos pratiques avec l’industriel, organisez-vous a minima en interne pour disposer d’un outil de gestion de projet collaboratif. Par exemple, avec le logiciel Atlassian Confluence (fig.
.")
Exemple de vue Kanban dans Atlassian Confluence où sont centralisés les commentaires sur un logiciel (tâches à réaliser, feedbacks, bugs…).
À titre d’exemple, le ITZBund (Centre Fédéral Allemand des Technologies de l’Information, l’équivalent allemand de l’ANSSI251) emploie depuis 2018 au sein de son Bundescloud (cloud inter-ministériel) le logiciel open-source Nextcloud252. Ce dernier permet de partager des fichiers et collaborer sur une plateforme unifiée. Environ 300 000 utilisateurs institutionnels et industriels l’utilisent. Un an après, c’est le Ministère de l’Intérieur français qui l’adopte253.
Cette pratique est une approche gagnante pour chacun : le client voit les délais de livraison réduits, le métier obtient un outil qui répond mieux à ses besoins, l’industriel favorise l’opportunité d’une nouvelle contractualisation avec un client satisfait et le contribuable en a pour son argent. Globalement, tout le monde gagne du temps, est satisfait du résultat et se voit fidélisé en étant davantage impliqué dans chacune des interactions.
Il est impératif de mesurer les efforts que vous investissez dans votre initiative. Cela permet de constater factuellement l’efficacité de vos prises de décisions. Bien sûr, au début, il n’est pas rare d’observer une dégradation des performances puisque vous changez les habitudes, c’est à dire l’équilibre de l’organisation. Si vous observez une dégradation des indicateurs au cours du temps, vous savez que vous devrez adopter une autre stratégie pour corriger la tendance (cf. chapitre “Savoir quand innover et quand s’arrêter”).
Selon la recherche, la maturité technique d’une organisation permet de quadrupler la performance de ses équipes254. Découvrons quelques indicateurs utilisés dans l’industrie. Ces derniers font régulièrement l’objet de nombreux débats, mais semblent tout de même être la référence faisant consensus.
Le succès d’une initiative DevOps se mesure grâce à 4 mesures théorisées (4 key metrics255). À ces mesures s’ajoutent une cinquième qui révèle les performances opérationnelles de l’organisation. Elles font état des résultats obtenus à l’échelle globale de vos systèmes informatiques et de votre organisation plutôt que seulement sur des mesures logicielles. Ces dernières peuvent résulter d’amélioration locales, au détriment des performances globales. Découvrons-les :
Toutes ces mesures sont basées sur la disponibilité de l’infrastructure plutôt que sa résilience. Les chercheurs du rapport DORA ont en conséquence posé une nouvelle question aux organisations en 2021256. Cela a donné naissance à la cinquième mesure évoquée plus tôt :
Si vous construisez de zéro votre initiative, se comparer aux performance de l’industrie a peu d’intérêt. Gardez-les en tête pour savoir quel objectif viser mais n’estimez pas votre succès en fonction d’eux. Estimez-le selon la progression de vos propres mesures dans le temps. Tout le monde part d’une situation initiale dont l’objectif est de l’améliorer.
Le rapport DORA 2022 a classé les organisations sondées en trois catégories de performance (bas, moyen et haut) pour ses quatre mesures clé :
| Mesure | Bas | Moyen | Haut |
|---|---|---|---|
| Fréquence des déploiements | Entre 1 et 6 tous les 6 mois | Entre 1 et 4 par mois | A la demande (plusieurs par jour) |
| Délai de mise en production | < 6 mois | < 1 mois | < 1 semaine |
| Durée pour restaurer un service | < 1 mois | < 1 semaine | < 1 jour |
| Taux d’échec des déploiements | 46% - 60% | 16% - 30% | 0% - 15% |
GitLab permet même de visualiser en temps-réel ces mesures depuis la version 12.3 (fig.
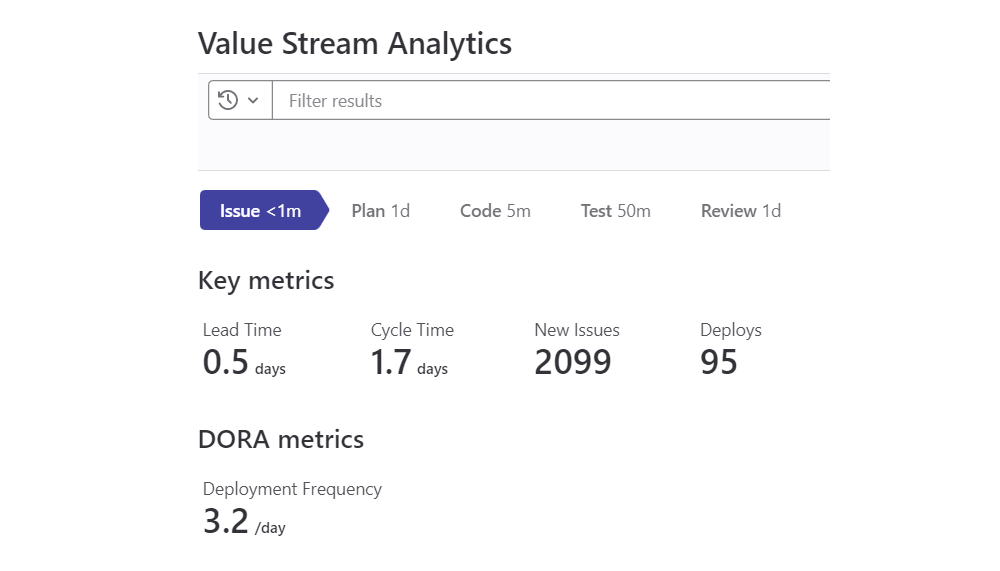
Si vous disposez d’une version assez récente de GitLab ou si avez mis en place des chaînes d’intégration continue, vous pouvez mesurer la plupart des phénomènes. Sinon, demandez à vos équipes de noter les évènements sur une interface collaborative (ex: Baserow, NocoDB, Google Sheets, Airtable, Atlassian Confluence).
A ces mesures s’en ajoute une que je nomme “tendance de collaboration résiliente” (resilient collaboration trend ou RCT). Elle capture l’essence d’une initiative DevOps selon moi : réussir à innover en continu, tout en maintenant une dette technique faible et en fournissant un service le plus disponible possible. Les facteurs suivants sont multipliés pour totaliser la valeur de l’indice de collaboration résiliente (RCI) :
On observe et on compare ensuite la tendance de cet indice au cours du temps. C’est cette tendance qui peut se comparer à d’autres projets.
Par exemple, le projet GitLab257 - l’un des plus gros projets open-source collaboratif - affiche sur le 2ème trimestre 2022 l’indice de collaboration résiliente 155 711 413, 188 809 628 (+17.5%) au 3ème trimestre et 202 865 477 (+7%) au 4ème trimestre. Ce dernier, avec 4102 jours depuis la création du projet git (9 octobre 2011 - 1 janvier 2023), 2474 contributeurs, 20 publications du logiciel (release) et une disponibilité moyenne de 99.95%258. Le projet a donc été moins véloce au 3ème qu’au 4ème trimestre (-10.5%).
Cet indice doit être actualisé tous les trimestres. Cet intervalle de temps peut être contracté ou étendu selon la maturité de votre organisation : plus vous êtes confiant sur votre capacité à déployer régulièrement, plus réduite peut être votre intervalle de mesure. Ex: sur un semestre, un trimestre, un mois ou une semaine.
Au contraire du SRE qui se base sur des mesures bien spécifiques (ex. les “Les 4 signaux clé”, les “Indicateurs de résilience”), le responsable DevOps a lui une certaine liberté pour choisir les mesures qui lui semblent les plus pertinentes. C’est à dire celles qui évaluent au mieux le service qu’il rend aux équipes internes. Néanmoins, le modus vivendi entre les DevOps et les SRE est le “délai de mise en production” : chacun œuvre à ce que ce paramètre soit le plus satisfaisant possible.
Votre organisation est parfois amenée à déployer des logiciels dans des environnements aussi variés que singuliers. Si vous avez de la chance, ces environnements sont peu nombreux et connectés. Mais cela se complique quand le nombre commence à grossir et qu’ils sont isolés. Il faut trouver un moyen standardisé de déployer ses mises à jour en réduisant au maximum les délais.
Basé sur Kubernetes, Apollo est le produit utilisé par Palantir pour déployer et garder à jour ses services chez l’ensemble de ses clients. Avec ses centaines d’ingénieurs, plus de 400 logiciels et des milliers de déploiements chaque jour, Palantir revendique le déploiement de ses services sur une centaine d’environnements informatiques différents (AWS, GCP, Azure, Clouds privés classifiés et déconnectés d’Internet, edge-servers avec connexion intermitente…)259.
Poussée par cette contrainte d’un déploiement régulier sur des infrastructures variées, les travaux autour d’Apollo ont commencé début 2015. Il a été progressivement déployé chez ses clients dès 2017 et se voit désormais mis en vente depuis début 2022, et fait tourner l’infrastructure interne de Palantir. La philosophie du produit est de s’interfacer avec vos infrastructures et services existants (forge logicielle, moteur d’intégration continue, registre d’artéfacts…)260.
L’entreprise part du principe que les ingénieurs logiciels et les SRE ont chacun leurs domaines d’expertise. D’un côté, les ingénieurs logiciels savent mieux comment et quand les logiciels qu’ils développent doivent être mis à jour. De l’autre, les SRE connaissent mieux les particularités et contraintes des environnements dans lesquels ils déploient261. Les ingénieurs logiciels développent donc le code, Apollo le déploie et les SRE surveillent que tout s’est déroulé comme prévu.
C’est pourquoi Apollo présente principalement deux menus dans son interface : “Environnements” (orienté SRE) et “Produits” (orienté ingénieurs logiciels).
Connecté à des répertoires git, il permet de suivre et d’approuver toute modification apportée au code avant son déploiement.
Enfin, Apollo permet une surveillance centralisée de l’état des services déployés dans tous vos environnements, depuis une même plateforme. Connecté à votre service d’observabilité favori (ex: Datadog, Prometheus, Pagerduty) ou en autonomie via la Apollo Observability Platform, il inclut la remontée de toute sorte de mesures (logs, metrics, traces) pour investiguer les incidents en détails.
Avec Apollo, Palantir introduit le concept de déploiement continu basé sur des contraintes (constraint-based continuous deployment)262. Apollo déploie dans chaque environnement un agent qui lui rapporte l’état réel de cet environnement pour savoir comment déployer les mises à jour. Apollo connaît ainsi l’état attendu des déploiements sur une infrastructure et l’état réel - à jour - de ces déploiements.
Les applications modernes faisant appel à des services externes, ce mécanisme permet d’éviter les incompatibilités entre les différentes versions d’une application déployée sur des environnements différents.
Par exemple, si l’application foo en version 1.1.0 requiert l’existence d’un service bar déployé avec la version 1.1.0, Apollo ne mettra pas à jour foo:1.1.0 tant que bar:1.1.0 n’est pas disponible et déployé. Le déploiement d’une nouvelle version d’un applicatif dépendant d’une version spécifique d’un autre est souvent géré manuellement, même si un mécanisme de déploiement continu est mis en place. En effet, les équipes doivent au préalable s’assurer que le service duquel dépend l’application (bar:1.1.0) est bien disponible et déployé, avant de déployer sa nouvelle version (foo:1.1.0). Ces dépendances sont inscrites au sein d’un fichier spécifique, dans le même projet que le code source de l’application.
La migration du schéma d’une base de données est un autre exemple. En déclarant la version d’un schéma de base de données compatible avec une version précise d’une application, Apollo évite de déployer une application incompatible avec une base de données qui n’a pas encore été mise à jour. Par exemple, si foo:1.1.0 ne supporte que la V2 du schéma de bdd:V1, foo:1.1.0 ne sera déployé que quand bdd:V1 aura migré à la V2. Apollo sait ainsi quelle version d’une application est éligible à être déployée dans quel environnement.
Dans les sondages, 47% des organisations déclaraient adopter une approche DevOps en 2016. Ce pourcentage atteint 74% en 2021263.
Entre 2019 et 2022, la répartition des initiatives DevOps par domaine d’activité est restée dans le même ordre de grandeur264 : largement dominée par le secteur technologique (~40%), suivit par le secteur financier (~12%) et le e-commerce (~8%). Le secteur institutionnel représente entre 2% et 4% de ces initiatives, laissant une grande place à l’innovation dans ce milieu.
Voici une répartition des entreprises pratiquant le DevOps en 2022265 :
La crise de 2019 a accéléré les initiatives de transformation numérique, augmentant la taille des équipes DevOps de 23%266 pendant cette période.
En 2022, la répartition géographique des organisations adoptant des pratiques DevOps est encore complexe à estimer. Néanmoins, elle semble se concentrer tout particulièrement dans la région nord-américaine. Cette dernière représente près de 33% des initiatives DevOps. Environ 33% également pour l’Europe et 33% pour l’Asie267 (avec l’Inde à 21%). En 2019, l’Amérique du Nord représentait 50% de ces initiatives, l’Europe 29% et l’Asie 9%. On observe donc un fort gain d’intérêt du sujet par les pays asiatiques.
La taille moyenne des équipes DevOps est encore limitée et tourne autour de 8 personnes268.
Cela fait du DevOps une méthodologie majoritairement adoptée dans les entreprises ayant atteint une masse critique et encore peu dans les entreprises non-technologiques.
La transformation d’une organisation, quelle qu’en soit sa taille, est une tâche complexe impliquant des enjeux politiques, techniques et humains importants. En cas d’échec, les conséquences peuvent être lourdes. Dans le même temps, il est crucial pour votre organisation d’envisager les conséquences à long terme si elle poursuit avec son modèle actuel. Le DevOps vise précisément à minimiser ces risques au travers de méthodologies et d’outils normalisés.
La recherche et l’expérience de milliers d’entreprises nous permettent aujourd’hui d’appréhender les défis liés à la transformation des organisations vers le Cloud. Ayant démontré son efficacité, les institutions commencent progressivement à porter leur attention sur le DevOps, bien que peu aient encore franchi le pas pour l’adopter (cf. chapitre “Répartition des initiatives”). Si l’une des grandes difficultés est encore de trouver des talents dans ce domaine, la première reste de convaincre l’entité dirigeante.
Plusieurs stratégies sont alors envisageables selon votre position hiérarchique et technique. La plus courante est de démarrer par un projet-pilote qui répond à des besoins interne (ex: le déploiement d’un logiciel co-construit avec vos métiers). Vous pourrez ainsi séduire de premiers partenaires internes (cf. chapitre “Modèle d’équipe interne”).
Rendez des services au plus tôt pour démontrer l’efficacité de votre approche vis-à-vis des approches traditionnelles (ex: logiciel mieux adapté au besoin, déploiement simplifié, réponse rapide aux incidents…). Une fois les primo adoptants convaincus, faites-les témoigner lors de vos présentations devant les décideurs. Les métiers acceptent souvent de le faire car ils se sentent redevables pour les services rendus. D’un impact redoutable, vous pourrez ainsi fédérer progressivement une communauté pour porter votre vision plus haut (cf. chapitre “Comment convaincre et garder la foi”).
Faire accepter le changement est avant tout le sujet de minimiser les risques entrepris. Commencer petit pour itérer est le meilleur moyen de réussir. Qui plus est, en étant conscient des réalités psychologiques et techniques derrière un projet de transformation, vous aurez toutes les clés et les arguments pour réaliser une transition plus rapide et moins périlleuse (cf. chapitre “Les initiatives dans les organisations”). Présenter les technologies Cloud et le DevOps comme une évolution plutôt que des techniques disruptives est un moyen efficace pour convaincre.
Tout comme les grandes entreprises qui investissent constamment dans les nouvelles technologies, chaque organisation doit être prête à prendre des risques pour rester compétitive. Votre comité exécutif doit rester à l’écoute des points de vue qui le surprennent et encourager les expérimentations.
Par exemple, il est important de ne pas sous-estimer le potentiel des employés considérés difficiles à encadrer. Certains sont peut-être les visionnaires qui vous permettront d’exister demain. Étudier avec sérieux l’impact de leurs idées est essentiel, au risque de passer à côté d’opportunités cruciales pour l’avenir de l’organisation (cf. chapitre “Réduire les silos organisationnels”).
Alors que les métiers auxquels vous rendrez service y voient un intérêt immédiat, l’intérêt est souvent plus abstrait pour l’équipe dirigeante. En tant qu’instigateur d’une transformation, vous devez donc investir du temps à acculturer les décideurs de votre organisation. N’hésitez pas à repartir des notions de base sur le Cloud pour faire progressivement comprendre les enjeux du DevOps aux parties prenantes. Il est fondamental de trouver des exemples sur la manière dont vous avez pu résoudre des dysfonctionnements internes à l’aide de votre approche.
L’instigateur doit toujours rester prêt à répondre aux questions suivantes des décideurs :
L’entité dirigeante est maintenant convaincue et vous donne les moyens techniques et politiques de mettre en place votre projet. L’aventure ne fait que commencer ! Ne communiquez pas trop tôt sur des capacités que vous ne maîtrisez pas encore. Commencez à y donner uniquement accès à une fraction d’utilisateurs volontaires et construisez vos procédures (gestion, administration, incidents).
Votre initiative rencontrera nécessairement des écueils à ses débuts. Accueillez les retours avec bienveillance et améliorez vos services. Une fois que vous êtes confiant sur la fiabilité des services, déployez-les à plus large échelle puis communiquez abondamment.
Vous constaterez rapidement que les priorités opérationnelles (ou commerciales) empêchent souvent de se consacrer à des travaux d’infrastructure (Cloud/DevOps), en faveur de développements produit (logiciels). La recherche démontre pourtant que se structurer autour de ces méthodes éprouvées permet de gagner en efficacité sur le long terme (cf. chapitre “Pourquoi le DevOps ?”). Veillez donc à préserver du temps pour les travaux de résilience dans l’emploi du temps de vos ingénieurs.
Une infrastructure DevOps révêle son plein potentiel une fois connectée au réseau principal de votre organisation. Elle permettra alors de déployer des mises à jour fréquentes, répondre rapidement aux incidents et mutualiser les travaux de vos équipes. Si votre projet a débuté sur une plateforme isolée, portez désormais les efforts à vous connecter là où sont présents vos utilisateurs (cf. chapitre “Les piliers du DevOps en pratique”).
Mesurer l’efficacité de son initiative au cours du temps est critique : à la fois pour s’assurer que l’on avance sans dogmatisme dans la bonne direction, mais aussi pour donner des arguments chiffrés à sa hiérarchie ou aux équipes qui ont encore besoin d’être convaincues. Veillez à garder un tableau de bord clair de ces indicateurs (cf. chapitre “Mesurer le succès de sa transformation”).
Les outils tels que ChatGPT basés sur les LLMs offrent autant de nouvelles opportunités (ex: GitLab Duo, GitHub Copilot) qu’ils exposent à de nouvelles menaces (compétences internes, deepfakes). En parallèle, les standards en matière de sécurité continueront d’évoluer à un rythme effréné. Cela plaide pour une transformation des organisations vers un univers numérique plus agile. Le futur se dessine aujourd’hui et les structures qui réussiront le mieux seront celles qui arrivent à s’approprier les dernières technologies pour les intégrer à leur cycle de développement logiciel (cf. chapitre “Refuser le retard technologique”).
Au delà de la vitesse à laquelle la technologie évolue et comme pour tout domaine d’expertise, ce type d’infrastructure nécessite l’entretien des compétences requises pour l’administrer.
Nous arrivons facilement à nous imaginer qu’un pilote de chasse entretienne son aptitude à piloter. Pourquoi cela serait-il différent pour des ingénieurs qui réalisent la maintenance de logiciels critiques au bon fonctionnement de l’institution ? Vous et vos équipes devez continuer d’être à la pointe en vous formant (cf. chapitre “Former de manière continue”).
En mode DevOps, les organisations peuvent se permettre d’échouer plus rapidement, avec un risque maîtrisé, pour innover avant leurs compétitrices.
Maintenant que vous comprenez la variété des enjeux du DevOps, il est intéressant de découvrir quelques termes que l’on peut entendre ci et là dans le domaine.
Vous avez probablement déjà entendu une multitude de termes suffixé par “Ops” dans les propositions industrielles, les offres d’emploi ou les services en ligne. Tous ces termes décrivent des spécialités de l’exploitation des systèmes informatiques au travers de différentes techniques et de méthodologies. Définissons en quelques-uns :
L’émergence de ces termes qualifiant des spécialités ou des pratiques de l’administration d’infrastructures informatiques est probablement liée à la maturité qu’a gagnée l’industrie grâce aux services Cloud. Ces derniers ont fortement simplifié l’administration des infrastructures et permis de mener des réflexions plus avancées pour les optimiser.
Chacune de ces spécialités est un moyen d’optimiser vos pratiques DevOps et doit s’adapter à la maturité de l’institution. Ne vous mettez pas en tête de toutes les mettre en place avant d’avoir bien appréhendé et mis en pratique le DevOps dans votre organisation.
Ce chapitre répertorie des exemples de fiches de postes dans le domaine du DevOps.
Pour éviter de perdre du temps et limiter les mauvais recrutements, votre objectif organisationnel doit être clairement défini.
S’il n’est pas bien défini, la fiche de poste risque de devenir un fourre-tout de tâches techniques qui pourraient occuper une équipe d’ingénieurs complète. Vous risquez alors de passer pour une organisation peu mature et repousser les meilleurs candidats.
Vous devez faire l’effort de définir le périmètre du poste que vous recherchez, ou bien assumer le fait que votre environnement est si singulier qu’il nécessite une réadaptation très régulière (voire “tactique”). Hormis dans les secteurs de la sécurité et de la défense, vous ne devriez pas considérer votre activité comme telle.
Les exemples de fiches de poste ci-dessous sont indicatifs et doivent être adaptés à votre situation (maturité et taille des équipes, de l’organisation). Modifiez le contexte et les missions que vous souhaitez confier à votre futur ingénieur. Éditez également les compétences que vous souhaitez mettre en avant selon votre projet du moment.
Les niveaux d’exigence des postes sont décrits selon la maturité technique de l’entreprise (débutante, intermédiaire, avancée) et le niveau d’expérience attendu du candidat (junior, intermédiaire ou senior).
Une section “Formation ou expérience” est également disponible pour vous donner une idée des cursus que le candidat pourrait avoir suivi pour prétendre au poste. Néanmoins, considérez dans l’informatique que le diplôme n’est plus d’aucune importance après 5 ans d’expérience professionnelle. C’est cette dernière et les projets que le candidat réalise qui définissent son niveau d’expertise.
| Niveau du poste | Intermédiaire à senior273 (selon responsabilités à confier au candidat). Apprentissage ou junior possible si personnel expérimenté dans l’équipe. |
| Maturité de l’organisation | Débutante à intermédiaire |
| Rémunération approximative (septembre 2023) | >42k€/an (débutant), >60k€/an (senior) |
Dans le cadre de la transformation numérique de notre organisation et appuyé(e) par notre hiérarchie, vous aiderez à définir les nouveaux processus de développement, de déploiement et d’administration de notre organisation.
Vous mettrez en place les outils et pratiques DevOps au profit de la productivité de nos développeurs et accompagnerez les équipes internes dans leur adoption.
À partir des technologies actuellement utilisées dans nos équipes, vous participerez aux réflexions stratégiques relatives aux technologies à adopter pour l’amélioration de notre organisation.
À l’interface entre nos équipes de développement et au sein de notre équipe SRE de X personnes, vous aurez la charge :
Compétences :
Formation ou expérience :
Vous avez au moins 5 ans d’expérience professionnelle ? Nous la privilégions et ne tenons pas compte de votre diplôme274.
Ce poste peut mener au poste d’Ingénieur Systèmes, de SRE ou d’Ingénieur SSI DevOps.
| Niveau du poste | Intermédiaire ou senior (selon responsabilités à confier au candidat). Apprentissage ou junior possible si personnel expérimenté dans l’équipe. Pas de stage (trop court). |
| Maturité de l’organisation | Intermédiaire à avancée |
| Rémunération approximative (septembre 2023) | >54k€/an (intermédiaire), >72k€/an (senior) |
Aux fondements du bon fonctionnement de notre organisation, vous aurez la charge de garantir la disponibilité, la fiabilité et la résilience de nos systèmes d’information. Vous veillerez à pérenniser les infrastructures en assurant un équilibre entre la vélocité des développements et la stabilité des systèmes.
Au sein de notre équipe SRE de X personnes, vous aurez la charge :
Compétences :
Formation ou expérience :
Vous avez au moins 5 ans d’expérience professionnelle ? Nous la privilégions et ne tenons pas compte de votre diplôme.
Ce poste peut mener au poste de Responsable de l’Infrastructure, d’Ingénieur SSI DevOps ou d’Ingénieur Systèmes.
| Niveau du poste | Junior à senior (selon responsabilités à confier au candidat) |
| Maturité de l’organisation | Intermédiaire à avancée |
| Rémunération approximative (septembre 2023) | >52k€/an |
Dans le cadre de la transformation numérique de notre organisation, appuyé(e) par la hiérarchie, vous êtes le “Sec” de notre organisation en mode “DevSecOps”. Votre rôle est de garantir la mise en œuvre des bonnes pratiques de sécurité sans impacter la vélocité des développements.
Intégré au sein de notre équipe SRE, vous aurez la responsabilité de sécuriser l’ensemble de la chaîne de développement et de déploiement logicielle. À partir des politiques de sécurité et des contraintes légales imposées à notre organisation, vous traduirez ces règles documentaires en code (dans des CI) ou au travers de la mise en place d’outils, pour garantir leur application. Vous définirez les pratiques de sécurité à adopter pour le présent et le futur de notre organisation.
À l’interface entre nos équipes de développement et notre équipe SRE, vous aurez la charge :
Compétences :
Formation ou expérience :
Vous avez au moins 5 ans d’expérience professionnelle ? Nous la privilégions et ne tenons pas compte de votre diplôme.
Ce poste peut mener au poste d’Ingénieur Systèmes ou de SRE.
| Niveau du poste | Intermédiaire à senior |
| Maturité de l’organisation | Avancée |
| Rémunération approximative (septembre 2023) | >44k€/an (débutant), >48k€/an (intermédiaire) |
De formation ingénieur logiciel ou administrateur système avec des compétences avérées en ingénierie logicielle, vous serez responsable du développement et de la maintenance des outils qui améliorent au quotidien le cycle de développement et de déploiement de nos logiciels.
Au sein de l’équipe SRE, vous développerez les outils d’administration ou en intégrerez de nouveaux pour faciliter la vie de nos développeurs et de nos SRE.
Vous participerez à la mise en place d’un data-lake dans le cadre de l’initiative gouvernementale data.gouv.fr.
Compétences :
Formation ou expérience :
Vous avez au moins 5 ans d’expérience professionnelle ? Nous la privilégions et ne tenons pas compte de votre diplôme.
Gartner. Gartner Says Cloud Will Be the Centerpiece of New Digital Experiences. 2021.↩︎
Atlassian; CITE Research. “2020 DevOps Trends Survey”. 2020.↩︎
National Assembly Law Information (Corée du Sud). “Cloud Computing Act”. 2015.↩︎
National Information Resource Service (Corée du Sud). “History (of NIRS)”. nirs.go.kr.↩︎
Document téléchargeable : links.berwick.fr/SPnDtI↩︎
Gouvernement du Canada. “Objectif 2020”. 2013.↩︎
Gouvernement du Canada. “Government of Canada Cloud Adoption Strategy”. 2018.↩︎
Ministry of Defence (Royaume-Uni). “Defense AI strategy”. 2022.↩︎
Détails de l’appel d’offre et du déroulé du programme NELSON disponible sur digitalmarketplace.service.gov.uk.↩︎
Department of Defense (États-Unis). “DoD IT Enterprise Strategy and Roadmap”. 2011.↩︎
Department of Defense (États-Unis). “DoD Enterprise DevSecOps Reference Design”. 2019.↩︎
WANG, Abel (DevOps Lead à Microsoft). “Enterprise DevOps Transformation” (vidéo YouTube). 2020.↩︎
Par exemple, l’affaire du pacte de défense AUKUS↩︎
AUDINET, Maxime; LIMONIER Kevin. “Le dispositif d’influence informationnelle de la Russie en Afrique subsaharienne francophone : un écosystème flexible et composite, Questions de communication, 41 | 2022, 129-148”.↩︎
GAFAM : Grandes entreprise technologiques américaines (Google, Facebook, Amazon, Apple, Microsoft). Synonymes : FAANG, NATU, MAMMA, MANAMANA.↩︎
NATU : Autres grandes entreprises technologiques américaines, plus récentes dans l’usage (Airbnb, Tesla, Uber, Netflix).↩︎
Multiple cas d’usage et témoignages d’entreprises de tout type de domaines sur cloud.google.com/transform.↩︎
InfoQ. Podcast “Andrew Clay Shafer on Three Economies, the Wall of Confusion, and the Origin of DevOps”. 2020.↩︎
KIM, Gene; DEBOIS, Patrick; WILLIS, John; HUMBLE, Jez; ALLSPAW, John. The DevOps handbook: how to create world-class agility, reliability, and security in technology organizations. 2015.↩︎
“SRE is the practical implementation of DevOps.” (chapter “SRE compared to DevOps”). aws.amazon.com/what-is/sre.↩︎
Voir la micro-étude “Définitions DevOps et SRE” de ce projet : github.com/flavienbwk/book-devops/studies/devops-sre.↩︎
BERWICK, Flavien. Les bases de la QA : article Medium “Keep your code and documentation fresh”. 2023.↩︎
Google. Chapitre “How SRE Relates to DevOps”, SRE Book. sre.google.↩︎
PAUPIER, François; CHAILLAN, Nicolas. Postmortem #19 : Le DevSecOps à l’US Air Force. 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Context matters”, page 6. 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Acknowledge the J-Curve”, page 28. 2022.↩︎
En 2021, 74% des organisations déclaraient adopter une approche DevOps. Statistiques par Redgate. “The 2021 State of Database DevOps”. 2021.↩︎
L’AR-15 est un fusil semi-automatique léger produit par la société américaine ArmaLite.↩︎
Revue Défense Nationale. “Les défis de la « haute intensité » : enjeu stratégique ou capacitaire ?”. 2020.↩︎
Programme DevSecOps Vulcan de la Defense Information Systems Agency (DISA) américaine. 2022.↩︎
Platform One est une plateforme lancée en 2018 par l’US Air Force permettant la collaboration logicielle dans une démarche DevSecOps, à l’échelle du Ministère des Armées des États-Unis.↩︎
Post LinkedIn de Nicolas CHAILLAN (créateur de Platform One) déclarant avoir proposé à la DISA de collaborer sur Platform One, en réaction à l’annonce de la DISA disant vouloir créer une plateforme DevSecOps. 2022.↩︎
Breaking DEFENSE. Article “Learning from Ukraine, DISA extends Thunderdome to include classified SIPRNet”. 2022.↩︎
Phénomène du sujet supposé savoir, selon lequel un individu va donner du crédit à un expert externe par le simple fait qu’il le pense plus légitime que lui-même ou que l’expert interne, pourtant les seuls à connaître les besoins réels de l’organisation. Théorie de Jacques LACAN. « Séminaire Les quatre concepts fondamentaux de la psychanalyse. Les fondements de la psychanalyse ».↩︎
CHRISTENSEN MAGLEBY, Clayton. Livre “Le dilemme de l’innovateur : lorsque les nouvelles technologies sont à l’origine de l’échec de grandes entreprises”. 1997.↩︎
Sources statista.com : fr.statista.com/statistiques/559394↩︎
Reuters. “Alphabet shares dive after Google AI chatbot Bard flubs answer in ad”. 2023.↩︎
CNN. “Microsoft’s Bing AI demo called out for several errors”. 2023.↩︎
PICHAI, Sundar. “An important next step on our AI journey”. 2023.↩︎
SILBERZAHN, Philippe. Le syndrome du canard: comment les organisations en déclin s’habituent à la médiocrité. 2022.↩︎
DUNLAP, Preston. Defying gravity. 2022.↩︎
WIGGINS, Adam. The New Heroku (Part 4 of 4): Erosion-resistance & Explicit Contracts. 2011.↩︎
MORGAN, William. How to get a service mesh into production without getting fired (conférence). 2018.↩︎
Référence à la Théorie des Modèles Mentaux introduite par JOHNSON-LAIRD en 1983 (cf. THEVENOT C, PERRET P. Le développement du raisonnement dans la résolution de problèmes: l’apport de la théorie des modèles mentaux. Développements. 2009).↩︎
SILBERZAHN, Philippe. Stratégie modèle mental. 2022.↩︎
DevOps Institute. Global Upskilling IT report, chapitre “Industry” (page 162). 2022.↩︎
Théorie populaire sur l’innovation, inspirée du discours de Nicholas KLEIN, avocat du premier syndicat américain du textile (l’Amalgamated Clothing Workers of America), en 1918.↩︎
“Cette technique est imaginée par Louis Renault en 1898 et mise en œuvre par Henry Ford en 1913”. Source : fr.wikipedia.org/wiki/Ligne_de_montage↩︎
VANCE, Ashlee. Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic Future. page 83. 2016.↩︎
Allocution d’Elon MUSK à l’occasion de l’atterrissage contrôlé de Falcon 9, une fusée réutilisée, sur la rediffusion vidéo de SpaceX “It’s been 15 years to get to this point… This is a great day… in proving that something could be done that many people said was impossible” le 30 mars 2017.↩︎
Idée centrale ou le message principal que l’orateur souhaite communiquer à son public, généralement dans le but qu’il prenne une action.↩︎
Echelons de stratégie militaire, définissant des temps et des espaces d’action différents. Source : fr.wikipedia.org/wiki/Stratégie_militaire↩︎
“(Le Conseil scientifique) assiste Santé publique France dans sa mission de contribution à l’élaboration et à la mise en œuvre des politiques nationale et européenne de santé publique”. santepubliquefrance.fr. 2022.↩︎
Modèles d’intelligence artificielle : algorithmes entraînés pour résoudre une tâche, la plupart du temps sans supervision↩︎
Drivers GPU : librairies permettant de faire du calcul accéléré sur carte graphique↩︎
Jupyter Notebook : outil de développement populaire chez les data-scientists↩︎
Le “porteur” qualifie la structure, les machines et les équipements lourds d’un bateau.↩︎
Vœux du CEMA Thierry BURKHARD. “… les chefs doivent s’adapter à l’accélération de notre monde si nécessaire en prenant des risques calculés.”. 2022.↩︎
Blog de Henrik Kniberg. blog.crisp.se/author/henrikkniberg.↩︎
La certification “critères communs” de l’ANSSI requiert la définition d’une version du logiciel audité.↩︎
Google Cloud. Announcing the 2022 Accelerate State of DevOps Report: A deep dive into security. 2022.↩︎
Syndrome d’épuisement professionnel, ou burnout en anglais.↩︎
Source: cyber.gouv.fr/comprendre-la-qualification↩︎
L’évaluateur tiers doit être un PASSI (Prestataires d’Audit de la Sécurité des Systèmes d’Information).↩︎
Source: cyber.gouv.fr/comprendre-la-certification↩︎
OIV : Organisme d’Importance Vitale↩︎
Une contribution qualifie toute modification apportée à une base de code. Cela peut être l’ajout d’une ligne de code, de documentation, la suppression d’un fichier ou encore l’ajout d’une issue.↩︎
AWS CodePipeline. aws.amazon.com/codepipeline.↩︎
GitLab required approvals documentation. GitLab.com.↩︎
Scripts qui analysent le code source pour signaler les erreurs de programmation, les bugs, les erreurs stylistiques et les constructions suspectes de code. L’objectif du linting est d’imposer un style de code cohérent et de trouver des erreurs potentielles avant l’exécution du code.↩︎
Administration BIDEN. FACT SHEET: President Signs Executive Order Charting New Course to Improve the Nation’s Cybersecurity and Protect Federal Government Networks. 2021.↩︎
Administration BIDEN. Executive Order on Improving the Nation’s Cybersecurity. 2021.↩︎
Administration BIDEN. National Security Memorandum. 2022.↩︎
OWASP DevSecOps Maturity Model (DSOMM). dsomm.owasp.org.↩︎
DataDog DevSecOps Maturity Model. datadoghq.com.↩︎
AWS Security Maturity Model. maturitymodel.security.aws.dev.↩︎
GitLab DevSecOps Maturity Assessment. about.gitlab.com.↩︎
National Telecommunications and Information Administration’s SOFTWARE BILL OF MATERIALS. ntia.gov.↩︎
Les CIS Benchmarks sont un ensemble de règles et de bonnes pratiques de configurations informatiques. Elles sont publiées par l’association américaine Center for Internet Security (CIS).↩︎
Source Code Analysis Tools. owasp.org.↩︎
Vulnerability Scanning Tools. owasp.org.↩︎
Free for Open Source Application Security Tools. owasp.org.↩︎
A ne pas confondre avec les frameworks logiciels comme ReactJS ou Symfony, un framework peut désigner une simple documentation, regroupant un ensemble de règles et de spécifications cadrant l’usage de technologies pour répondre à une problématique (ex: sécuriser la chaîne logicielle).↩︎
Supply chain Levels for Software Artifacts (SLSA, prononcé “salsa”) est un ensemble de règles de sécurité recommandées pour sécuriser sa chaîne de développement et de déploiement logiciel.↩︎
Google Cloud. Binary Authorization for Borg (BAB). 2022.↩︎
Projet GitHub du projet FRSCA : github.com/buildsec/frsca.↩︎
Projet GitHub du projet SLSA. github.com/slsa-framework/slsa.↩︎
Projet GitHub du SSCSP : github.com/cncf/tag-security/blob/main/supply-chain-security/supply-chain-security-paper↩︎
Projet GitHub du security technical advisory group de la CNCF : github.com/cncf/tag-security↩︎
CNCF. Announcing the Refreshed Cloud Native Security Whitepaper. 2022.↩︎
NIST. Secure Software Development Framework version 1.1, doi:10.6028/NIST.SP.800-218. 2022.↩︎
OWASP Software Component Verification Standard. scvs.owasp.org.↩︎
Un commit est une modification apportée à un fichier dans une base de code. Cela peut être une documentation, du code informatique ou encore un fichier de configuration.↩︎
Bibliothèque en ligne du Directeur de l’Information de l’US Department of Defense : dodcio.defense.gov/library↩︎
La liste des CVE est supervisée par le MITRE, un organisme subventionné par la CISA (Cybersecurity and Infrastructure Security Agency) qui fait partie du Département de la Sécurité Intérieure des États-Unis.↩︎
Iron Bank presentation from Platform One’s Big Bang. U.S. department of defense.↩︎
Site web du projet Platform One. p1.dso.mil.↩︎
Iron Bank Hardening guide overview. docs-ironbank.dso.mil.↩︎
GLENN, Eddie. How to secure your software build pipeline using code signing. 2021.↩︎
SANS. SANS 2022 Security Awareness Report: “Human Risk Remains the Biggest Threat to Your Organization’s Cybersecurity”. 2022.↩︎
OKTA. State of zero trust report. 2022.↩︎
What is the castle-and-moat network security model ? cloudflare.com.↩︎
BCG; ANDRH. Étude “Le futur du travail vu par les DRH - 2ème édition”. 2022.↩︎
CASB / Cloud Access Security Broker : service intermédiaire autorisant ou non l’accès à un applicatif par un utilisateur.↩︎
Le Zero Trust Network Access (ZTNA) est une catégorie de technologies qui fournit un accès à distance sécurisé aux applications et aux services sur la base de politiques de contrôle d’accès définies. Définition par paloaltonetworks.com.↩︎
SASE / Secure Access Service Edge : combinaison de plusieurs fonctions de sécurité réseau pour permettre l’accès dynamique aux ressources d’une organisation↩︎
ANSSI. Le modèle zero trust. 2021.↩︎
RORY, Ward; BEYER, Betsy. “BeyondCorp: A New Approach to Enterprise Security”. 2014.↩︎
NIST’s Implementing a zero trust architecture website : nccoe.nist.gov/projects/implementing-zero-trust-architecture↩︎
US Department of Defense. Cloud Native Access Point specifications. 2021.↩︎
Codespaces est un produit de GitHub permettant de lancer un environnement de développement éphémère directement dans GitHub : github.com/features/codespaces.↩︎
Coder est un outil similaire à Codespaces pour du on-premise, permettant d’instancier un environnement de développement tournant sur une machine à distance : github.com/coder/coder.↩︎
Environnement de développement fournissant un IDE sur un pod Kubernetes. github.com/eclipse/che.↩︎
OVH Shadow est un service Cloud permettant d’accéder à des machines à distance par Internet. shadow.tech.↩︎
Microsoft; Sogeti. Securing Enterprise DevOps Environments, chapitre “Control the developer environment with a cloud environment” page 9. 2022.↩︎
IDE : Integrated Development Environment. Interface de saisie et de gestion du code. Ex: Visual Studio Code (VSCode), Atom, IDEs JetBrains.↩︎
Les Public Key Infrastructure (PKI) ou Infrastructure de Gestion de Clés (IGC) sont des technologies (logicielles et/ou matérielle) permettant de gérer le cycle de vie (création/révoquation) des certificats de sécurité d’une infrastructure. Usages non-exhaustifs: signature électronique, chiffrement des données, certificats “HTTPS”.↩︎
Active Directory (AD) est un service d’annuaire dans lequel les administrateurs système peuvent gérer les contrôles d’accès à différentes ressources de l’infrastructure. Il tourne sur Microsoft Windows Server.↩︎
ANSSI. Recommandations de sécurité relatives aux déploiements de conteneur Docker. 2020.↩︎
Un sidecar est un conteneur distinct qui s’exécute aux côtés d’un conteneur applicatif dans un pod Kubernetes.↩︎
Helm est une technologie standardisant et simplifiant le déploiement d’applicatifs dans Kubernetes. helm.sh.↩︎
Exemple de système d’exploitation : Debian, Ubuntu, Alma Linux, Microsoft Windows 10, Apple MacOS. Anglais : operating system (OS).↩︎
Open Source Initiative; Perforce. “State of Open Source survey”. 2022.↩︎
OpenForum Europe; Fraunhofer ISI. “Study on the impact of Open Source for the European Commission”. 2021.↩︎
McALLISTER, Neil (The Register). “Redmond top man Satya Nadella: ‘Microsoft LOVES Linux’”. 2014.↩︎
WARREN, Tom (The Verge). “Microsoft has some old bad habits the community needs to trust won’t happen again” : Here’s what GitHub developers really think about Microsoft’s acquisition. 2018.↩︎
LARDINOIS, Frederic (Techcrunch). “Four years after being acquired by Microsoft, GitHub keeps doing its thing”. 2022.↩︎
Techcrunch. “Protestware on the rise: Why developers are sabotaging their own code”. 2022.↩︎
BIRSAN, Alex. “Dependency Confusion: How I Hacked Into Apple, Microsoft and Dozens of Other Companies”. 2021.↩︎
BERWICK, Flavien. “Top 10 Cloud Technologies Predictions (according to Google VPs), point 2”. 2022.↩︎
GitLab. “Security at GitLab”. about.gitlab.com/handbook/security.↩︎
ARHIRE, Ionut. “Google Boosts Bug Bounty Rewards for Linux Kernel Vulnerabilities”. 2022.↩︎
Le guide de création d’un Open Source Program Office est disponible sur GitHub. github.com/todogroup/ospodefinition.org.↩︎
CLIMENT, Jesus (systems engineer at Google Cloud). Shrinking the time to mitigate production incidents. 2019.↩︎
“A role-playing game for incident management training” : github.com/dastergon/wheel-of-misfortune↩︎
“Fun, gamified, hands-on learning : AWS Gameday”. aws.amazon.com/gameday.↩︎
IDE : Integrated Development Environment. Interface de saisie et de gestion du code. Ex: Visual Studio Code (VSCode), Atom, IDEs JetBrains.↩︎
Sonatype Nexus est une plateforme logicielle pour héberger et gérer ses artéfacts, binaires, paquets et fichiers utilisés dans sa chaîne logicielle. sonatype.com/products/nexus-repository.↩︎
JFrog Artifactory est une plateforme logicielle pour héberger et gérer tous les artéfacts, binaires, paquets, fichiers, conteneurs et composants utilisés dans sa chaîne logicielle. jfrog.com/artifactory.↩︎
Distribution est un logiciel permettant de stocker et distribuer des images de conteneurs. Anciennement “Docker Registry”. github.com/distribution/distribution.↩︎
Forge logicielle développée et hébergée en France. froggit.fr.↩︎
git est un système de “contrôle de version” créé en 2005, traquant les modifications apportées aux fichiers dans un projet (gestion de l’historique des fichiers, de la fusion des contributions, imputabilité des actions). Il est le plus utilisé au monde. Des alternatives historiques et moins populaires existent : Apache Subversion (SVN), Mercurial.↩︎
“Markdown est un langage de balisage léger créé en 2004 par John GRUBER, avec l’aide d’Aaron SWARTZ, dans le but d’offrir une syntaxe facile à lire et à écrire”. Source : fr.wikipedia.org/wiki/Markdown.↩︎
markdown-slides est un outil permettant de créer des présentations à partir de fichiers Markdown. github.com/dadoomer/markdown-slides.↩︎
Slides est un outil permettant de créer des présentations dans un terminal à partir de fichiers Markdown. github.com/maaslalani/slides.↩︎
Remark est un outil permettant de créer des présentations à partir de fichiers Markdown. github.com/gnab/remark.↩︎
Remark est un outil permettant de créer des présentations à partir de fichiers HTML. github.com/hakimel/reveal.js.↩︎
S3 (Amazon S3) est une technologie de stockage de fichiers sous format objets S3 distribuée, créée par Amazon. aws.amazon.com/s3.↩︎
MinIO est une technologie de stockage de fichiers sous format objets S3 distribuée. min.io.↩︎
Hadoop Distributed File System (HDFS) est une technologie de stockage de fichiers distribuée de l’écosystème Hadoop. hadoop.apache.org.↩︎
CephFS est une technologie de stockage de fichiers distribuée. ceph.com.↩︎
Stockage Cloud-native distribué de type “block” pour Kubernetes. longhorn.io.↩︎
Data Version Control (DVC) est un système de versionnage de données massives (ex: modèles d’intelligence artificielle), reposant sur des technologies de stockage Cloud (ex: S3) et permettant d’y faire référence dans un projet git. dvc.org.↩︎
Platform One est une plateforme lancée en 2018 par l’US Air Force permettant la collaboration logicielle dans une démarche DevSecOps, à l’échelle du Ministère des Armées des États-Unis.↩︎
OTAN. The NCI Agency’s Software Factory: a new way to collaborate with industry. 2019.↩︎
IDE : Integrated Development Environment. Interface de saisie et de gestion du code. Ex: Visual Studio Code (VSCode), Atom, IDEs JetBrains.↩︎
HAMMANT, Paul. “Trunk based development: Game changers”. trunkbaseddevelopment.com.↩︎
Projet GitHub de git-flow : github.com/nvie/gitflow.↩︎
“Gitflow has fallen in popularity in favor of trunk-based workflows, which are now considered best practices for modern continuous software development and DevOps practices.” - Atlassian Tutorials (atlassian.com)↩︎
POTVIN, Rachel. “Why Google stores billions of lines of code in a single repository”. 2016.↩︎
MORRIS, Ben. “Why trunk-based development isn’t for everybody”. 2019.↩︎
Scrum.org. “What is Scrum ? A better way to work together and get work done.”. scrum.org.↩︎
Atlassian. “What is Kanban ?”. atlassian.com/agile/kanban.↩︎
Google. “Code Review Developer Guide”. google.github.io/eng-practices/review.↩︎
Illustration en pleine résolution du Flexible Flow. links.berwick.fr/flexible-flow.↩︎
WIGGINS, Adam. The New Heroku (Part 4 of 4): Erosion-resistance & Explicit Contracts. 2011.↩︎
Les sticky sessions ou “affinités de session”, sont une technique utilisée pour de la répartition de charge afin de garantir que les requêtes d’un client soient envoyées en permanence au même serveur au cours d’une session.↩︎
WIGGINS, Adam. “Applying the Unix Process Model to Web Apps”. 2009.↩︎
Google Cloud. DORA 2022 report, chapter “Technical practices and CD”, page 33. 2022.↩︎
GELLER, Anna (Prefect). “What is a Community Engineer in an Open-Source-Product Company”. 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Burnout”, page 40. 2022.↩︎
D. Kuryazov, D. Jabborov and B. Khujamuratov, “Towards Decomposing Monolithic Applications into Microservices” 2020 IEEE 14th International Conference on Application of Information and Communication Technologies (AICT), Tashkent, Uzbekistan, 2020, pp. 1-4, doi: 10.1109/AICT50176.2020.9368571.↩︎
A. B. Raharjo, P. K. Andyartha, W. H. Wijaya, Y. Purwananto, D. Purwitasari and N. Juniarta, “Reliability Evaluation of Microservices and Monolithic Architectures”. 2022 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 2022, pp. 1-7, doi: 10.1109/CENIM56801.2022.10037281.↩︎
Une API (application programming interface) est un ensemble de règles qui permettent à deux applications de communiquer entre elles.↩︎
La fonctionnalité Horizontal Pod Autoscaling de Kubernetes permet d’automatiquement ajuster le nombre de micro-services lancés en fonction de la charge utilisateur.↩︎
Exemples de technologies FaaS : GCP Cloud Functions, AWS Lambda, Azure Functions.↩︎
Exemple de technologies de calcul sans serveur : GCP Cloud Run, AWS Elastic Beanstalk, Azure App Service↩︎
Exemple de technologies de base de données gérées par les hébergeurs Cloud : AWS DynamoDB, GCP Firestore, Azure Cosmos DB, AWS S3↩︎
Exemple de technologies de queues gérées par les hébergeurs Cloud : AWS SQS, GCP Pub/Sub et Azure Service Bus↩︎
L’enfermement propriétaire est une situation où un fournisseur a créé une particularité volontairement non-standard dans le logiciel vendu, empêchant son client de l’utiliser avec les produits d’un autre fournisseur. Cela l’empêche également de modifier le logiciel ou d’accéder à ses caractéristiques pour le modifier. Source : fr.wikipedia.org.↩︎
Amazon Prime Video. Scaling up the Prime Video audio/video monitoring service and reducing costs by 90%. 2023.↩︎
FOWLER, Martin. Microservice prerequisites. 2014.↩︎
DEHGHANI, Zhamak. How to break a Monolith into Microservices. 2018.↩︎
WESTRUM, Ron. “A typology of organisation culture”, doi:10.1136/qshc.2003.009522. 2004.↩︎
Google Cloud. Developing a Google SRE Culture, module 4. coursera.org.↩︎
MALLE, Bertram; GUGLIELMO, Steve; MONROE, Andrew. A Theory of Blame. Psychological Inquiry. 25. 147-186. doi:10.1080/1047840X.2014.877340. 2014.↩︎
UK’s Royal Society for Arts, Manufactures and Commerce. Vidéo “Brené Brown on Blame” sur YouTube. 2015.↩︎
Decision making tools. Mindtools.com.↩︎
Project management tools. Mindtools.com.↩︎
CLET, Étienne; MADERS, Henri-Pierre; LEBLANC, Jérôme; GOLDFARB, Marc. Le métier de chef de projet, Éditions Eyrolles. 2013.↩︎
PIOT, Ludovic; Les Compagnons du DevOps. L’administrateur système DevOps | En Aparté #12, Radio DevOps, à 33 minutes et 30 secondes. 2022.↩︎
Un “persona” est une représentation fictive et détaillée d’un utilisateur cible, créée pour aider les équipes de développement et de gestion de projet à comprendre les besoins, expériences, comportements et intérêts des potentiels clients.↩︎
“(l’outil de RCA CloudRCA) permet aux SRE d’économiser +20% du temps consacré à la résolution de pannes au cours des douze derniers mois et améliore considérablement la fiabilité des services”. ZHANG, Yingying et al. “CloudRCA: A Root Cause Analysis Framework for Cloud Computing Platforms”. 2021.↩︎
Tests pilotes : “type de test logiciel vérifiant tout ou partie d’un système dans des conditions réelles d’exploitation (en production)”. Source : guru99.com↩︎
Google Cloud. Developing a Google SRE Culture, module 3. coursera.org.↩︎
Modèle de postmortem à retrouver sur atlassian.com/incident-management/postmortem/templates↩︎
Excelsior. Vidéo YouTube “Le Canap’ - Ui designer, youtubeur et streamer : Basti UI lance le « télétralive »”. 2022.↩︎
BERGGREN, Erik; BERNSHTEYN, Rob. “Organizational transparency drives company performance”. Journal of management development 26, no. 5 411-417. 2007.↩︎
Blog où Cloudflare publie ses postmortems : blog.cloudflare.com/tag/postmortem↩︎
STAMBLER, Kimberly S; BARBERA, Joseph A. “Engineering the Incident Command and Multiagency Coordination Systems” Journal of Homeland Security and Emergency Management 8, no. 1. 2011.↩︎
Google. Chapitre “Incident Command System”, SRE Book. sre.google.↩︎
Datadog. 2023-03-08 Incident: A deep dive into our incident response. 2023.↩︎
Yann COUDERC. “Sun Tzu a-t-il inventé les cas non conformes ?”. 2013.↩︎
US Department of Defense. “MIL-P-1629 – Procedures for performing a failure mode effect and critical analysis. Department of Defense (US). MIL-P-1629”. 1949.↩︎
STEPHEN, Elliot. “DevOps and the cost of downtime: Fortune 1000 best practice metrics quantified”, International Data Corporation (IDC). 2014.↩︎
Histoire du développement de Windows NT : en.wikipedia.org/wiki/Windows_NT_3.1↩︎
“Le no-code est une approche du développement de logiciels permettant de créer et de déployer des logiciels sans écrire de code informatique”. Source : fr.wikipedia.org.↩︎
PAUPIER, François; CHAILLAN, Nicolas. Postmortem #19 : Le DevSecOps à l’US Air Force. 2022.↩︎
SIEBEN, Inge. “Does training trigger turnover - or not?: The impact of formal training on graduates’ job search behaviour. Work, Employment and Society”. 2007.↩︎
Im, GHI PAUL; Richard, L. BASKERVILLE. “A longitudinal study of information system threat categories: the enduring problem of human error.” ACM SIGMIS Database: the DATABASE for Advances in Information Systems 36.4 (2005): 68-79. 2005.↩︎
Projet GitHub disponible à links.berwick.fr/todevops-2↩︎
CUNLIFFE, Stuart. Illustration de l’article “Red Hat Ansible: A 101 guide”, ibm.com/blogs. 2020.↩︎
WIGGINS, Adam. The New Heroku (Part 4 of 4): Erosion-resistance & Explicit Contracts. 2011.↩︎
Basé sur le livre de Kent BECK. Test-Driven Development by Example. 2002.↩︎
Dogša, T., Batič, D. “The effectiveness of test-driven development: an industrial case study”. Software Qual J 19, 643–661, doi:10.1007/s11219-011-9130-2. 2011.↩︎
Le TDD réduit de 31% la complexité et augmente de 21% la qualité du code, par rapport au TLD : KHANAM, Z; AHSAN, MN. Evaluating the effectiveness of test driven development: Advantages and pitfalls. International Journal of Applied Engineering Research. 2017.↩︎
Atlassian. “What is code coverage ?”. atlassian.com.↩︎
MOE, Myint Myint. “Comparative Study of Test-Driven Development TDD, Behavior-Driven Development BDD and Acceptance Test–Driven Development ATDD”. International Journal of Trend in Scientific Research and Development. 2019.↩︎
Scripts qui analysent le code source pour signaler les erreurs de programmation, les bugs, les erreurs stylistiques et les constructions suspectes de code. L’objectif du linting est d’imposer un style de code cohérent et de trouver des erreurs potentielles avant l’exécution du code.↩︎
Istio’s testing framework documentation on github.com. 2022.↩︎
SRIDHARAN, Cindy. “Distributed Systems Observability”. 2018.↩︎
ANSSI. “Recommandations de sécurité pour l’architecture d’un système de journalisation” version 2, Annexe D : aspects juridiques et réglementaires. 2022.↩︎
Grâce à son service mesh, Lyft a réécrit les entêtes des requêtes qui passent dans son réseau pour ajouter ou propager les informations de traçage.↩︎
RELP (Reliable Event Logging Protocol ou protocole fiable de journalisation d’évènements en français) est un protocole développé pour avoir l’assurance qu’un log émis est bien arrivé à destination. Source : connect.ed-diamond.com.↩︎
“OpenTelemetry définit des conventions sémantiques […] qui spécifient des noms communs pour différents types d’opérations et de données.”. Source : opentelemetry.io.↩︎
Search Engine Optimization : Techniques d’optimisation visant améliorer son site web pour qu’il remonte dans les résultats de recherche.↩︎
Le taux de fonctionnement (uptime) est le temps pendant lequel le service est allumé sur une période donnée. La disponibilité (availability) indique si le service est accessible et retourne des réponses valides. Par exemple, une API peut être démarrée (uptime) sans être disponible pour retourner une réponse valide (availability; service inaccessible, saturé ou erreurs HTTP 500 intempestives).↩︎
Google. Chapitre “Service Level Objectives”, SRE Book. sre.google.↩︎
Istio Dashboard documentation. istio.io.↩︎
Istio access logs documentation. istio.io.↩︎
Istio Distributed traces documentation. istio.io.↩︎
Weaveworks. Introduction to Kubernetes Service Mesh. 2019.↩︎
Site officiel du projet Buoyant Linkerd : linkerd.io.↩︎
Site officiel du projet Hashicorp Consul : consul.io.↩︎
Custom Resource Definition (CRD) : mécanisme permettant d’ajouter des extensions de fonctionnalités au sein d’un cluster Kubernetes.↩︎
Helm est une technologie standardisant et simplifiant le déploiement d’applicatifs dans Kubernetes. helm.sh.↩︎
Le terme “Cloud Native” fait référence à une application qui a été conçue dès le départ pour être exploitée dans le Cloud. Les projets Cloud Native impliquent des technologies Cloud telles que les micro-services, les orchestrateurs de conteneurs et le passage à l’échelle automatique.↩︎
Sealed Secrets permet de manipuler des secrets sans pouvoir accéder à leur contenu en clair, permettant d’aller jusqu’à “pousser” un secret. Un certificat de sécurité gère le déchiffrement de ces secrets au sein du cluster Kubernetes. Projet GitHub : github.com/bitnami-labs/sealed-secrets.↩︎
GAFAM : Grandes entreprise technologiques américaines (Google, Facebook, Amazon, Apple, Microsoft). Synonymes : FAANG, NATU, MAMMA, MANAMANA.↩︎
Page web officielle du projet : 10pourcent.etalab.gouv.fr↩︎
Google commence à rembourser ses clients Google Workspace en dessous de 99.9% de disponibilité. workspace.google.com/terms/sla.html.↩︎
AWS instance-level SLA. Les premiers remboursement commencent à 99.5% de disponibiligé. aws.amazon.com/compute/sla.↩︎
Procter & Gamble Co. 2021 Form 10-K, chapitre Property, Plant and Equipment. 2021. <+> SPINELLIS, Diomidis; LOURIDAS, Panos; KECHAGIA, Maria. Software evolution: the lifetime of fine-grained elements. 2021.↩︎
Agence Nationale de la Sécurité des Systèmes d’Information↩︎
POORTVLIET, Jos. German Federal Administration relies on Nextcloud as a secure file exchange solution. 2018.↩︎
POORTVLIET, Jos. EU governments choose independence from US cloud providers with Nextcloud. 2019.↩︎
Google Cloud. DORA 2022 report, chapter “Technical DevOps Capabilities”, page 30. 2022.↩︎
Google Cloud DORA’s 4 key metrics for measuring DevOps performances.↩︎
SMITH, Dustin (DORA Research Lead). “2021 Accelerate State of DevOps report addresses burnout, team performance”. 2021.↩︎
Historical Service Level Availability : about.gitlab.com/handbook/engineering/monitoring↩︎
Vidéo de la chaîne Platform Engineering sur YouTube. Palantir’s GitOps Journey with Apollo, avec Greg DeArment. 2022.↩︎
Palantir. Palantir Apollo Whitepaper. 2022.↩︎
Blog Palantir sur medium.com. Why Traditional Approaches to Continuous Deployment Don’t Work Today. 2022.↩︎
Palantir (blog.palantir.com). “Palantir Apollo Orchestration: Constraint-Based Continuous Deployment For Modern Architectures”. 2022.↩︎
En 2021, 74% des organisations déclaraient adopter une approche DevOps. Statistiques par Redgate. “The 2021 State of Database DevOps”. 2021.↩︎
DevOps Institute. Global Upskilling IT report, chapitre “Industry” (page 162). 2022.↩︎
Au sens des catégories d’entreprises françaises définies par l’INSEE. 2020.↩︎
DevOps Institute. Global Upskilling IT report, chapitre “DevOps Remains a Driving Force in IT Transformation” (page 16). 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Region”, page 63. 2022.↩︎
Google Cloud. DORA 2022 report, chapter “Team size”, page 65. 2022.↩︎
KREUZBERGER, Dominik; KÜHL, Niklas; HIRSCHL, Sebastian. MLOps: Overview, Definition, and Architecture. 2022.↩︎
git est un système de “contrôle de version” créé en 2005, traquant les modifications apportées aux fichiers dans un projet (gestion de l’historique des fichiers, de la fusion des contributions, imputabilité des actions). Il est le plus utilisé au monde. Des alternatives historiques et moins populaires existent : Apache Subversion (SVN), Mercurial.↩︎
18 DataOps principles of The DataOps Manifesto.↩︎
CAPIZZI, Antonio; DISTEFANO, Salvatore; MAZZARA, Manuel. From DevOps to DevDataOps. 2019.↩︎
Google Cloud. DORA 2022 report, chapter “Years of experience”, page 61. 2022.↩︎
Dans l’administration, en 2023, le niveau de diplôme définit encore aujourd’hui la catégorie, le grade et le niveau de rémunération.↩︎
Disaster and Recovery Testing (DiRT) est un entraînement des équipes d’infrastructure chez Google, visant pousser les systèmes de production à leur limite et infliger des pannes réelles. L’objectif est de voir comment les équipes réagissent et si elles sont correctement outillées pour répondre à un incident.↩︎
Supply chain Levels for Software Artifacts (SLSA, prononcé “salsa”) est un ensemble de règles de sécurité recommandées pour sécuriser sa chaîne de développement et de déploiement logiciel.↩︎
Page de présentation du “Master sécurité numérique” de l’ANSSI. ssi.gouv.fr (onglet “Formations”).↩︎